blog
Automating Day 2 operations: Scaling, upgrades and maintenance

The first launch of your database is not the end; it is the beginning of Day-2 operations. Day-2 operations include critical, ongoing tasks such as rolling upgrades, patching, capacity scaling, and continuous performance tuning. These tasks are essential to ensure high availability, security, and performance of your production environments. Manual execution of Day-2 operations by DBAs and operators can waste time, introduce risk, and limit agility.
This post will explore the significance of automating Day-2 operations and how to achieve cloud-like efficiency and near-zero downtime, even in on-premises or hybrid environments.
DIY vs. Automated Approaches: Why Manual Operations Fall Short
Many teams still rely on manual scripts or piecemeal solutions to manage Day-2 tasks, leading to a variety of challenges. Manual processes don’t scale effectively. As the complexity and demands of the system grow, manual operations become increasingly time-consuming, error-prone, and unsustainable. Critical information like rolling upgrade scripts, scaling instructions, and performance tuning checklists is often shared informally through channels like Slack or stored in internal wikis, making them challenging to locate and access when needed.
Manual operations are inherently prone to human error. A simple mistake during an upgrade can lead to an outage, causing significant downtime and service disruption. When upgrades or scaling efforts aren’t coordinated or tested in a live environment, the risk of downtime increases. Unexpected issues can arise, leading to service interruptions and frustrated users. Inconsistent processes and manual interventions mean teams can’t respond quickly to performance dips or traffic surges. This can result in degraded service quality and SLA breaches.
For teams operating critical, always-on databases, relying on manual processes for Day-2 operations is unsustainable. The risks are too high, and the potential for service disruption is too great.
Automating Day-2 with ClusterControl: Smarter Operations, Less Risk
ClusterControl takes the guesswork and risks out of Day-2 operations with built-in automation designed for production environments. Here’s how:
1. Rolling Upgrades with Pre and Post-Checks
ClusterControl facilitates a more efficient upgrade process by eliminating reliance on manual scripting, thereby minimizing the potential for errors. Automated rolling upgrades incorporate rigorous pre-flight validation checks to assess the environment and database status before initiating the upgrade. This proactive methodology aids in identifying and mitigating potential issues, preventing downtime or data loss.
