blog
Hash Slot vs. Consistent Hashing in Redis

About Hash Slots in Redis Cluster
Hash slot in Redis was introduced when the Redis Cluster was released in its version 3.0, more than 6 years ago. In fact, the Redis Cluster was taking too much time to develop as you might notice in this screencast (unstable version at that time) – the benevolent Salvatore Sanflippo represented this feature 2 years before it was released.
The hash slot represents the algorithm behind the Redis Cluster for managing keys. For which the latter represents the sharding solution or distributed database that the traditional asynchronous master-slave set up in a common single master setup for Redis does not possess.
A little bit about Redis Cluster
A Redis Cluster, if you are comparing it to the standalone Redis which is the non-distributed database setup, is a different solution, and it is applicable for data partitioning or sharding. Sharding here means data is shared across multiple Redis instances.
Redis Cluster, as mentioned earlier, was added to Redis version 3.0, and it provides the capability to perform data synchronization, replication, and manage node access persistence if some will go down. This means that Redis Cluster provides a degree of availability for continuing operations in the event of a node failing or a communication issue. Moreover, It just represents a full clustering solution for segmentation, replication, and node management.
Nodes in the Redis Cluster use the Redis cluster protocol to connect with every other node in the Redis cluster for a mesh network topology. Nodes communicate using a TCP gossip protocol and along with a configuration update mechanism in order to reduce the number of messages being exchanged between nodes.
Though Redis Cluster is a powerful feature in Redis, it has its limitations as far as stand-alone Redis is concerned, for example if you take a master with replica(s). For example, whereas in a stand-alone Redis, if you have, say, a master-slave replication, you can have 0 – 15 databases (by default) to use, which you can adjust via configuration. However, in a Redis Cluster, you can only operate in database 0, i.e. only one database, and the SELECT command is not allowed. On the other hand, not all commands can work as said, such as MSET and MGET cannot work as they have to reside in one slot.
For example:
192.168.40.190:6001> keys *
1) "mykey{node2}"
2) "kiddo:3"
3) "mykey2{node2}"
4) "book:2"While this cannot work:
192.168.40.190:6001> mget mykey{node2} mykey2{node2} book:2
(error) CROSSSLOT Keys in request don't hash to the same slotor
192.168.40.190:6001> mget mykey{node2} mykey2{node2} kiddo:3
(error) CROSSSLOT Keys in request don't hash to the same slotWhereas:
192.168.40.190:6001> mget mykey{node2} mykey2{node2}
1) "a,b,c"
2) "a,b,c"Since they are on the same slot using Hash Tags. It is a Redis Cluster concept that can be used in order to force certain keys to be stored in the same hash slot. When checking its key slot, this will reveal the following:
192.168.40.190:6001> CLUSTER KEYSLOT mykey{node2}
(integer) 15917
192.168.40.190:6001> CLUSTER KEYSLOT mykey2{node2}
(integer) 15917While the other keys are on the same node but on different slots:
192.168.40.190:6001> CLUSTER KEYSLOT kiddo:3
(integer) 14082
192.168.40.190:6001> CLUSTER KEYSLOT book:2
(integer) 12948What is a Hash Slot in Redis?
Redis cluster uses a form of composite partitioning called consistent hashing that calculates what Redis instance the particular key shall be assigned to. This concept is called a hash slot in the Redis Cluster. The key space is partitioned across the different masters in the cluster. It is split into 16384 slots, effectively setting an upper limit for the cluster size of 16384 master nodes (however, the suggested max size of nodes is in the order of ~1000 nodes).
The hash slot is the CRC-16 hash algorithm applied to the key and then the computation of a modulo using 16384. The specific hash algorithm used by the Redis cluster to calculate the hash slot for a key is:
HASH_SLOT = CRC16(key) mod 16384Although CRC-16 has other types, Redis has the following specifics for using this algorithm:
-
Name: XMODEM (also known as ZMODEM or CRC-16/ACORN or CRC-CCITT)
-
Width: 16 bit
-
Poly: 1021 (That is actually x16 + x12 + x5 + 1)
-
Initialization: 0000
-
Reflect Input byte: False
-
Reflect Output CRC: False
-
Xor constant to output CRC: 0000
-
Output for “123456789”: 31C3
Each master node is assigned a sub-range of hash slots and the key and value will reside on that Redis instance. Basically, every key is hashed into a number between 0 and 16383. These 16k hash slots are split among the different masters.
