blog
Automating Backups and Disaster Recovery in PostgreSQL at Scale: pgBackRest vs. Barman

The importance of Disaster Recovery (DR) strategies, especially for your core RDBMs workloads, cannot be overstated in today’s always on world. That’s why it’s important to have a well designed strategy to ensure that data can consistently be restored quickly with minimal business disruption. This is where concepts like Recovery Point Objective (RPO) and Recovery Time Objective (RTO) come into play.
Your RPO defines how much data you are willing to lose in case of failure. For example, if it is 10 minutes, you need backup or replication mechanisms that ensure no more than 10 minutes of data is lost. Meanwhile, the RTO defines how quickly you must restore operations after a failure. For example, a 30 minute RTO means your systems should be back up within half an hour, regardless of incident severity.
In the PostgreSQL ecosystem, there are a lot of open-source backup tools; pgBackRest and Barman are widely trusted to implement robust backup and disaster recovery strategies in production environments.
In this post, we’ll look at PostgreSQL and compare and contrast two of its backup tools that help effectuate PG-based DR strategies, pgBackRest and Barman (Backup and Recovery Manager) — we’ll review their architectures, installation nuances, performance, manual vs. ClusterControl management, and more.
pgBackRest and Barman Architectures
pgBackRest uses built-in compression algorithms (lz4, zstd, gzip) and transparent support for client-side or server-side encryption. pgBackRest is very flexible when it comes to backup repositories and is designed for both on-premises, e.g. local disk, NFS / Network File Storage, SAN /Storage Area Network, and cloud-native environments, e.g., AWS S3, Google Cloud Storage, MinIO, or S3-compatible vendors.
Meanwhile, Barman supports compression gzip (default), bzip2, lz4 and is designed to perform remote, centralized backups of multiple PostgreSQL servers, integrating neatly with WAL archiving and PITR.
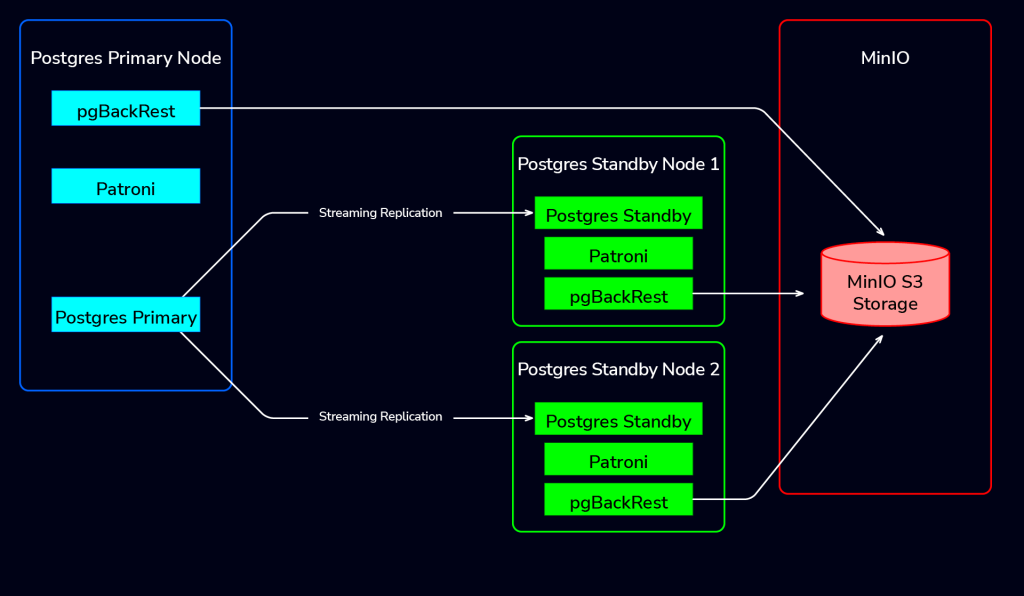
Each database node has pgBackRest installed, but it is not a continuously running service that automatically coordinates backups. Instead, backups are initiated from a chosen node (usually the primary or a standby) based on how the system is configured.
A pgbackrest.conf configuration file must exist on each database node, and is typically the same across all nodes, except for minor differences; e.g., the repository host may not require repo1-host settings if the repo is local.
In addition to this distributed setup, pgBackRest also supports using a dedicated backup repository server, where backups and archived WAL files are stored separately from the database nodes. This is the recommended production setup for improved isolation and reliability.
Barman Architecture
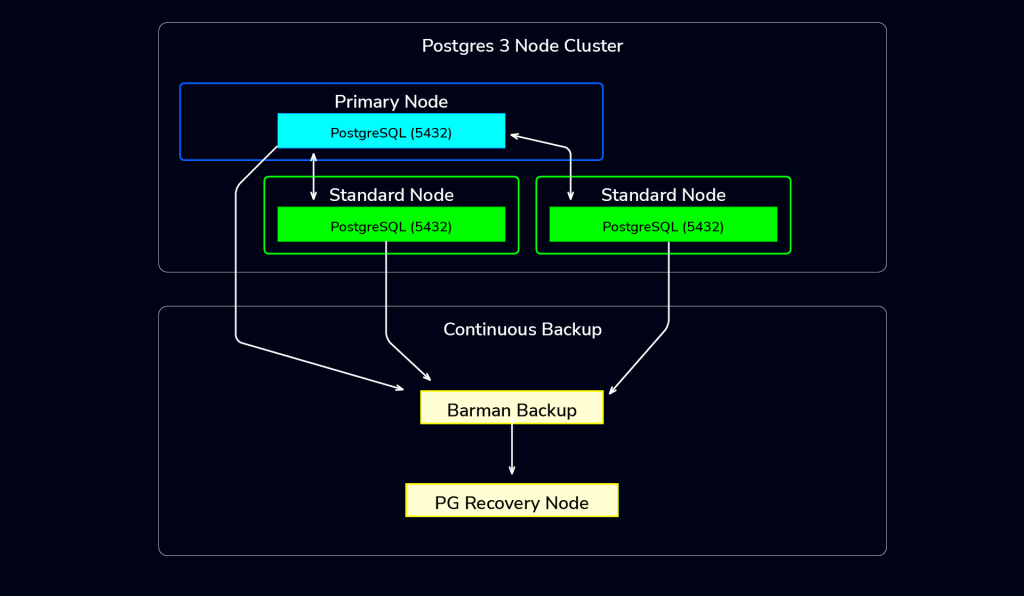
Barman runs on dedicated servers that trigger and coordinate backup operations on the database nodes. To enable this, a backup user with the REPLICATION role must be created in PostgreSQL. Since Barman depends on SSH for communication, passwordless SSH authentication should also be configured.