For instance, a PostgreSQL replication major version upgrade procedure requires upgrading all replicas and finalizing by the primary node. It also requires pre-checking on the existing database collation, character sets, server encoding, data checksum, old and new data directory location, and many more which are embedded in the logic of ClusterControl upgrade procedures. Upon completion, a consistency check is performed, as shown in the screenshot below:
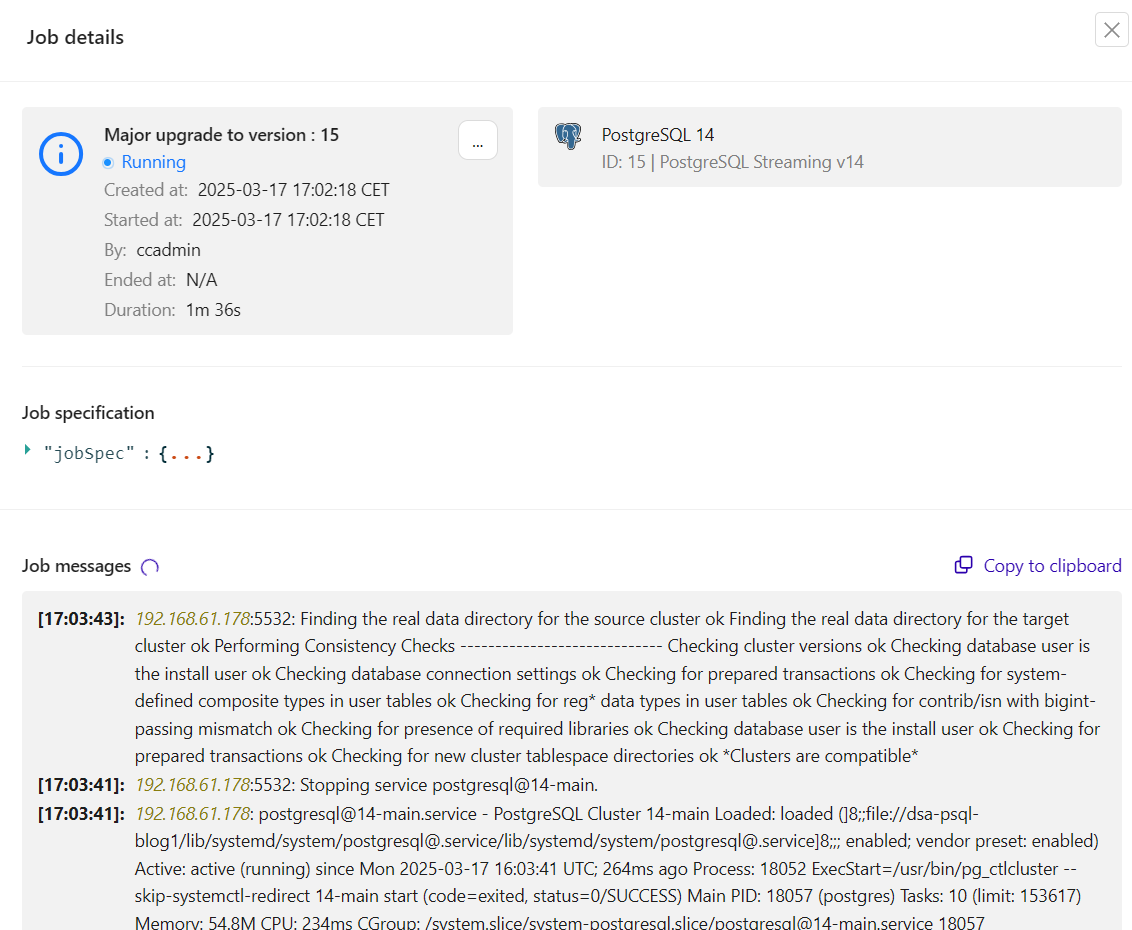
The platform provides versatility, offering expedited one-click upgrades for straightforward scenarios and fully orchestrated, minimal-downtime rolling procedures for intricate, clustered database environments.
For other databases, minor upgrades can be performed similarly, with a single click, including upgrading the load balancer software in a rolling fashion. If the upgrade process fails midway, ClusterControl will abort the upgrade task immediately, and the administrator can restore or rebuild the database node again from the existing replica by using the “Rebuild Replica” or “Resync Node” feature (cluster dependent). This allows you to roll back the database to its original version without much hassle.
Even though it wouldn’t be an automated process, it can assist in running major upgrade workflows for the other databases by allowing you to easily see the database nodes’ software version during the upgrade, which is especially useful if you have many nodes in a cluster. Also, if using CC to manage the load balancer, you can use its LB’s web GUI to re-route the traffic easily, e.g., excluding the upgrading node from receiving connections while upgrading, etc.
2. Integrated Scalability Automation
ClusterControl simplifies horizontal scalability to accommodate fluctuating workloads and business requirements. Cloning clusters, setting up a geographically distributed replication a.k.a replica cluster, adding more database nodes, adding more replicas, and adding more load balancer nodes are some of the built-in scaling capabilities of ClusterControl to manage increased traffic and maintain optimal performance without almost zero manual intervention.
The ability to instantly understand your database topology, pinpoint issues, and plan actions like scaling or failover is critical for operators and DBAs. ClusterControl provides a real-time, interactive, and actionable topology visualization, as shown in the screenshot below:
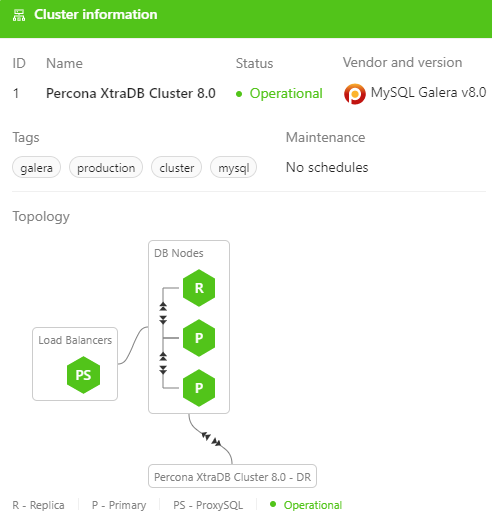
You can easily see that there are two clusters, “Percona XtraDB Cluster 8.0” is connected to another cluster called “Percona XtraDB Cluster 8.0 – DR” in a bi-directional replication, represented by the double-headed arrow connector, right after a horizontal scaling operation. The topology viewer reflects on the topology changes in real-time and supports all known database cluster and replication topologies, together with load balancers’ and virtual IP address topologies.
