blog
5 Performance Tips for Running Galera Cluster on AWS Cloud

Amazon Web Services is one of the most popular cloud environments. Galera Cluster is one of the most popular MySQL clustering solutions. This is exactly why you’ll see many Galera clusters running on EC2 instances. In this blog post, we’ll go over five performance tips that you need to take under consideration while deploying and running Galera Cluster on EC2. If you want to run regular MySQL on EC2, you’ll find these tips still useful because, well, Galera is built on top of MySQL after all. Hopefully, these tips will help you save time, money, and achieve better Galera/MySQL performance within AWS.
![]()
Choosing a Good Instance Size
When you take a look at the instance chart in the AWS documentation, you’ll see that there are so many instances to choose from. Obviously, you will pick an instance depending on your application needs (therefore you have to do some benchmarking first to understand those needs), but there are couple of things to consider.
CPU and memory – rather obvious. More = better. You want to have some headroom in terms of free CPU, to handle any unexpected spikes of traffic – we’d aim for ~50% of CPU utilization max, leaving the rest of it free.
We are talking about virtualized environment thus we should mention CPU steal utilization. Virtualization offers the ability to over-subscribe the CPU between multiple instances because not all instances need CPU at the same time. Sometimes an instance cannot get the CPU cycles it wants. It can be caused by over allocation on the host’s side when there are no additional CPU cycles to share (you can prevent it from happening by using dedicated instances – “Dedicated Tenancy” can be chosen when you create new instance inside of VPC, additional charges apply) or it can also happen when the load on the instance is too high and the hypervisor throttled it down to its limits.
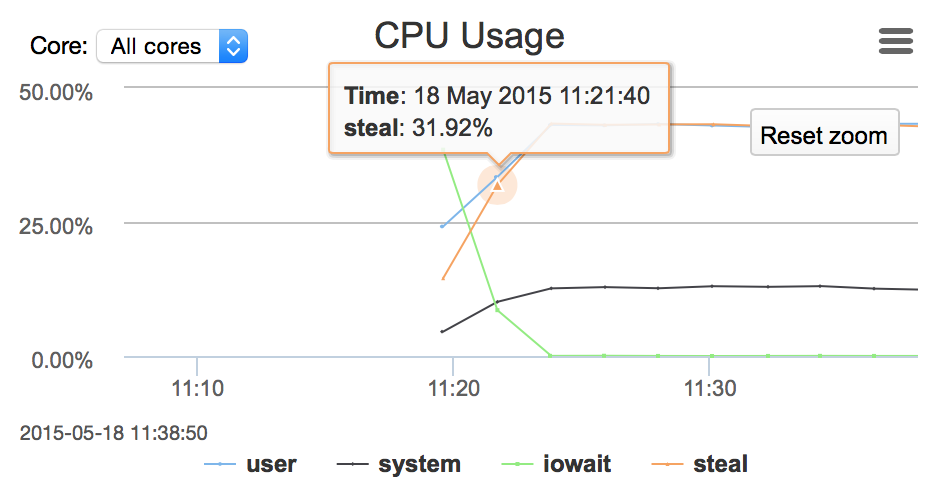
Network and I/O capacity – by default, on non-EBS-optimized instances, network is shared for regular traffic and EBS traffic. It means that your reads and writes will have to compete for the same resource with the replication traffic. You need to measure your network utilization to make sure it is within your instance’s capacity. You can give some free resources to EBS traffic by enabling ‘EBS-optimized’ flag for instance, but again, network capacity differs between instance types – you have to pick something which will handle your traffic.
If you have a large cluster and you feel brave, you can use ephemeral SSD storage on instances as a data directory – it will reduce expenses on pIOPS EBS volumes. On the other hand, instance crash will end in data being wiped out. Galera can recover from such state using SST, but you would have to have a large cluster spanning multiple AWS regions to even consider this setup as an option. Even in such a case, you may consider using at least one EBS-based node per region, to be able to survive crashes and have data locally for SST.
If you choose EBS as your storage, you have to remember that EBS should be warmed up before putting it into production. EBS allocates only those blocks which are actually used. If you didn’t write on a given block, it will have to be allocated once you do this. Allocation process adds overhead (per Amazon it may be up to 50% of the performance) so it is a very good practice to perform the warmup. It can be done in several ways.