Installing pgbackrest and Barman
Installing and configuring pgbackrest
The installation of pgbackrest can be from official repositories, for example the installation of pgbackrest in Redhat/CentOS based linux:
Packages installation
$ dnf install make gcc postgresql-devel openssl-devel libxml2-devel lz4-devel libzstd-devel bzip2-devel libyaml-devel
$ dnf install pgbackrestVerify if the pgbackrest package exists.
pgbackrest versionThere are many configuration parameters inside pgbackrest.conf. It can be categorized such as:
Global configuration
[global]
# Log level (detail, info, warn, error)
log-level-console=info
log-level-file=debug
log-path=/var/log/pgbackrestBackup repository path
# Where backups will be stored (repo1 = local, repo2 = cloud)
repo1-path=/var/lib/pgbackrest/repo1
repo1-retention-full=4 # Keep last 4 full backups
repo1-retention-diff=7 # Keep 7 differential backups
repo1-retention-archive=14 # Keep 14 days of WAL logs
compress-type=zstd # Compression: lz4, zstd, gzip
compress-level=3 # Adjust speed vs size
Secondary repository S3 path
# Second repository: AWS S3 (can also be MinIO, Wasabi, etc.)
repo2-type=s3
repo2-path=/pgbackrest/repo2
repo2-s3-bucket=mycompany-pgsql-backups
repo2-s3-endpoint=s3.amazonaws.com
repo2-s3-region=us-east-1
repo2-s3-key=myaccesskey
repo2-s3-key-secret=mysecretkey
repo2-retention-full=2 # Keep 2 full backups in cloudPostgreSQL cluster definition (pg1-path, pg1-port)
########################################
# Stanza: PostgreSQL Cluster Definition
########################################
[pg-main]
pg1-path=/var/lib/postgresql/15/main # PostgreSQL data directory
pg1-port=5432
pg1-socket-path=/var/run/postgresqlCreate users, dirs & permissions, configure SSH passwordless between the nodes(don’t forget to include the repository if you have dedicated). Configure stanza and archiving in postgresql configuration:
$ sudo -u postgres pgbackrest --stanza=prod stanza-create
$ vi /var/lib/pgsql/15/main/postgresql.conf
archive_command = 'pgbackrest --stanza=prod archive-push %p'Run the backup and validate:
# Full backup
$ sudo -u postgres pgbackrest --stanza=prod --type=full backup
# Validate
$ sudo -u postgres pgbackrest --stanza=prod check
$ sudo -u postgres pgbackrest --stanza=prod infoInstalling and configuring Barman
Installing Barman requires a dedicated server and the installation of its packages.
#Barman Server
$ dnf install barman barman-cli
$ barman --version
#DB Server
$ dnf install -y postgresql16-server rsyncEnable archiving in the database and whitelist the connection in pg_hba.conf
Create the barman user and set up the SSH passwordless from Barman to the PostgreSQL database.
-- psql on pg1 as superuser
CREATE ROLE barman WITH LOGIN REPLICATION PASSWORD 'strongpass';
GRANT pg_read_all_settings, pg_read_all_stats TO barman;sudo -u barman -H bash -lc 'ssh-keygen -t ed25519 -N "" -f ~/.ssh/id_ed25519'
sudo -u barman -H bash -lc 'ssh-copy-id -i ~/.ssh/id_ed25519.pub postgres@pg1'Barman configuration:
# Create directories
sudo mkdir -p /var/lib/barman
sudo chown -R barman:barman /var/lib/barman
sudo chmod 750 /var/lib/barman
# Barman Global Configuration
$ vi /etc/barman.conf
[barman]
barman_user = barman
configuration_files_directory = /etc/barman.d
log_file = /var/log/barman/barman.log
# housekeeping
retention_policy = RECOVERY WINDOW OF 30 DAYS
retention_policy_mode = auto
immediate_checkpoint = true
# Server Configuration
$ vi /etc/barman.d/pg1.conf
[pg1]
description = Production primary
# Connection string for PostgreSQL
conninfo = host=pg1 port=5432 user=barman dbname=postgres password=strongpass
# How to run commands on the DB host (for rsync/recover/etc.)
ssh_command = ssh postgres@pg1
# Backup method (pg_basebackup) and streaming WAL
backup_method = postgres # uses pg_basebackup
streaming_archiver = on # runs pg_receivewal from barman
slot_name = barman_pg1 # dedicated replication slot for WAL
create_slot = auto
# Optional: also accept archive_command pushes
archiver = on
incoming_wals_directory = /var/lib/barman/pg1/incomingBarman check:
sudo -u barman barman check pg1
sudo -u barman barman show-server pg1pgBackRest and Barman performance and throughput
In terms of performance and throughput, pgBackRest supports parallel jobs for both backup and restore operations, especially for larger, high-throughput environments, reducing backup windows and recovery time. However, that speed at scale comes at a cost. Barman is simpler but can be less efficient in larger, high-throughput clusters. However, it integrates neatly with streaming replication for WAL archiving.