3. Performance Tuning & Continuous Optimization
ClusterControl conducts continuous health assessments and performance monitoring to identify and rectify performance anomalies before user impact. The platform offers automated analytical insights for query optimization and resource adjustments, grounded in real-time performance data and historical trends.
ClusterControl provides proactive alerts and actionable guidance, enabling teams to respond rapidly and effectively to performance anomalies. This approach sustains optimal database performance and ensures a positive user experience. This picture shows the Query Monitor interface for a MySQL database in a cluster:
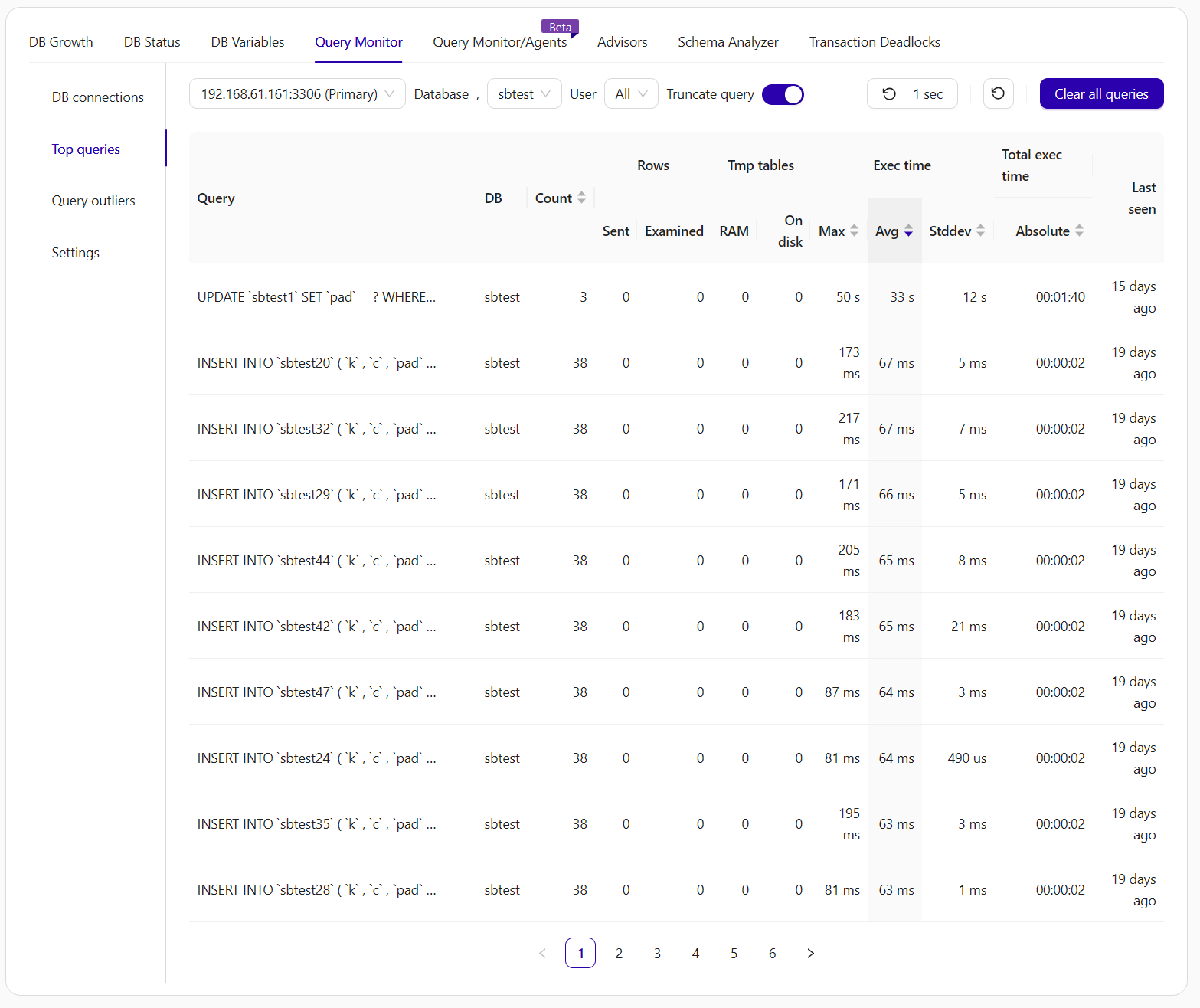
The page quickly shows the most frequent or time-consuming queries, which allows you to see where you might need to optimize or conduct additional troubleshooting.