If you ever wonder why 16384 (or 0 – 16383), Salvatore has a good explanation on this. Basically, Redis chooses 16384 slots because 16384 messages only occupy 2k, while 65535 would require 8k. For its Cluster scale design considerations, the cluster supports a maximum of 1000 shards. 16384 is a relatively good choice. It is necessary to ensure that under the largest cluster size and evenly distributed slots, the average number of slots per shard is not too large but small.
Consistent Hashing vs Hash Slot
Prior to Redis 3.0 when Redis Cluster was not yet available, it has been a challenge when distributing the keys to observe load management among multiple masters for implementing sharding or data partitioning. For Redis 3.0 and below, Redis-server does not have a sharding functionality, it only has a master-slave mode. Consistent hashing and hash slots are algorithms that would suffice as far as sufficient distributing of keys that serve to be cached to Redis is concerned. There are other ways you can implement such a logic split or hash algorithm – while the other algorithm works, it is not as performant or is far less performant when compared to consistent hashing and the hash slot that is commonly used in Redis master-slave mode or Redis Cluster. But in this blog, we will focus on the two algorithm modes, Consistent Hashing, and Hash Slot.
Both algorithms, as the name suggests, use hash functions and thus use hash tables. Think of a bucket for which either you constantly fill or retrieve the object of the bucket. Consistent Hashing and Hash Slots do operate similar to a bucket. Say we have an array of size N, with each entry pointing to an object bucket. Adding a new object would require us to do a h(k) % N i.e. hash(key) modulo N. Then check the bucket at the resulting index. Adding the object if it is not already there. To search for an object, we do the same, just looking into the bucket to check if the object is there. Although the searches in hash tables (or bucket in this analogy) are linear, a properly sized hash table should have a reasonably small number of objects per bucket, resulting in almost constant time access to the average time complexity of O(N/k), where k is the number of buckets.
Consistent Hashing
Consistent Hashing has been supported by multiple clients in Redis. Twemproxy supports multiple hashing modes including consistent hashing and distribution. Other clients such as Jedis, Ketama are also using this approach.
Consistent Hashing is a distribution scheme that does not depend directly on the number of servers, so that, when adding or removing servers, the number of keys that need to be relocated is minimized. Consistent Hashing is a simple but clever concept. It was first described by Karger et al. at MIT in an academic paper from 1997. It operates independently of the number of servers or objects in a distributed hash table by assigning them a position on an abstract circle, or hash ring. This allows servers and objects to scale without affecting the overall system. It is a circle with the power of 0 – 2 ^ 32 – 1. The main operation steps are as follows:
-
To hash a node, usually use its node’s IP or data with a unique label to hash (IP), and distribute its value on this closed circle.
-
Hash (key) the stored key, and then distribute its value on this closed circle.
-
A node found clockwise from the location where hash(key) is mapped on the circle is the node that stores the key. If no node is found at 0 on the circle, the first node in the clockwise direction after 0 is the key storage node.