Manual implementation vs. ClusterControl: Pros & Cons
When pgBackRest or Barman is managed manually, sysadmins or DBAs are responsible for installation, configuration, scheduling, monitoring, and testing restores. This typically involves installing the backup tools, defining backup configurations, setting up repositories, and maintaining them over time.
Manual Backup Management
- Pros: In terms of flexibility, you design the backup policy and scripts to fit your specific environment, also easy to tweak cron jobs, custom retention rules, or special restore procedures. There is no software dependency, everything is native to PostgreSQL and open-source.
- Cons: Complexity increases with scale because managing backups across dozens of servers requires significant coordination. Higher risk of human error, there is potentially misconfigured cron job could result in missing backups or failed restores.
Using ClusterControl for backup management
ClusterControl automates PostgreSQL operations, including backup and restore management. Currently, ClusterControl supports pgBackRest as a PITR backup solution.
- Pros: Central scheduling, retention policies, consolidated restore workflows, integration with cloud storage, monitoring and alerting for the backup.
- Cons: Another tool to maintain, potential licensing cost.
Standard backup operations: scheduling, retention, encryption, cloud storage, and testing
An effective Disaster Recovery plan is not just about taking backups but also about scheduling and configuring appropriate retention policies, safeguarding their contents through encryption, and ensuring their recoverability by distributing their storage and testing them. Without automation, teams risk having outdated or incomplete recovery workflows — let’s look at these key operations in light of ClusterControl.
Scheduling a pgBackRest backup in ClusterControl
Below is the architecture of the pgbackrest backup using ClusterControl.
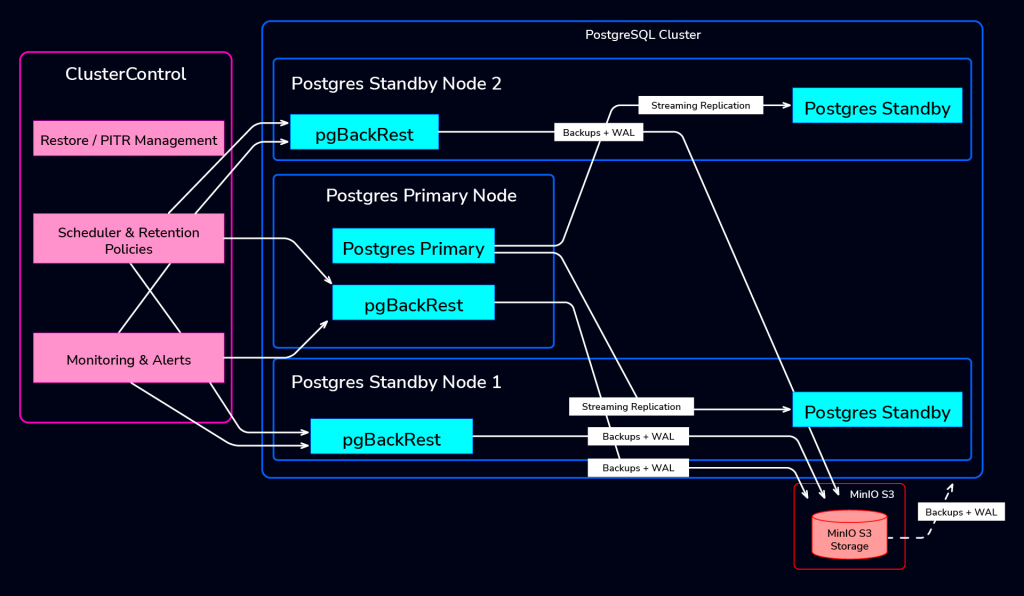
ClusterControl handles backup scheduling for both full and incremental backups. It continuously monitors the backup process, providing clear status reports on successes or failures. Beyond that, it also manages historical backups and applies retention policies to ensure efficient storage usage.
Scheduling a pgbackrest backup is straightforward — go to Backups and click the button Create backup.
Choose Schedule a Backup as shown below:
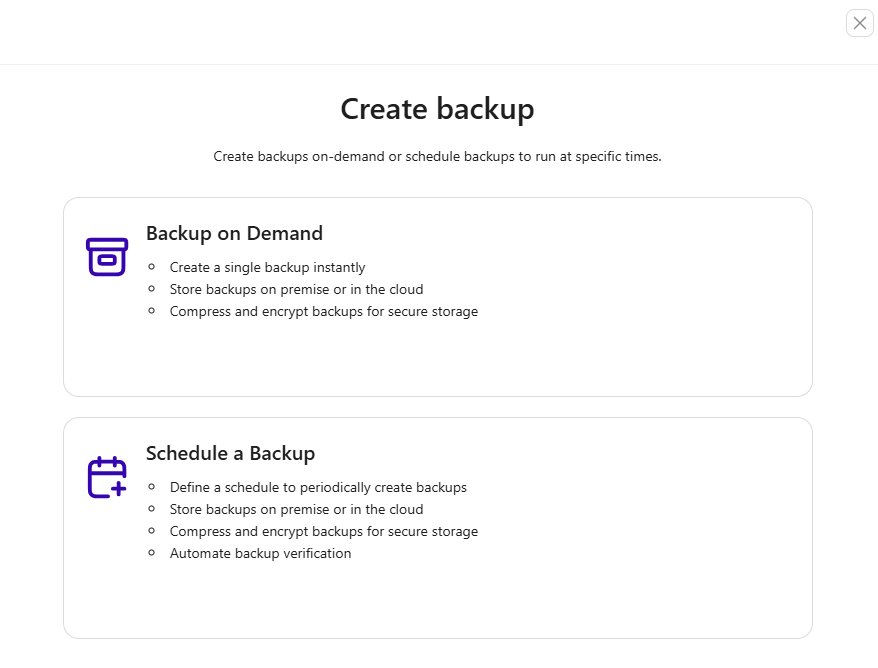
When configuring, enter the schedule name and select the backup method. In the right panel, you’ll see the option to install pgBackRest. Click Continue to complete the installation of the backup tool.
