blog
Advanced Failover Using Post/pre Script Hooks

The Importance of Failover
Failover is one of the most important database practices for database governance. It’s useful not only when managing large databases in production, but also if you want to be sure that your system is always available whenever you access it – especially on the application level.
Before a failover can take place, your database instances have to meet certain requirements. These requirements are, in fact, very important for high availability. One of the requirements that your database instances have to meet is redundancy. Redundancy enables the failover to proceed, in which the redundancy is setup to have a failover candidate which can be a replica (secondary) node or from a pool of replicas acting as standby or hot-standby nodes. The candidate is selected either manually or automatically based on the most advanced or up-to-date node. Usually, you would want a hot-standby replica as it can save your database from pulling indexes from disk as a hot-standby often populates indexes into the database buffer pool.
Failover is the term used to describe that a recovery process has occurred. Prior to the recovery process, this occurs when a primary (or master) database node fails after a crash, after natural disasters, after a hardware failure, or it may have suffered a network partitioning; these are the most common cases why a failover might take place. The recovery process usually proceeds automatically and then searches for the most desired and up-to-date secondary (replica) as stated previously.
Advanced failover
Although the recovery process during a failover is automatic, there are certain occasions when it is not necessary to automate the process, and a manual process has to take over. Complexity is often the main consideration associated with the technologies comprising the whole stack of your database – automatic failover can be mixed with manual failover as well.
In most day-to-day considerations with managing databases, the majority of the concerns surrounding the automatic failover is really not trivial. It often comes up handy to implement and setup an automatic failover in case problems occur. Though that sounds promising as it covers complexities, there comes the advanced failover mechanisms and that involves “pre” events and the “post” events which are tied as hooks in a failover software or technology.
These pre and post events come up with either checks or certain actions to perform before it can finally proceed with the failover, and after a failover is done, some cleanups to make sure that failover is finally a successful one. Fortunately, there are tools available that allow, not only just Automatic Failover, but features capability to apply pre and post script hooks.
In this blog, we’ll use ClusterControl (CC) automatic failover and will explain how to use the pre and post script hooks and which cluster do they apply to.
ClusterControl Replication Failover
The ClusterControl failover mechanism is efficiently applicable over asynchronous replication which is applicable to MySQL variants (MySQL/Percona Server/MariaDB). It’s applicable to PostgreSQL/TimescaleDB clusters as well – ClusterControl supports streaming replication. MongoDB and Galera clusters have its own mechanism for automatic failover built into its own database technology. Read more about how the ClusterControl performs automatic database recovery and failover.
ClusterControl failover does not work unless the Node and Cluster recovery (Auto Recovery are enabled). That means that these buttons should be green.
The documentation states that these configuration options can be used as well to enable / disable the following:
|
enable_cluster_autorecovery= |
|
|
enable_node_autorecovery= |
|
$ systemctl restart cmon
For this blog, we’re mainly focusing on how to use the pre/post script hooks which is essentially a great advantage for advanced replication failover.
Cluster failover replication pre/post script support
As mentioned earlier, MySQL variants that use asynchronous (including semi-synchronous) replication and streaming replication for PostgreSQL/TimescaleDB support this mechanism. ClusterControl has the following configuration options which can be used for pre and post script hooks. Basically, these configuration options can be set via their configuration files or can be set through the web UI (we’ll deal with this later).