ClusterControl provides automated notifications (called Advisors) regarding recommended scaling actions based on real-time performance metrics and predictive analytics. This proactive strategy enables the anticipation and resolution of capacity issues before user or application impact. The following advisors produced by ClusterControl show some warnings about host and database-related performance:
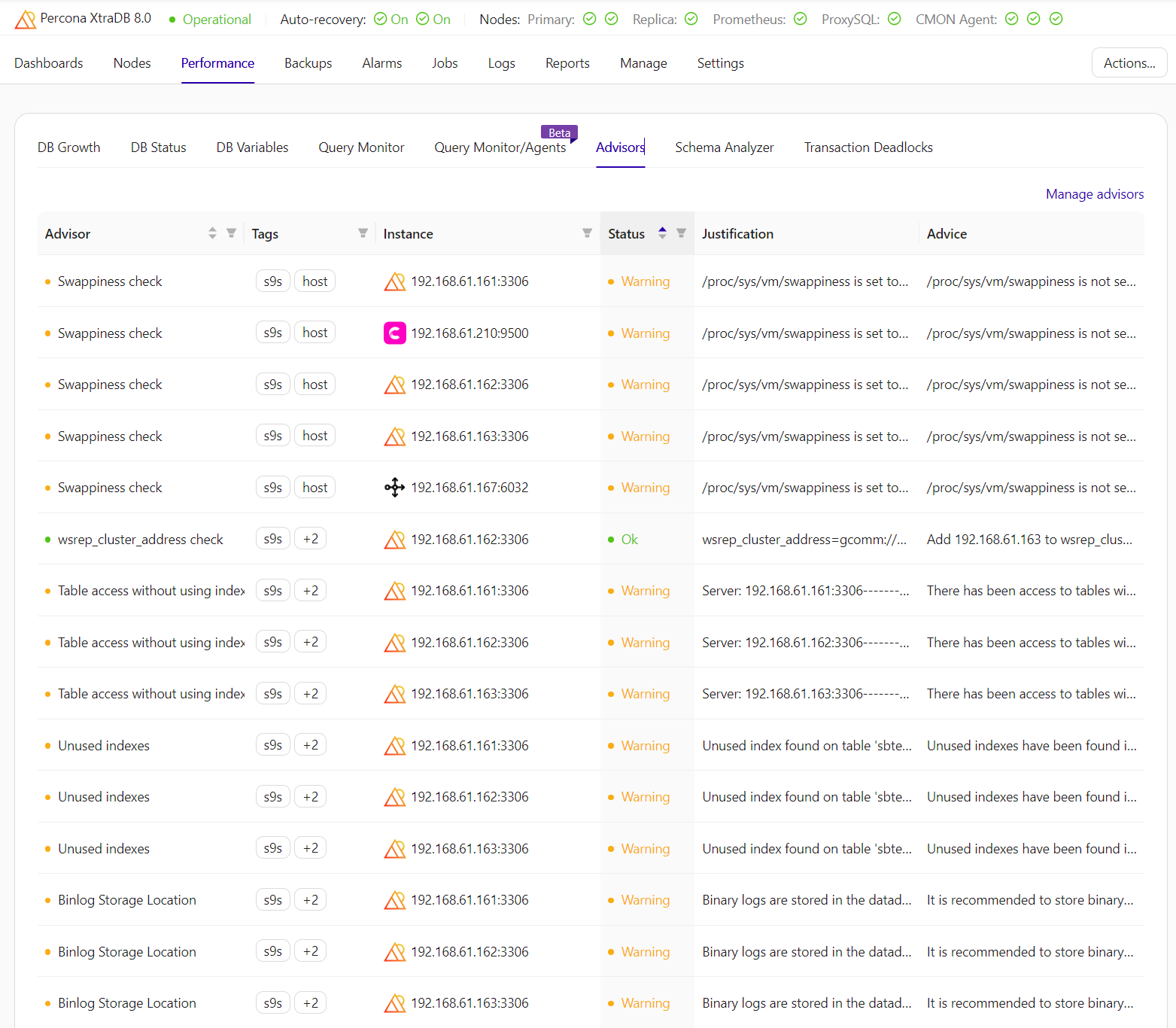
The screenshot shows ClusterControl’s advisor or analysis interface listing various configuration and security checks for a Percona XtraDB (MySQL Galera) cluster. Each warning pinpoints a specific area that may need attention, often relating to OS parameters, MySQL settings, or database user accounts, along with a short rationale for why it’s flagged and what you might want to do about it.
4. Data Recovery Management
Backup and Recovery Management is a critical component of Day-2 operations, and ClusterControl simplifies this process by providing robust tools to automate, schedule, and monitor backups. With ClusterControl, DBAs can define comprehensive backup policies tailored to the specific needs of their database clusters.
The platform supports various backup strategies—from full and incremental backups to point-in-time recovery—ensuring that data is securely preserved and quickly restored during hardware failure, software issues, or accidental data loss. Its intuitive interface allows for easy scheduling of backup jobs during off-peak hours, minimizing disruption to production workloads while maintaining a high level of data integrity.