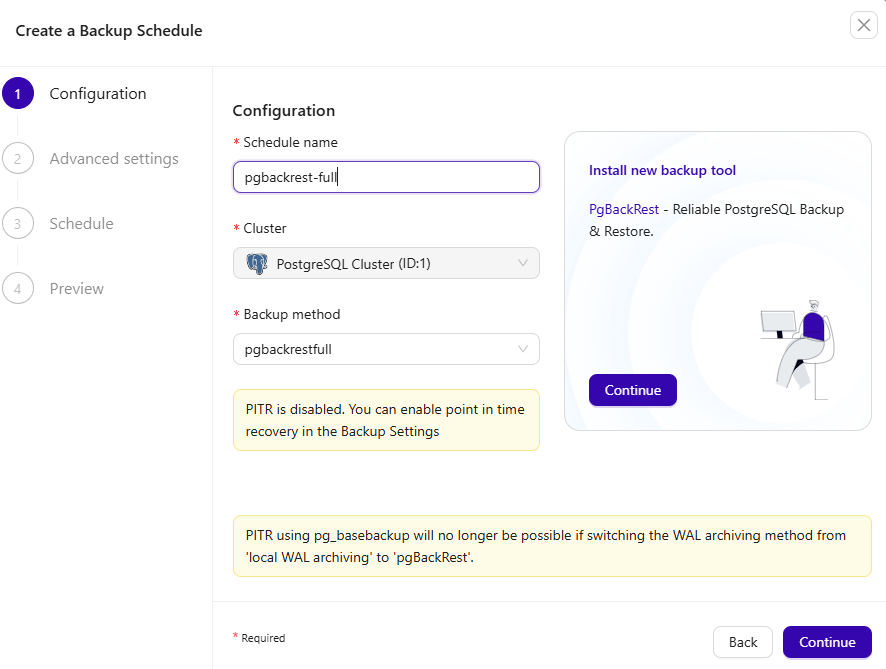
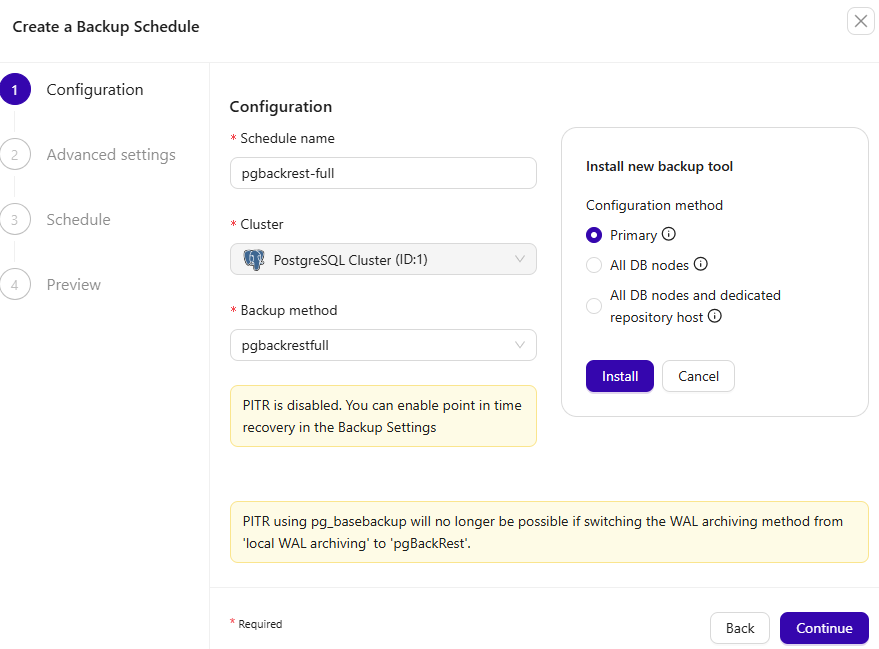
Select the installation target: Primary node, all database nodes, or all database nodes plus a dedicated repository host.
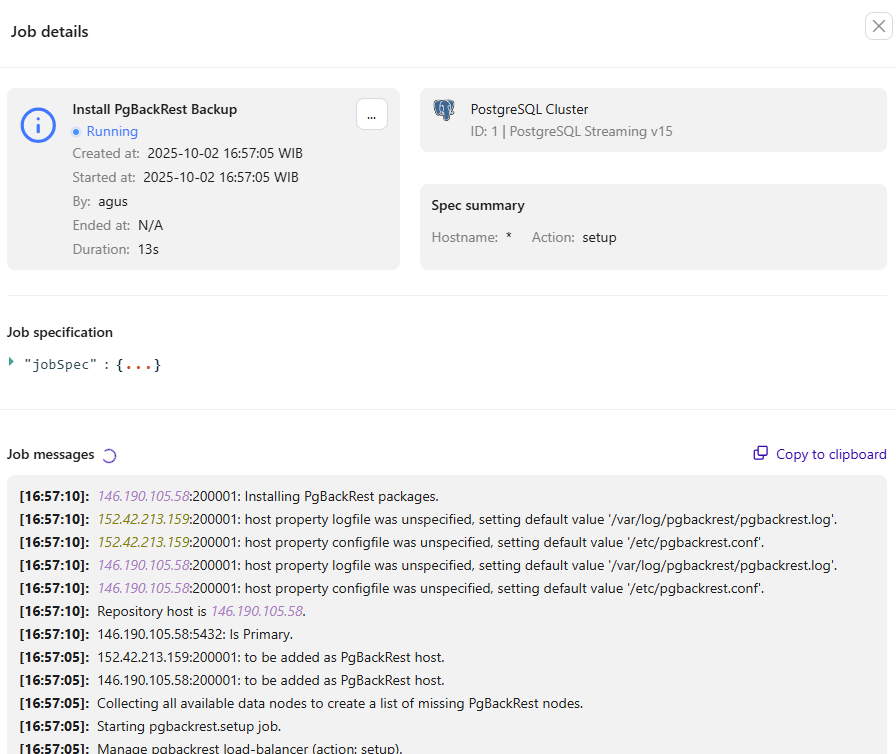
ClusterControl will display the job activity for the pgBackRest backup installation.