Our documentation states that these are the following configuration options that can alter the failover mechanism by using the pre/post script hooks:
|
replication_pre_failover_script= |
|
|
replication_post_failover_script= |
|
|
replication_post_unsuccessful_failover_script= |
|
Technically, once you set the following configuration options in your /etc/cmon.d/cmon_
$ systemctl restart cmonAlternatively, you can also set the configuration options by going to
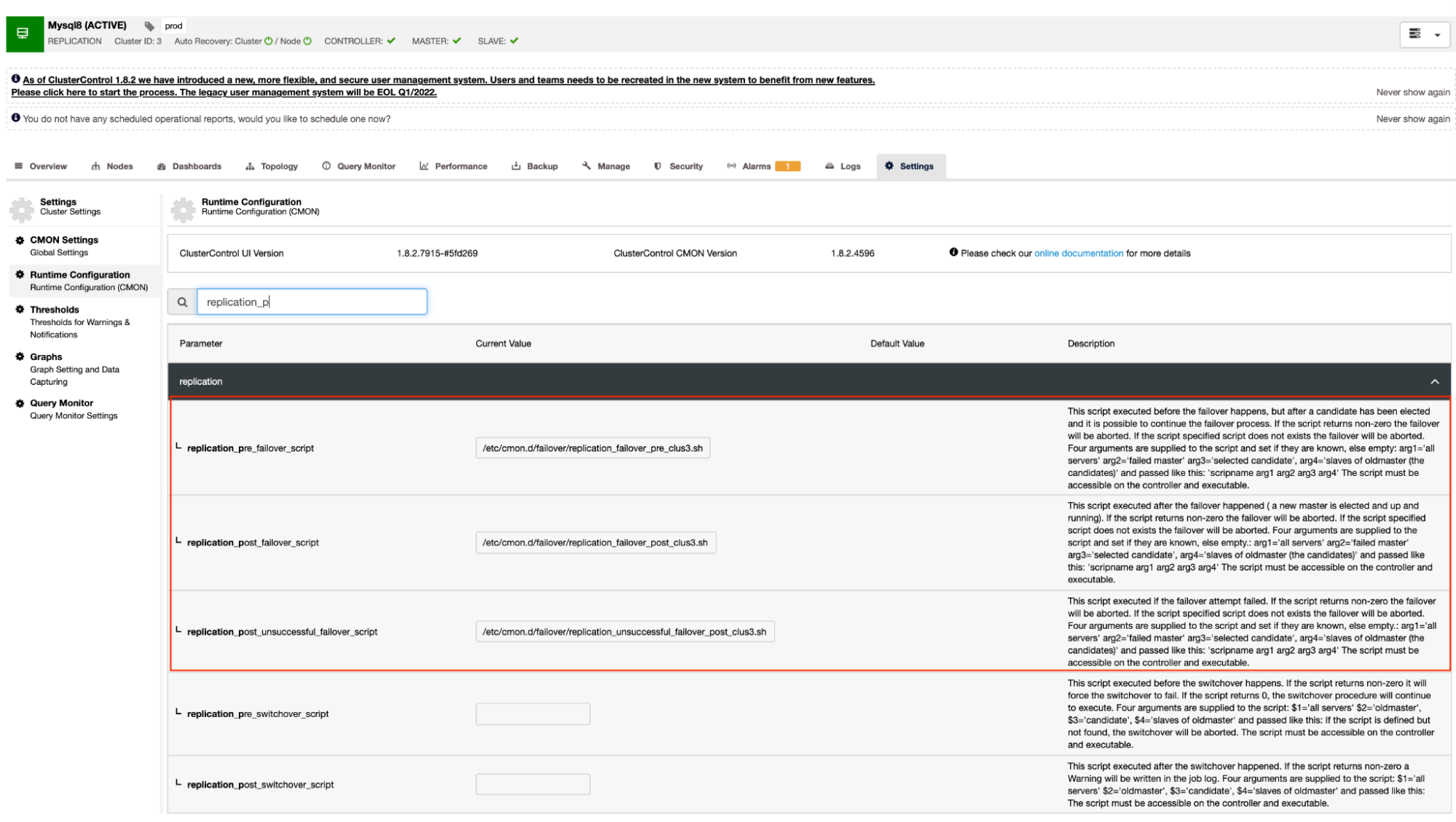
This approach would still require a restart to cmon service before it can reflect the changes made for these configuration options for pre/post script hooks.
Example of pre/post script hooks
Ideally, the pre/post script hooks are dedicated when you need an advanced failover for which ClusterControl could not manage the complexity of your database setup. For example, if you are running different data centers with tightened security and you want to determine if the alert of the network being unreachable is not a false positive alarm. It has to check if the primary and the slave can reach each other and vice versa and it can also reach from the database nodes going to the ClusterControl host.
Let’s do that in our example and demonstrate how you can benefit from it.
Server details and the scripts
In this example, I am using a MariaDB Replication cluster with just a primary and a replica. Managed by ClusterControl to manage the failover.