Basically, the clockwise direction either be counterclockwise shall apply as long as it circumnavigates the checks for which the hash(key) should be stored based on the distribution of nodes in the circle. For example, consider the following example I have:
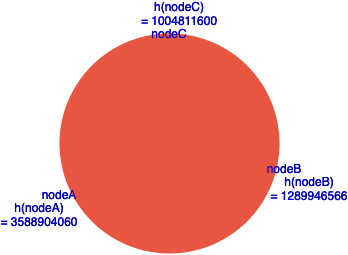
The following hashes is where I use CRC-32 for the node name I have which resulted in the following:
|
Node Name |
Hash CRC-32 |
|
nodeA |
3588904060 |
|
nodeB |
1289946566 |
|
nodeC |
1004811600 |
Consider inserting the names of my beloved pets, I end up with the following,
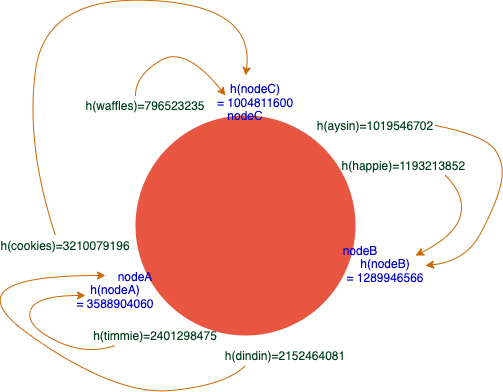
In the figure we have, it checks which of the hash shall belong based on a clockwise pattern. Whereas, the values are checked and placed according to their range within the 2 ^ 32 – 1 hash values in the circle. The values are assigned to be stored which is the nearest neighbor after it is placed in a clockwise pattern. In this regard, consider that nodeA crashes or experiences a network partition. Obviously, how balanced it is as what we have in the figure shall be torn down since the next neighbor in a clockwise pattern shall be the target of the destination for which the keys shall be stored. In that case, this is how it goes in case a change of topology happens,
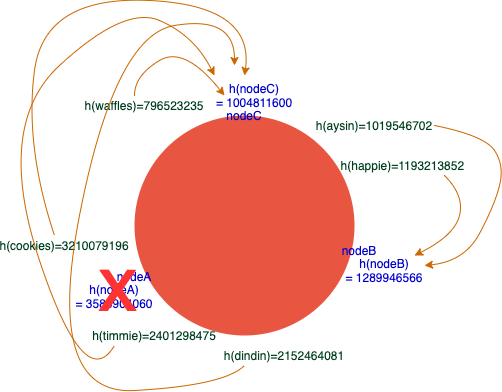
In this state, it results in a data skew leading to an imbalance distribution of keys whereas nodeB can be left with lesser keys in contrast to nodeC. Now, this affects the state of performance for caching since this means, keys have to be moved to another node. Take note that before Redis Cluster, this algorithm was not identified by the Redis server itself or the Redis database, but identified by the clients such as TwemProxy, Jedis as one of the examples. In that case, identifying the keys where it shall belong, can affect the performance of your application that is interfacing with your Redis to check if there is an existing cache or not. Otherwise, it will add or store the new key (supposedly an existing key from the node that is currently experiencing network partition). Of course, once the nodeA comes back or the network issue has been resolved, then it has to be reconfigured again so the client shall be able to determine that the topology has been updated again as the previous node joins back the sharded cluster again.