After the installation of pgBackRest tools finished, continue setting up the backup schedule.
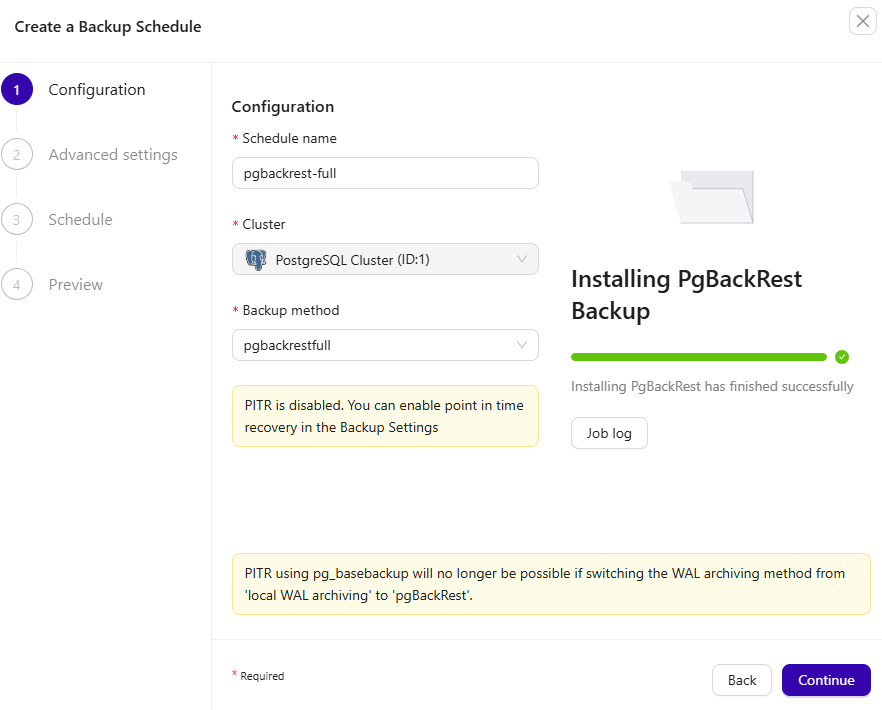
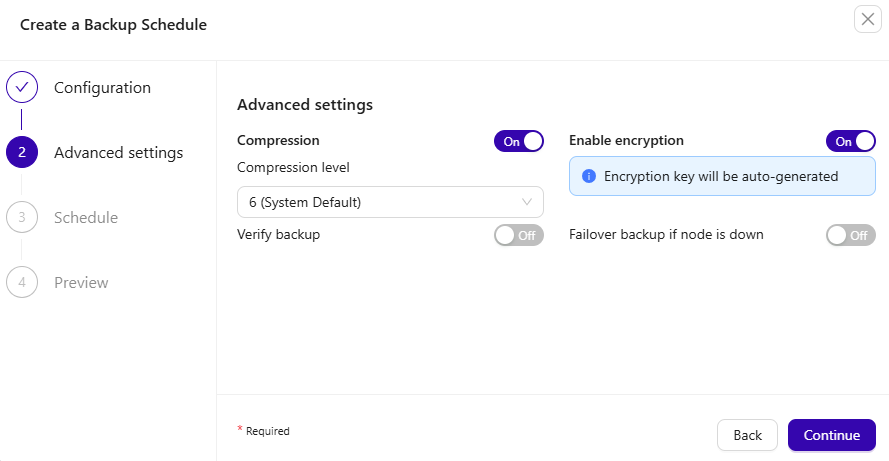
The Advanced Settings allow you to enable Verify Backup (Enterprise tiers only), turn on encryption, and set up failover backups in case a node becomes unavailable.
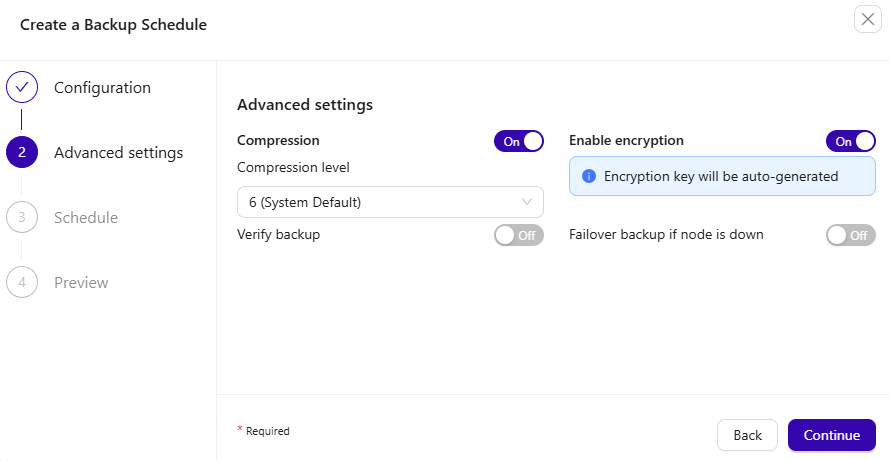
Configure the backup schedule. For example, set the backup to run every day at 1:30 AM UTC.