If the volume is new, then you can run:
$ sudo umount /dev/xvdx
$ sudo dd if=/dev/zero of=/dev/xvdx bs=1MIf the volume was created from the snapshot of the warmed up volume, you need just to read all of the blocks by:
$ sudo umount /dev/xvdf
$ sudo dd if=/dev/xvdf of=/dev/null bs=1MOn the other hand, if the original volume has not been warmed up, then the new volume needs a thorough warming by reading each block and writing it back to the volume (no data will get lost in the process):
$ sudo umount /dev/xvdf
$ sudo dd if=/dev/xvdf of=/dev/xvdf conv=notrunc bs=1MChoosing a Deployment Architecture
AWS gives you multiple options regarding the way your architecture may look like. We are not going into details of VPC vs. non-VPC, ELB’s or Route53 – it’s really up to you and your needs. What we’d like to discuss are availability zones and regions. In general, more spread cluster = better HA. The catch is that Galera is very latency-bound in terms of performance and long distances do not serve it well. While designing a DR site in a separate region, you need to make sure that your cluster design will still match the required performance.
Availability Zones are a different story – latency is fine here and AZ’s provide some level of protection against infrastructure outages (although it has happened that a whole AWS region went down). What you may want to consider is using Galera segments. Segments, in Galera terms, define groups of nodes that are close to each other in terms of network latency. Which may be the same as datacenters when you are deploying across a few sites. Nodes within a single segment will not talk to the rest of the cluster, with the exception of one single relay node (chosen automatically). Data transfers (both IST and SST) will also happen within nodes from the same segment (only if it is possible). This is somewhat important because of the network transfer fees that apply to connections between multiple AWS regions but also between different AZ’s – using segments you can significantly decrease the amount of data transferred between them.