In such phenomena where your Redis master-slave mode cluster has been experiencing network partition, it is very important to always have high availability. That means a slave and Redis Sentinel can be configured and set up to failover and take the role of the failed master in a sharded cluster. However, this is a different case in a Redis Cluster.
Hash Slots in Redis Cluster
Since we have discussed earlier about hash slots in Redis Cluster, hash slots still share the concept of using hashes or composite partitioning but do not rely on a circle-based algorithm for which the consistent hashing is based upon. Hash slots take care of the importance that the master-slave model in a sharded environment does not have, such as adding and removing a node. In that case, scaling up or down horizontally can be smooth or at least less impact on the performance of your Redis Cluster. Consider the image below:
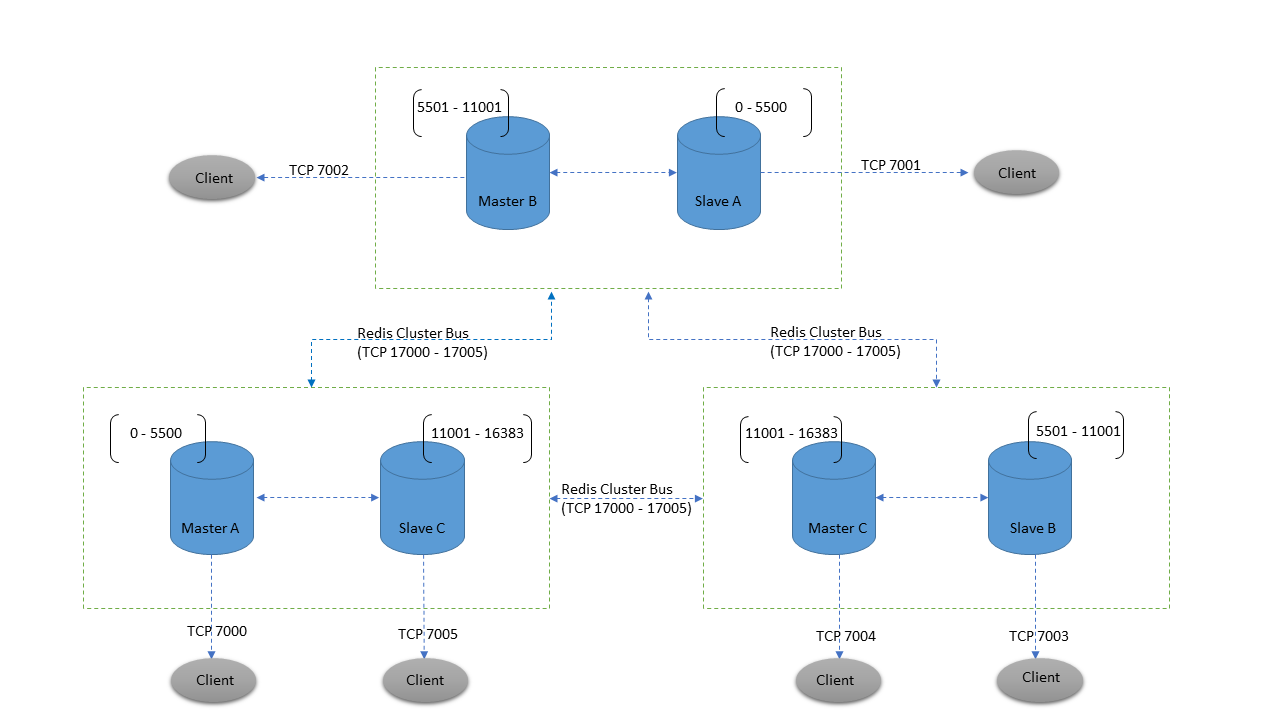
Image from Deep dive into Redis Clustering
The hash slots are pre-calculated for which it is solely determined by the administrator of the Redis Cluster. For example, this is identified beforehand when you create a cluster:
root@pupnode18:~# redis-cli --cluster create 192.168.40.170:6001 192.168.40.180:6001 192.168.40.190:6001 192.168.40.210:6001 192.168.40.221:6001 192.168.40.222:6001 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.40.221:6001 to 192.168.40.170:6001
Adding replica 192.168.40.222:6001 to 192.168.40.180:6001
Adding replica 192.168.40.210:6001 to 192.168.40.190:6001
M: f1502d9387e91c1e36cb0c309a5d57ac55bd74bb 192.168.40.170:6001
slots:[0-5460] (5461 slots) master
M: 361e4fdd5a8f9e0eb0c594cc1ef797a07441c0f6 192.168.40.180:6001
slots:[5461-10922] (5462 slots) master
M: 2f35603cb4b0fc89241af0c0fc44b36181f9c298 192.168.40.190:6001
slots:[10923-16383] (5461 slots) master
S: 2bedffc625d87413758125d695ee53f69b14cc5f 192.168.40.210:6001
replicates 2f35603cb4b0fc89241af0c0fc44b36181f9c298
S: ea3f9475069cc8a93a26af8d649136ae1617f07c 192.168.40.221:6001
replicates f1502d9387e91c1e36cb0c309a5d57ac55bd74bb
S: 5fadaa2a1b3a06b0fcf88e29e754ed053dce8e9a 192.168.40.222:6001
replicates 361e4fdd5a8f9e0eb0c594cc1ef797a07441c0f6
Can I set the above configuration? (type 'yes' to accept): yes
In the above command, I instructed to initiate my Redis Cluster using the redis-cli command with 3 master nodes and 3 replicas. Apart from that, what is note worth mentioning is the automatic assignments of hash slots, i.e.