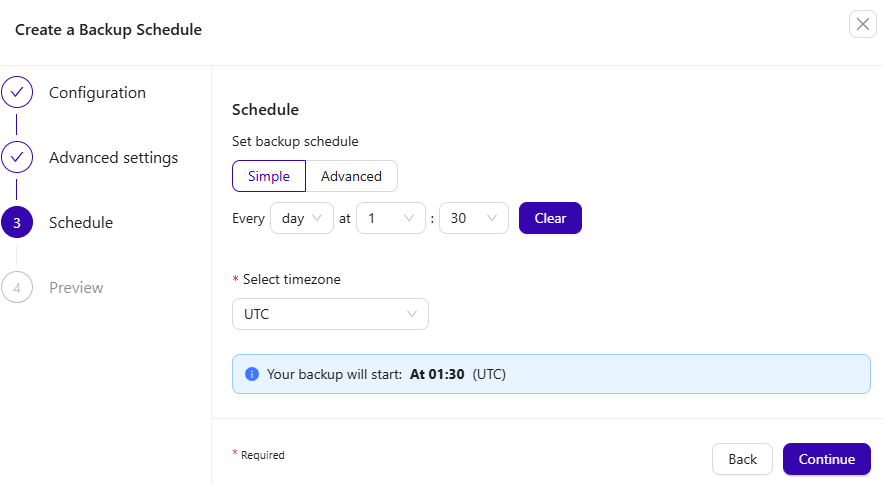
A preview page will appear before you create a scheduled backup.
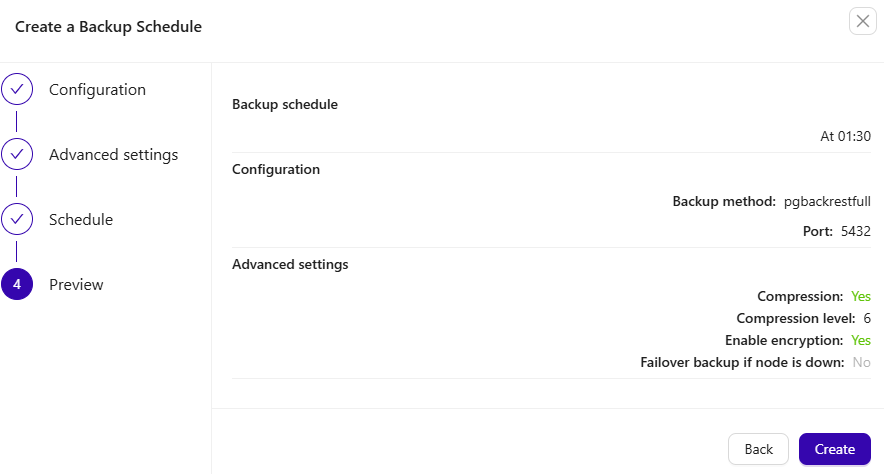
Scheduled backups can be viewed in the Backups → Schedules section.
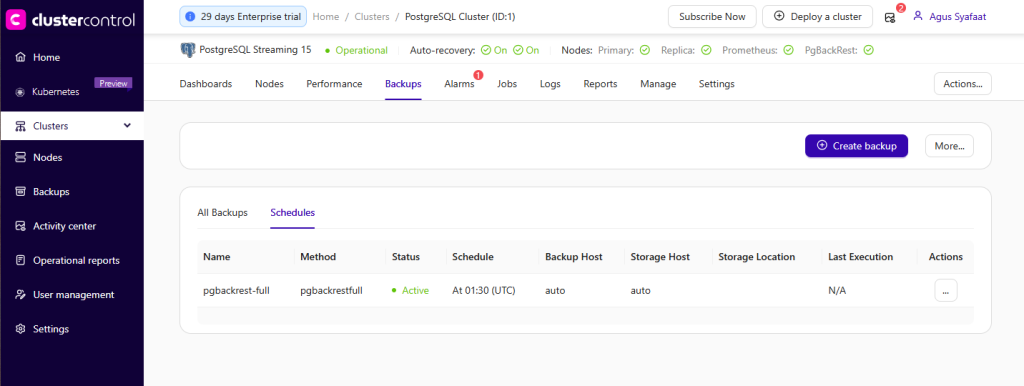
N.B. To configure incremental backups, repeat the same steps, but provide a schedule name and set the backup method to pgbackrestincr.
Now, let’s look at how to set your pgBackRest backup’s retention policy in ClusterControl.
Setting a retention policy for your pgBackRest backup in ClusterControl
Defining a backup retention policy is crucial. It determines how long full and incremental backups are kept. The longer the retention period, the larger the disk space required to store them.