With a single segment, writesets are sent from a host that received DML to all other nodes in the cluster:
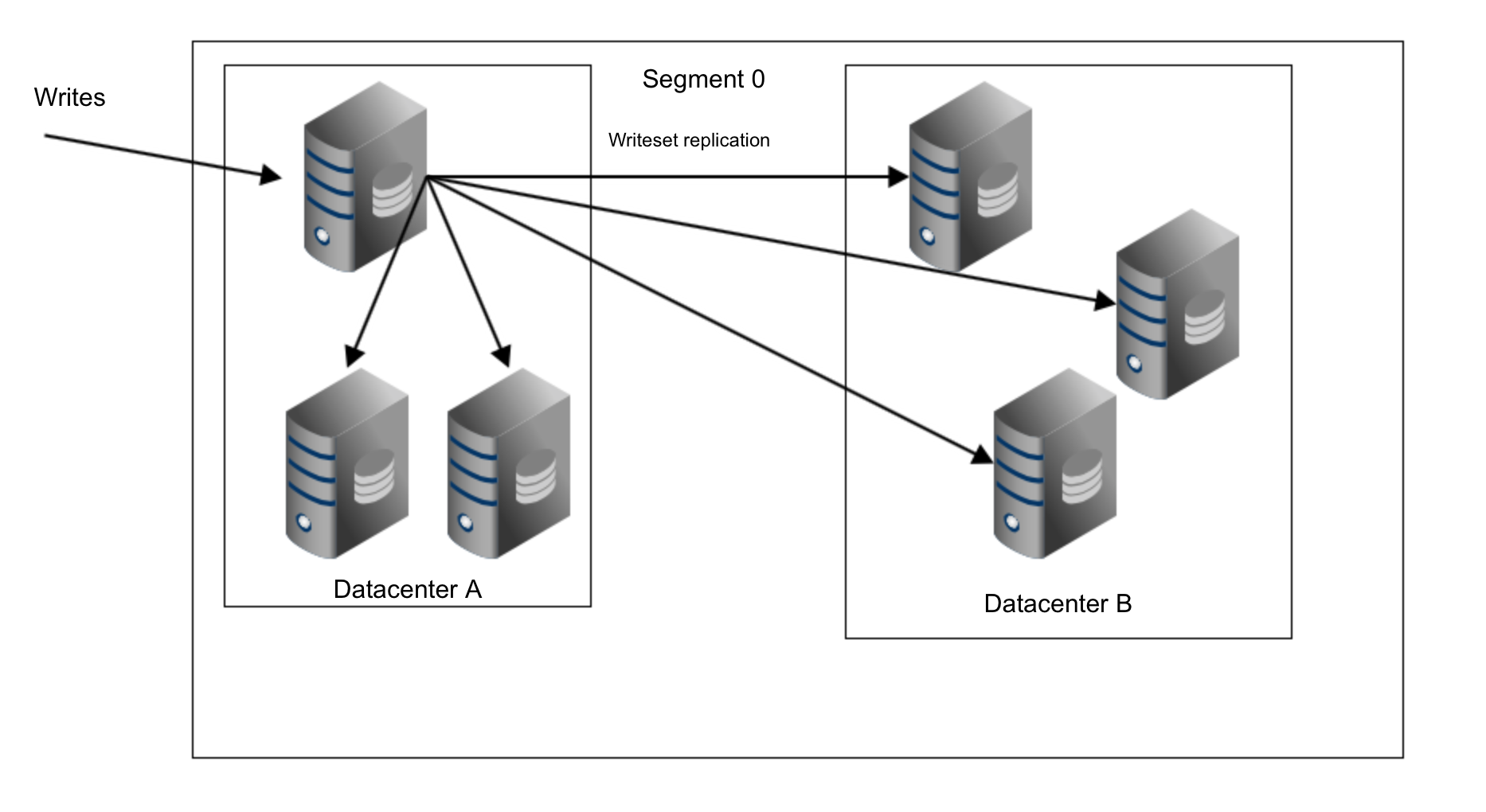
As you can see, we have three copies of replication data sent from the datacenter A to the datacenter B. With segments it’s different. In datacenter B one of the hosts will be picked as a relay node and only this node will get the replication data. If that node fails, another one will be picked automatically.
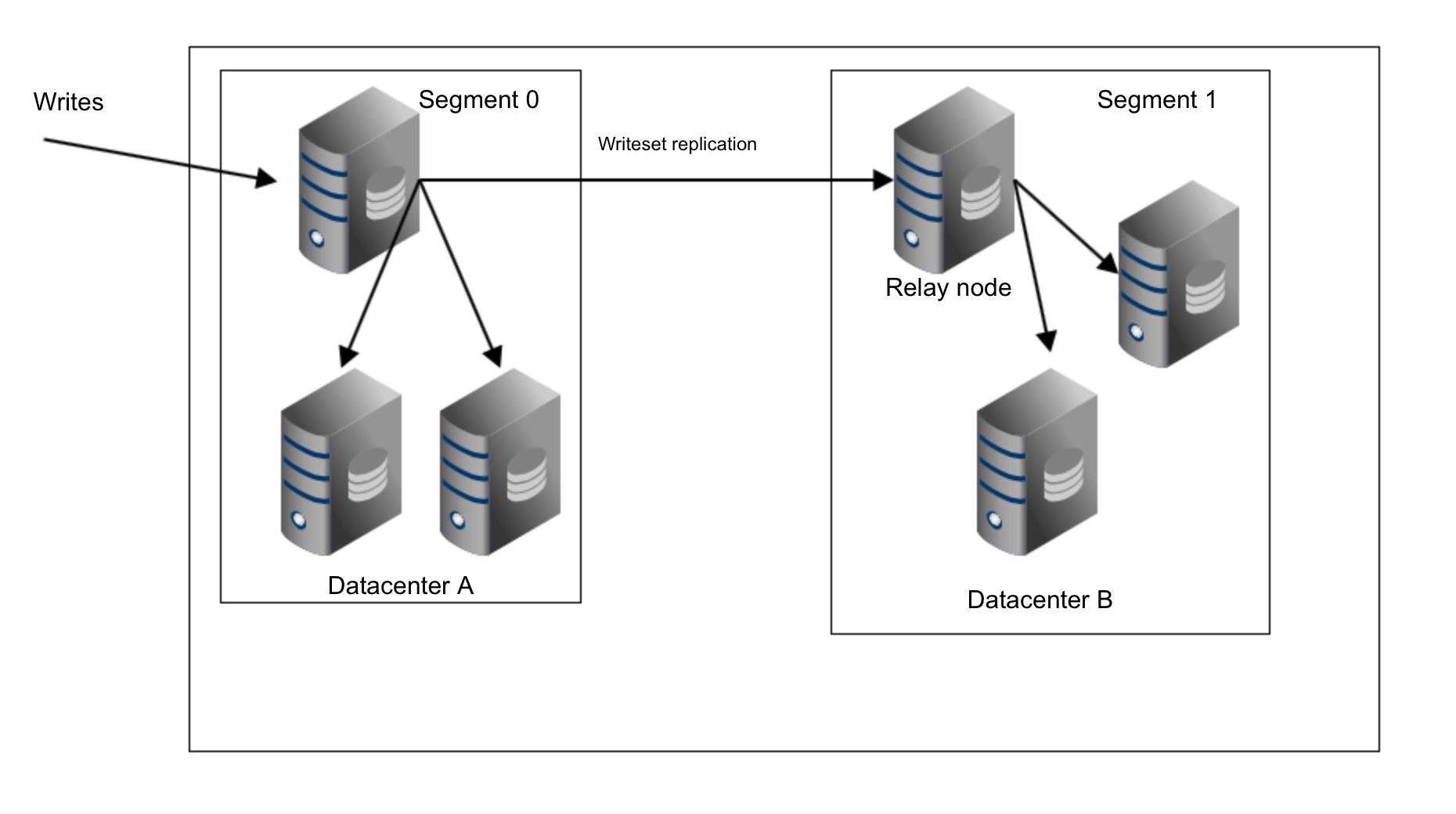
As you can see, we just removed two thirds of the traffic between our two datacenters.
Operating System Configuration
vm.swappiness = 1
Swappiness controls how aggressive the operating system will use swap. It should not be set to zero because in more recent kernels it prevents the OS from using swap at all and it may cause serious performance issues.
/sys/block/*/queue/scheduler = deadline/noop
Scheduler for the block device, which MySQL uses, should be set to either deadline or noop. Exact choice depends on the benchmarks but both settings should deliver similar performance, better than default scheduler, CFQ.
For MySQL, you should consider using EXT4 or XFS, depending on the kernel (performance of those filesystems changes from one kernel version to another). Perform some benchmarks to find the better option for you.
my.cnf Configuration
wsrep_provider_options=”evs.suspect_timeout=PT5S”
wsrep_provider_options=”evs.inactive_timeout=PT15S”
You may want to consider changing the default values of these variables. Both timeouts govern how the cluster evicts failed nodes. Suspect timeout takes place when all of the nodes cannot reach the inactive member. Inactive timeout defines a hard limit of how long a node can stay in the cluster if it’s not responding. Usually you’ll find that the default values work well. But in some cases, especially if you run your Galera cluster over WAN (for example, between AWS regions), increasing those variables may result in more stable performance.