ClusterControl = 192.168.40.110
primary (debnode5) = 192.168.30.50
replica (debnode9) = 192.168.30.90
In the primary node, create the script as stated below,
root@debnode5:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa [email protected] -T "cat >> /tmp/debnode5.tmp"Make sure that the /opt/pre_failover.sh is executable, i.e.
$ chmod +x /opt/pre_failover.shThen use this script to be involved via cron. In this example, I created a file /etc/cron.d/ccfailover and have the following contents:
root@debnode5:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shIn your replica, just use the following steps we did for the primary except change the hostname. See the following of what I have below in my replica:
root@debnode9:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa [email protected] -T "cat > /tmp/debnode9.tmp"and make sure that the script invoked in our cron is executable,
root@debnode9:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControl pre/post scripts
In this demonstration, my cluster_id is 3. As stated earlier in our documentation, it requires that these scripts have to reside in our CC controller host. So in my /etc/cmon.d/cmon_3.cnf, I have the following:
[root@pupnode11 cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shWhereas, the following “pre” failover script determines if both nodes were able to reach the CC controller host. See the following:
[root@pupnode11 cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[root@pupnode11 failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: $@" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: $@" > /tmp/post_unsuccessful_failover_script_cid3.txt
Demo the failover
Now, let’s try to simulate network outage on the primary node and see how it will react. In my primary node, I take down the network interface that is used to communicate with the replica and the CC controller.