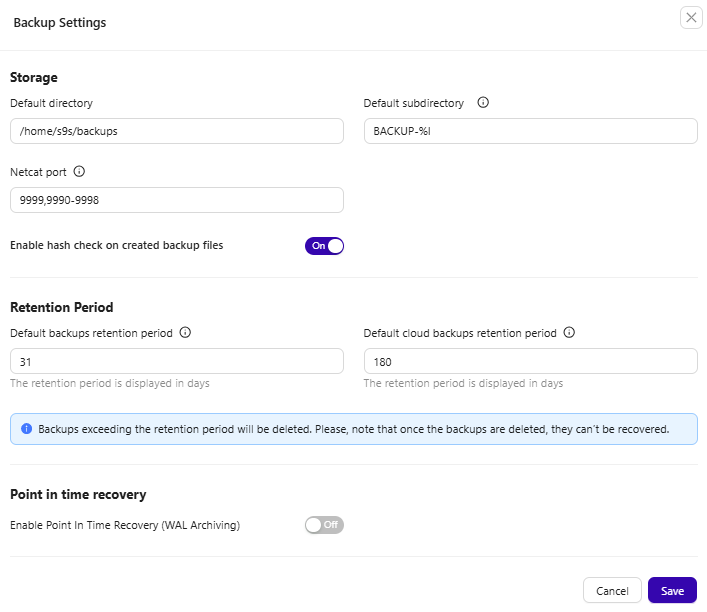
To configure backup retention in ClusterControl, navigate to Backups → More → Backup Settings
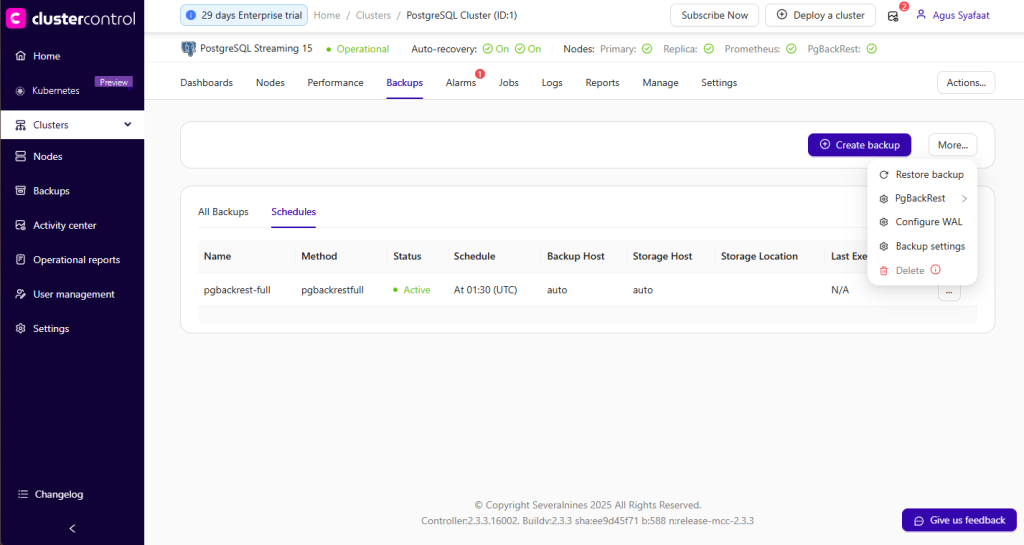
Set the backup retention period, then click Save.
Encryption best practices for Disaster Recovery compliance
It is crucial to enable backup encryption, particularly when dealing with personal or sensitive data. This ensures that, even in the worst-case scenario, only users with the encryption key can restore the backup.
ClusterControl provides AES-256 encryption for backups. Whenever you run a backup or set up a scheduled backup, you can enable encryption through the Backup feature, as illustrated below:
Sending pgBackRest backups to the cloud
Modern enterprises often operate in multi-cloud or hybrid-cloud environments. Backups need to align with these architectures. With ClusterControl, backups can be stored not only on-premise but also on AWS, GCP, Azure, and S3-compatible storage solutions such as MinIO, Ceph Storage, Wasabi, and DigitalOcean — let’s keep it simple and use AWS as an example:
As of this writing, native cloud upload support in pgBackRest is still being developed in ClusterControl. For now, you can configure cloud uploads manually in the pgbackrest.conf file by adding another repository host pointing to the S3. Below is a sample pgbackrest configuration:
[global]
repo1-path=/var/lib/pgbackrest
[stanza-21]
repo1-path=/var/lib/pgbackrest
repo1-retention-full-type=time
repo1-retention-full=31
repo1-retention-diff=31
repo1-retention-archive-type=full
repo2-s3-key=****************
repo2-s3-key-secret=****************
repo2-s3-bucket=db-core-system
repo2-s3-endpoint=s3.us-east-2.amazonaws.com
repo2-s3-region=us-east-2
repo2-type=s3
repo2-path=/test-repo
pg1-port=5432
pg1-path=/var/lib/postgresql/11/mainCreate the AWS access key, secret key, bucket, S3 endpoint, and region configuration. Once completed, recreate the stanza in pgBackRest.
Testing Restores and running Disaster Recovery Drills
Finally, backups aren’t considered reliable until you verify them with a test restore. Regular restore tests ensure you can recover data quickly in the event of a failure. Assuming backups are already in place with Barman and pgBackRest, you can validate them by performing a test restore using the steps below:
Manual PITR restore test in Barman
The requirements for performing a restore in Barman are: a valid backup in Barman, WAL archiving to the same Barman server, and connectivity and permissions from the Barman server to the target restore host. Decide the recovery target with timestamp and for remote restore host from barman, you can use option --remote-ssh-command. Stop PostgreSQL service in restore host, and run the following command in Barman Server:
pgbackrest --stanza=main \
--type=time \
--target="2025-10-01 12:30:00" \
--target-action=promote \
restoreIt will restore the backup to the point in time you specified. After that, start the PostgreSQL service and verify the restore of backup.
PITR restore test in pgBackRest
To test a PITR restore with pgBackRest, ensure that you have a valid backup, WAL archiving to the same repository, and a working pgbackrest.conf on the host where you will perform the restore (with the stanza correctly defined and the repository reachable). Identify your recovery target (for example, by timestamp). Then stop the PostgreSQL service on the host, prepare the data directory, and run the restore command:
pgbackrest –stanza=main \ –type=time \ –target=”2025-10-01 12:30:00″ \ –target-action=promote \ restore |
The option --type=time restores a base backup and replays WAL to the given timestamp and --target-action=promote tells PostgreSQL to finish recovery and become read-write when target is reached. After that, start the PostgreSQL instance and verify the restore.