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383After accepting it with yes, Redis will automatically compute all those assignments of slots as well as the setting up of masters and replicas:
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing Cluster Check (using node 192.168.40.170:6001)
M: f1502d9387e91c1e36cb0c309a5d57ac55bd74bb 192.168.40.170:6001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 2f35603cb4b0fc89241af0c0fc44b36181f9c298 192.168.40.190:6001
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 2bedffc625d87413758125d695ee53f69b14cc5f 192.168.40.210:6001
slots: (0 slots) slave
replicates 2f35603cb4b0fc89241af0c0fc44b36181f9c298
M: 361e4fdd5a8f9e0eb0c594cc1ef797a07441c0f6 192.168.40.180:6001
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: ea3f9475069cc8a93a26af8d649136ae1617f07c 192.168.40.221:6001
slots: (0 slots) slave
replicates f1502d9387e91c1e36cb0c309a5d57ac55bd74bb
S: 5fadaa2a1b3a06b0fcf88e29e754ed053dce8e9a 192.168.40.222:6001
slots: (0 slots) slave
replicates 361e4fdd5a8f9e0eb0c594cc1ef797a07441c0f6
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots coveredNow, going back to the image shown above with Hash Slots, you can see the power of Redis Cluster with a full-pack setup for high availability and redundancy. Take note that you can retrieve or query to get your keys from the slaves, but of course, writes are not enabled in replicas/slaves. Redis Sentinel doesn’t make sense to be set up here since the Redis Cluster Bus and the gossip protocol handle this constant monitoring to determine if the cluster node is healthy or requires an automatic failover in case it is unreachable or stops communicating with the rest of the nodes in the cluster.
Let’s play around with hash slots in a Redis Cluster. First, let’s see the list of nodes and its associated slots assigned:
192.168.40.170:6001> CLUSTER SLOTS
1) 1) (integer) 0
2) (integer) 5460
3) 1) "192.168.40.170"
2) (integer) 6001
3) "f1502d9387e91c1e36cb0c309a5d57ac55bd74bb"
4) 1) "192.168.40.221"
2) (integer) 6001
3) "ea3f9475069cc8a93a26af8d649136ae1617f07c"
2) 1) (integer) 5461
2) (integer) 10922
3) 1) "192.168.40.180"
2) (integer) 6001
3) "361e4fdd5a8f9e0eb0c594cc1ef797a07441c0f6"
4) 1) "192.168.40.222"
2) (integer) 6001
3) "5fadaa2a1b3a06b0fcf88e29e754ed053dce8e9a"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "192.168.40.190"
2) (integer) 6001
3) "2f35603cb4b0fc89241af0c0fc44b36181f9c298"
4) 1) "192.168.40.210"
2) (integer) 6001
3) "2bedffc625d87413758125d695ee53f69b14cc5f"
Now let's clear the keys for all master nodes then add the keys:
192.168.40.170:6001> flushall async
OK
192.168.40.170:6001> set waffles "white pet and chubby"
-> Redirected to slot [14766] located at 192.168.40.190:6001
OK
192.168.40.190:6001> set aysin "grayed hair and loves to lick"
OK
192.168.40.190:6001> set happie "white and loves to lay eggs"
OK
192.168.40.190:6001> set dindin "white and smallest yet cute tailed puff"
-> Redirected to slot [10464] located at 192.168.40.180:6001
OK
192.168.40.180:6001> set timmie "killer eyes when has done something bad"
-> Redirected to slot [1602] located at 192.168.40.170:6001
OK
192.168.40.170:6001> set cookies "max favorite playmate"
-> Redirected to slot [13754] located at 192.168.40.190:6001
OK
192.168.40.190:6001> keys *
1) "happie"
2) "aysin"
3) "cookies"
4) "waffles"
192.168.40.190:6001> set pepper "tummy touches the ground"
-> Redirected to slot [3936] located at 192.168.40.170:6001
OK
192.168.40.170:6001> set buchappie "always barks"
-> Redirected to slot [7027] located at 192.168.40.180:6001
OKThis is what is happening with Hash Slots in Redis Cluster:
|
Keys |
Hash CRC-16 XMODEM |
Node |
|
waffles |
14766 |
192.168.40.190 |
|
aysin |
16141 |
192.168.40.190 |
|
happie |
13851 |
192.168.40.190 |
|
dindin |
10464 |
192.168.40.180 |
|
timmie |
1602 |
192.168.40.170 |
|
cookies |
13754 |
192.168.40.190 |
|
pepper |
3936 |
192.168.40.170 |
|
buchappie |
7027 |
192.168.40.180 |
Obviously, it is not balanced for this very small data shall I say. However, for large and big data to manage, this is very efficiently distributed. With the addition of using Hash Tags, as mentioned earlier, there is more you can do to manage with what node (or technically the slot) you want to retain. For example:
192.168.40.170:6001> keys *
1) "pepper"
2) "timmie"
192.168.40.170:6001> CLUSTER KEYSLOT "pogiey{pet:cat}"
(integer) 3209
192.168.40.170:6001> CLUSTER KEYSLOT "pogiey"
(integer) 12253The keys reveal that there are “pepper” and “timmie” assigned on this node. Whereas, if I add “pogiey”, it shall be assigned to hash slot 12253, and that belongs to 10923 – 16383 range which is assigned to node 192.168.40.190. In order to make it stay or be consistent with the node where you want, using Hash Tags solves the problem as it forces the key to stay in that node where the string inside the { and } braces is the one computed for the hash slot.