wsrep_provider_options=”evs.send_window=4″
wsrep_provider_options=”evs.user_send_window=2″
These variables, evs.send_window and evs.user_send_window define how many packets can be sent in the replication at a single time (evs.send_window) and how many of them may contain data (evs.user_send_window). The later should be no more than the half of the former.
For high latency connections it may be worth increasing those values significantly (512 and 256 for example).
The following variable may also be changed. evs.inactive_check_period, by default, is set to one second, which may be too often for a WAN setup.
wsrep_provider_options=”evs.inactive_check_period=PT1S”
Network Tuning
Here comes the tricky part. Unfortunately, there is no definitive answer on how to set up both Galera and the OS’s network settings. As a rule of thumb, you may assume that in high latency environments, you would like to increase the amount of data sent at once. You may want to look into variables like gcs.max_packet_size and increase it. Additionally, you will probably want to push the replication traffic as quickly as possible, minimizing the breaks. Having gcs.fc_factor close to 1 and significantly larger than default gcs.fc_limit should help to achieve that.
Apart from Galera settings, you may want to play with the operating system’s TCP settings like net.core.rmem_max, net.core.wmem_max, net.core.rmem_default, net.core.wmem_default, net.ipv4.tcp_tw_reuse, net.ipv4.tcp_slow_start_after_idle, net.ipv4.tcp_max_syn_backlog, net.ipv4.tcp_rmem, net.ipv4.tcp_wmem. As mentioned earlier, it is virtually impossible to give you a simple recipe on how to set those knobs as it depends too many factors – you will have to do your own benchmarks, using data as close to your production data as possible, before you can say your system is tuned.
We will continue this topic in a follow-up blog – in the next part we are going to discuss how you can leverage AWS tools while maintaining your Galera cluster.