root@debnode5:~# ip link set enp0s8 downDuring the first attempt of failover, CC was able to run my pre script which is located at /etc/cmon.d/failover/replication_failover_pre_clus3.sh. See below how it works:

Obviously, it fails because the timestamp that has been logged is not yet more than a minute or it was just a few seconds ago that the primary was still able to connect with the CC controller. Obviously, that is not the perfect approach when you are dealing with a real scenario. However, ClusterControl was able to invoke and execute the script perfectly as expected. Now, how about if it indeed reaches more than a minute (i.e. > 60 seconds)?
In our second attempt of failover, since the timestamp reaches more than 60 seconds, then it deems to be a true positive, and that means we have to failover as intended. CC has been able to perfectly execute it and even execute the post script as intended. This can be seen in the job log. See the screenshot below:
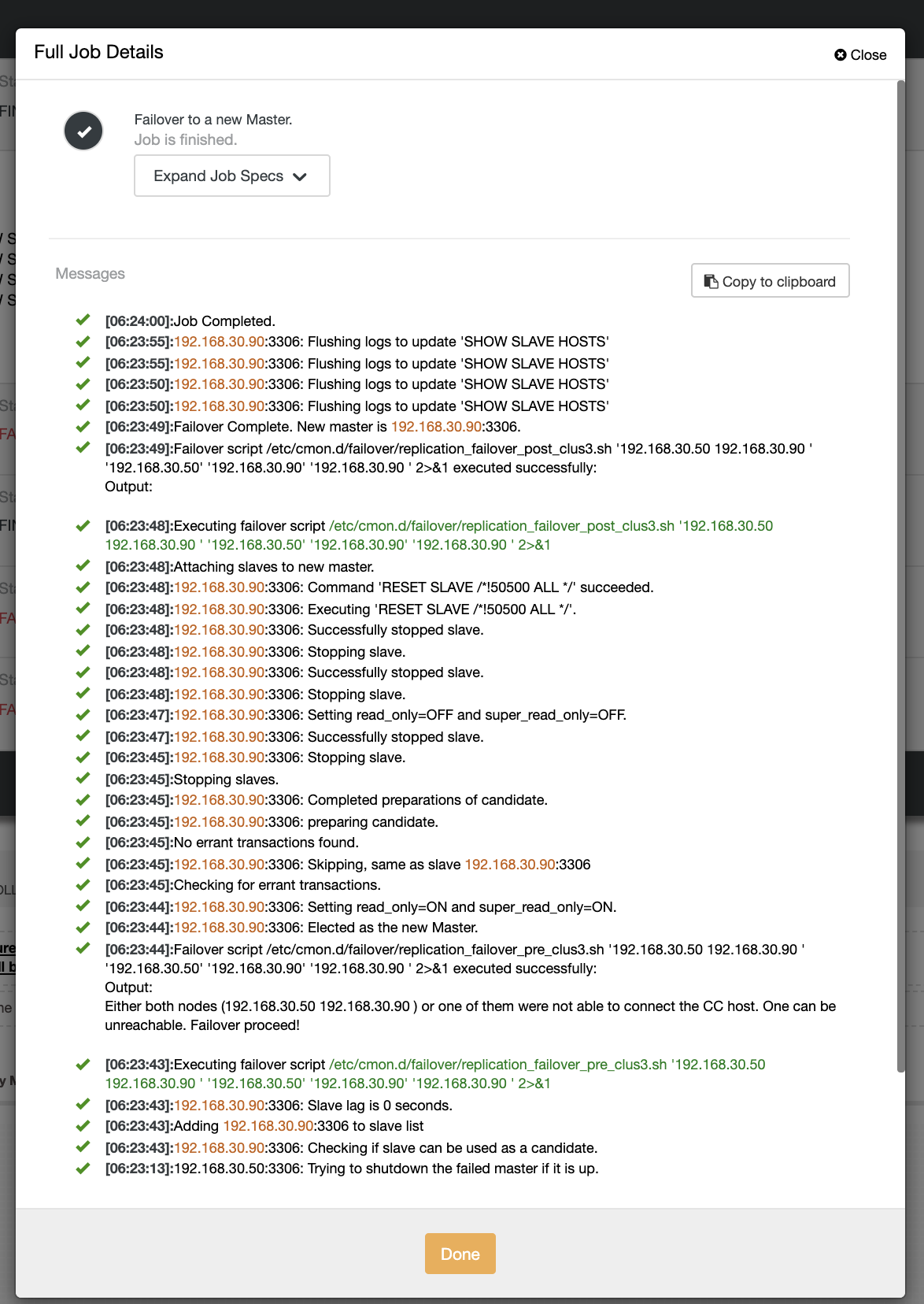
Verifying if my post script was ran, it was able to create the log file in the CC /tmp directory as expected,
[root@pupnode11 tmp]# cat /tmp/post_failover_script_cid3.txtpost failover script on cluster 3 with args: 192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
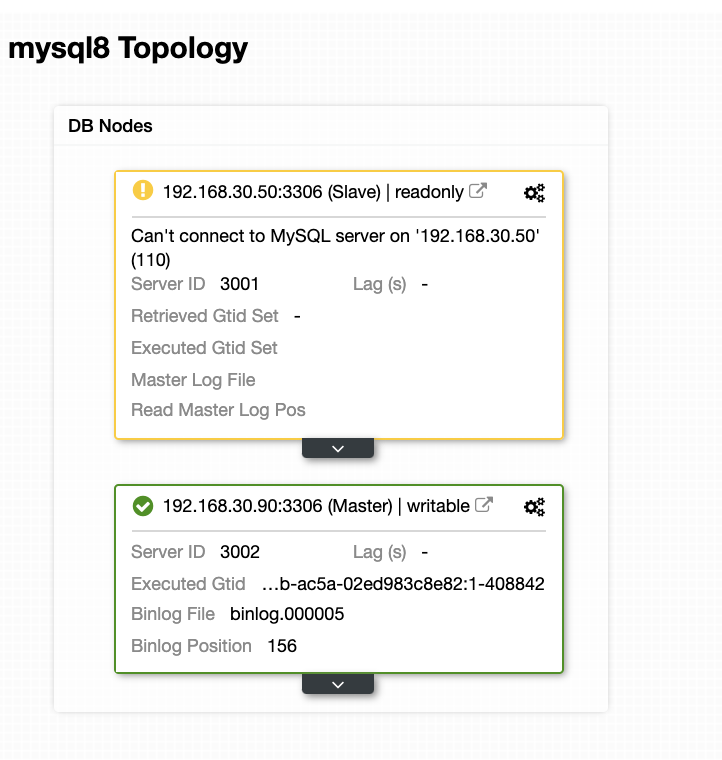
Now, my topology has been changed and the failover was successful!
Conclusion
For any complicated database setup you might have, when an advanced failover is required, pre/post scripts can be very helpful to make things achievable. Since ClusterControl supports these features, we have demonstrated how powerful and helpful it is. Even with its limitations, there are always ways to make things achievable and useful especially in production environments.