ClusterControl’s backup verification feature is designed to ensure that your backup files are not only created but are also valid and ready for a successful restore when needed. Once a backup job is completed, ClusterControl automatically initiates a verification process that examines the backup file’s integrity and completeness. This process often involves calculating checksums and comparing them with expected values, as well as validating that the backup contains all necessary data and metadata. This automated verification helps catch issues such as file corruption or incomplete backups before they can impact recovery operations.
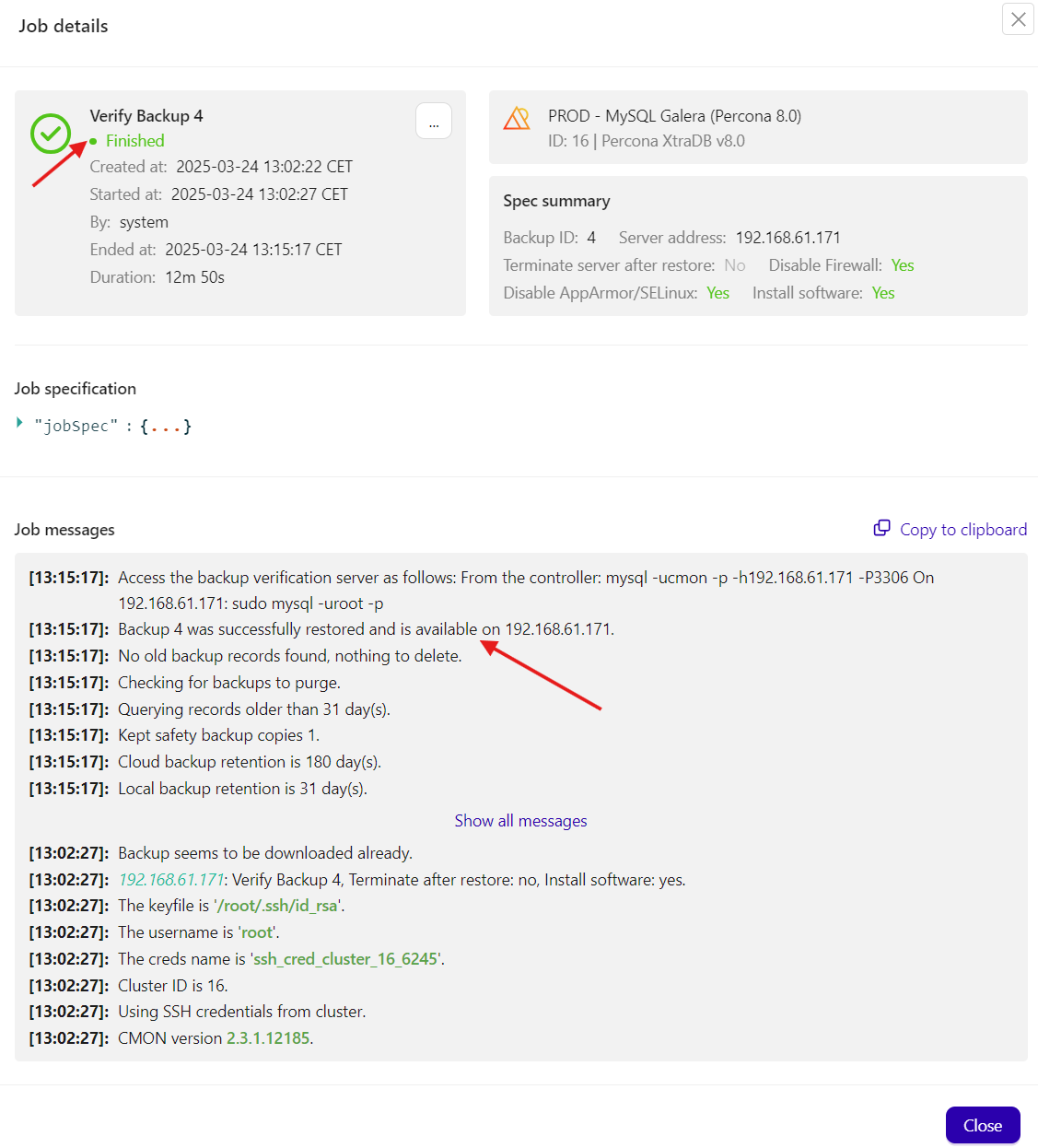
In practice, the verification process is integrated directly into the backup workflow. DBAs receive real-time notifications and can review detailed logs if any discrepancies or errors are detected. This transparency allows for proactive troubleshooting – DBAs can re-run backup jobs or address issues with storage or network connectivity promptly. By incorporating a rigorous backup verification step, ClusterControl not only safeguards your data but also builds confidence in the restore process, ensuring that your disaster recovery strategy is both reliable and effective.
In addition to scheduled backups, ClusterControl offers powerful recovery management features that streamline the restoration process. Automated recovery procedures, along with detailed logs and real-time notifications, ensure that DBAs can promptly identify issues and initiate the appropriate recovery actions.
Administrators can also restore the database backups on an existing cluster, another database host (for verification or staging), or another new set of database clusters for scaling or cloning purposes. The tool’s integration with various storage solutions and support for multi-cloud environments further enhances its flexibility, making it a reliable solution for businesses of all sizes.
Wrapping up
By automating post-deployment operations, ClusterControl facilitates risk mitigation, improved efficiency, and optimal database performance for databases deployed in on-premises and hybrid environments. This enables organizations to reduce SLA risk and concentrate on innovation and value delivery, rather than manually carrying out routine, error prone maintenance tasks.
There are both free and proprietary tools to help you handle Day 2 ops; but, they are often mono-environment and -database, not to mention that they present their own manual work. If you’re interested in a platform that handles the full operational lifecycle in any environment, try ClusterControl free for 30-days. Not ready? Try out our open demo environment.
Otherwise, make sure you follow us on LinkedIn or X or sign up for our monthly newsletter to stay up-to-date with database, operations, and Sovereign DBaaS -related news.