Consider that node 192.168.40.190 goes down which has the most keys being stored in the current example I have. Obviously, it does not impact the performance since the Redis Cluster has its own high availability feature to do a failover and have the replica take over the failed master. For example, I stopped or killed the Redis server in node 192.168.40.190, I ended up with 192.168.40.210 taking over as the master since it is the replica of the 192.168.40.190 (previous and failed master). See below,
192.168.40.170:6001> cluster nodes
361e4fdd5a8f9e0eb0c594cc1ef797a07441c0f6 192.168.40.180:6001@16001 master - 0 1625005786259 2 connected 5461-10922
2bedffc625d87413758125d695ee53f69b14cc5f 192.168.40.210:6001@16001 master - 0 1625005786761 7 connected 10923-16383
2f35603cb4b0fc89241af0c0fc44b36181f9c298 192.168.40.190:6001@16001 master,fail - 0 1625005785657 3 connected
ea3f9475069cc8a93a26af8d649136ae1617f07c 192.168.40.221:6001@16001 slave f1502d9387e91c1e36cb0c309a5d57ac55bd74bb 0 1625005785254 1 connected
f1502d9387e91c1e36cb0c309a5d57ac55bd74bb 192.168.40.170:6001@16001 myself,master - 0 1625005785000 1 connected 0-5460
5fadaa2a1b3a06b0fcf88e29e754ed053dce8e9a 192.168.40.222:6001@16001 slave 361e4fdd5a8f9e0eb0c594cc1ef797a07441c0f6 0 1625005785254 2 connectedHighlighted in bold, it reveals that it can still continue to hold and provide the keys (ranging 10923 – 16383 hash slots) to the clients requesting, thus maintaining high performance status of the cluster. In case of the nodes holding the keys 10923 – 16383 (whose IP ends with 190 and 221), the cluster cannot work anymore. See below:
192.168.40.180:6001> set petnew "something here"
(error) CLUSTERDOWN The cluster is downAnd the Redis log shall reveal that it cannot proceed a quorum:
6669:M 29 Jun 2021 22:41:36.273 * Marking node 2f35603cb4b0fc89241af0c0fc44b36181f9c298 as failing (quorum reached).
6669:M 29 Jun 2021 22:41:36.273 # Cluster state changed: fail
6669:M 29 Jun 2021 22:41:43.318 * Marking node 2bedffc625d87413758125d695ee53f69b14cc5f as failing (quorum reached).
Since the master-replica that is managing the 10923-16383 hash slots is no longer available, the Redis Cluster consensus requires a quorum in order to run normally and healthy – it has to reach at least 3 master nodes running, and for the replica at least one available to do a failover.
Now, if you think of scaling up or let’s say replacing the nodes in a current cluster, there are commands such as SETSLOT, ADDSLOTS, and tools such as redis-cli available to help you out. Redis Cluster is really efficient when scaling up and down your cluster horizontally, or even doing maintenance when scaling vertically.
Conclusion
The hash slots vs consistent hashing reveal to be operating on a different level for providing the keys for data distribution, especially in a distributed computing environment. In this scenario, a sharded or data partitioned environment is where both algorithms are applicable to provide the most efficient way to manage the data. However, Hash Slots is the new approach but the algorithm is only applied when running Redis Cluster. On the other hand, if using the master-replica (or slave) mode, then relying on clients such as Twemproxy or Jedis for example shall rely on a consistent hashing algorithm. Obviously, the hash slots behave differently since it enforces consistency of the hashes for where the keys can be retrieved and it doesn’t require other extra services to run such as Redis Sentinel to provide failover for high availability. This is managed by Redis Cluster. Although there are pros and cons such that features might not be present in a Redis Cluster, scaling up and down makes it easier and also ensures performance and stability when using Redis Cluster. Thus, hash slots are more efficient in this manner.