Using ClusterControl to spin up a “restore cluster” for test drills.
ClusterControl supports PITR for pgBackRest to the node itself. Performing a PITR in ClusterControl is straightforward: select the backup you want to restore, then choose Actions → Restore.
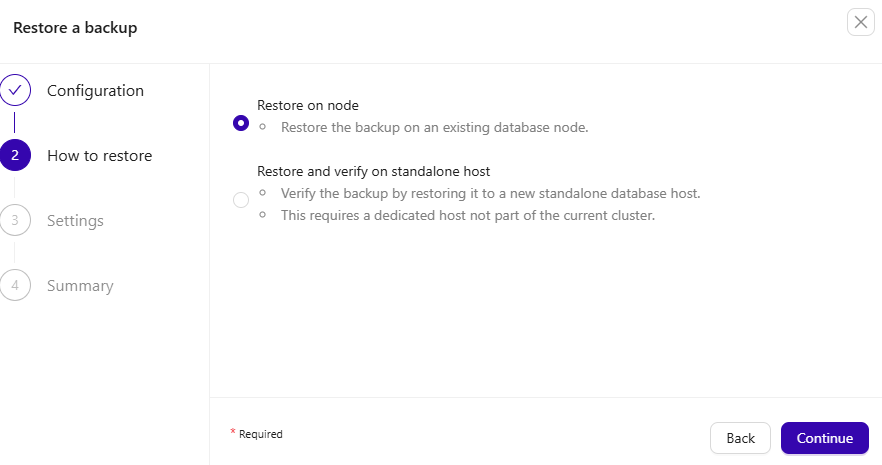
Choose the Restore option for the node:
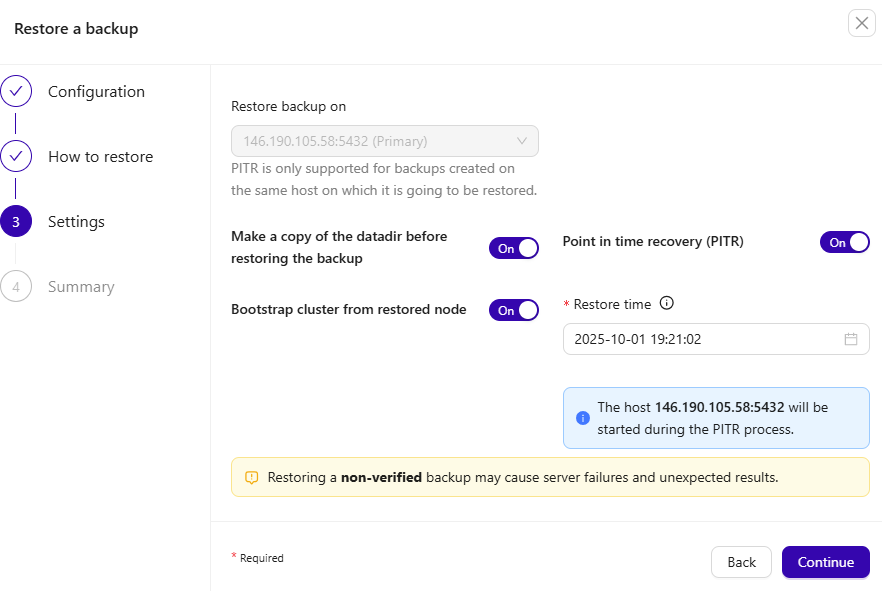
Enable PITR, select ‘Make a copy of the data directory before restore,’ and specify the target timestamp to roll back to.
Wrapping Up
Backups don’t protect your business, proven restores do. The only way to know your RTO/RPO are realistic, your runbooks complete, and your people ready is to practice restores on a schedule. Tools like pgBackRest are built with performance at scale in mind; but, there is always a point where self-administering your backup operations becomes unwieldy.
That’s where tools like ClusterControl come in to standardize and render your backup ops consistent and resilient. Get started in minutes: Install ClusterControl directly from this post and streamline your PostgreSQL operations with a free 30-day Enterprise trial.
ClusterControl Script Installation Instructions
The installer script is the simplest way to get ClusterControl up and running. Run it on your chosen host, and it will take care of installing all required packages and dependencies.
Offline environments are supported as well. See the Offline Installation guide for more details.
On the ClusterControl server, run the following commands:
wget https://severalnines.com/downloads/cmon/install-cc
chmod +x install-ccWith your install script ready, run the command below. Replace S9S_CMON_PASSWORD and S9S_ROOT_PASSWORD placeholders with your choice password, or remove the environment variables from the command to interactively set the passwords. If you have multiple network interface cards, assign one IP address for the HOST variable in the command using HOST=<ip_address>.
S9S_CMON_PASSWORD=<your_password> S9S_ROOT_PASSWORD=<your_password> HOST=<ip_address> ./install-cc # as root or sudo userAfter the installation is complete, open a web browser, navigate to https://<ClusterControl_host>/, and create the first admin user by entering a username (note that “admin” is reserved) and a password on the welcome page. Once you’re in, you can deploy a new database cluster or import an existing one.
The installer script supports a range of environment variables for advanced setup. You can define them using export or by prefixing the install command.
See the list of supported variables and example use cases to tailor your installation.
Other Installation Options
Helm Chart
Deploy ClusterControl on Kubernetes using our official Helm chart.
Ansible Role
Automate installation and configuration using our Ansible playbooks.
Puppet Module
Manage your ClusterControl deployment with the Puppet module.
ClusterControl on Marketplaces
Prefer to launch ClusterControl directly from the cloud? It’s available on these platforms:



