blog
mysqldump or Percona XtraBackup? Backup Strategies for MySQL Galera Cluster

Coming up with a backup strategy that does not affect database performance or lock your tables can be tricky. How do you backup your production database cluster without affecting your applications? Should you use mysqldump or Percona Xtrabackup? When should you use incremental backups? Where do you store the backups? In this blog post, we will cover some of the common backup methods for Galera Cluster for MySQL/MariaDB, and how you can get the most out of these.

Backup Method
There are various ways to backup your Galera Cluster data:
- xtrabackup (full physical backup)
- xtrabackup (incremental physical backup)
- mysqldump (logical backup)
- binary logging
- replication slave
Xtrabackup (full backup)
Xtrabackup is an open-source MySQL hot backup utility from Percona. It is a combination of xtrabackup (built in C) and innobackupex (built on Perl) and can back up data from InnoDB, XtraDB and MyISAM tables.
Xtrabackup does not lock your database during the backup process. For large databases (100+ GB), it provides much better restoration time as compared to mysqldump. The restoration process involves preparing MySQL data from the backup files before replacing or switching it with the current data directory on the target node. However, the restoration process is not very straightforward. We have covered some backup best practices and an example of how to restore with xtrabackup in this blog post.
ClusterControl allows you to schedule backups using Xtrabackup and mysqldump. It can store the backup files locally on the node where the backup is taken, or the backup files can also be streamed to the controller node and compressed on-the-fly.
Xtrabackup (incremental backup)
If you do not want to backup your entire database every single time, then you should look into incremental backup. Xtrabackup supports incremental backup where it can copy the data that has changed since the last backup. You can have many incremental backups between each full backup. For every incremental backup, you need information on the last one you did so it knows where to start the new one. Details on this works can be found here.
ClusterControl manages incremental backups, and groups the combination of full and incremental backups in a backup set. A backup set has an ID based on the latest full backup ID. All incremental backups after a full backup will be part of the same backup set, as seen in the screenshot below:
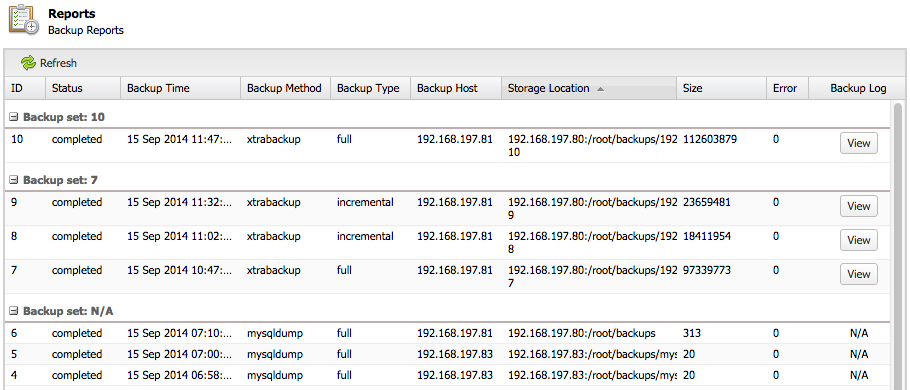
Note that without a full backup to start from, the incremental backups are useless.
mysqldump
This is probably the most popular backup method for MySQL. mysqldump is the perfect tool when migrating data between different versions or storage engines of MySQL, or when you need to change something in the text file dump before restoring it. Use it in conjunction with xtrabackup to give you more recovery options.
ClusterControl performs mysqldump against all databases by using the –single-transaction option. When using –single-transaction you will get a consistent backup for the Innodb tables without making database read only. So –single-transaction does not work if you have MyISAM tables (so these would be inconsistent). However when using Galera Cluster, all tables should be InnoDB (except the mysql system tables, but that is okay).
This means that using mysqldump is safe, but it has drawbacks. mysqldump will do, for each database and for each table, “SELECT * FROM
” and write the content to the mysqldump file. The problem with the “SELECT * FROM .. ” is if you have tables (and a data set/DB size) that does not fit in the innodb buffer pool. The active data set (that your application uses) will take a hit when the SELECT * FROM .. will load up data from disk, store the pages in the InnoDB buffer pool, and to do so, expunge pages part of the active data set from the InnoDB buffer pool, and put them on disk.
Hence you will get a performance degradation on that node, since the active data set is no longer in RAM but on DISK (if the InnoDB buffer pool is not large enough to fit the entire database).
If you want to avoid that, then use xtrabackup. Nevertheless, it is common to use –single-transaction and it does not block the nodes (except for a very short time when a START TRANSACTION is made, but that can be neglected). And yes, all nodes can still perform read and writes. But you will take a performance hit in the cluster while mysqldump is running – since CPU, DISK and RAM are used by the mysqldump process. A Galera Cluster is as fast the slowest running node.**
**Note that this is only true if “wsrep_desync=OFF”. When you allow the node to desync from the cluster momentarily, the cluster performance won’t get degraded for the duration of desync, which is suitable for backup workloads. However there is a risk if the node doesn’t get back in sync before desync is disabled, it still may cause some impact on the cluster.
Binary Logs
Binary logs can be used as incremental backups (particularly for mysqldump) as well for point-in-time recovery. ClusterControl will automatically perform mysqldump with –master-data=2 if it detects binary logging is enabled on the particular node. mysqldump will have a statement about binary log file and position in the dump file. Binary logs can eat up a significant amount of disk space so setting up an appropriate expire_log_days value is important. It is mandatory to enable log_slave_updates on a Galera node so events originating from the other cluster nodes are captured when local slave threads apply writesets.
To perform a point-in-time recovery of a Galera Cluster, please refer to this blog post.
Replication Slave
From MySQL 5.6 (or the equivalent MariaDB Cluster 10), it is possible to have a replication slave from a Galera cluster with GTID auto positioning. One approach is to run backups and ad-hoc analytical reporting on the slave, and therefore offload your Galera cluster. You can ensure the data integrity of the replicated data by performing regular checksums using, e.g., the Percona toolkit pt-table-checksum.
Setting up asynchronous replication from Galera cluster to standalone MySQL server is covered in this blog post.
Backup Locations
If you are using ClusterControl, you have a few options where you can store your backup.
Storing on Controller
Storing backups on the controller node provides a centralized backup storage outside of your Galera cluster. It might make sense to not use extra disk on your Galera nodes for this. You can also verify the correctness of the backups from the controller node. Make sure the controller has enough disk space, or else, mount an external storage device.
Storing on DB Node
You can store the backup files on the node where the backup is performed. This is a great approach if you have a dedicated Galera node as backup server, or if the backup directory is mounted on e.g a SAN. Storing the files on more than one DB node for redundancy purposes.
Storing in Cloud
ClusterControl has integration with AWS S3 and Glacier services, where you can upload and retrieve your backups using these services. This requires extra configurations on ClusterControl > Service Providers > AWS Credentials. Having your backups off-site, in the cloud, can be a good way to secure your backups against disaster.
Details on this can be found in the ClusterControl User Guide under Online Storage section. You can also easily transfer backups to remote locations using BitTorrent Sync.
How to determine which backup strategy to use?
Your backup strategy will depend on factors ranging from database size, growth and workload to hardware resources and non-functional requirements (e.g. need to do point-in-time recovery).
Recovery
Determine whether you need point-in-time recovery and enable binary logging on one or more Galera nodes. Running a server with binary logging enabled has an impact on performance. Binary logging also allows you to set up replication to a slave, which can be used for other purposes.
Database Size
ClusterControl tracks the growth of your databases, so you can see how your databases have grown over time. If your database fits in the InnoDB buffer pool, then mysqldump should not have a negative impact on the cluster performance.
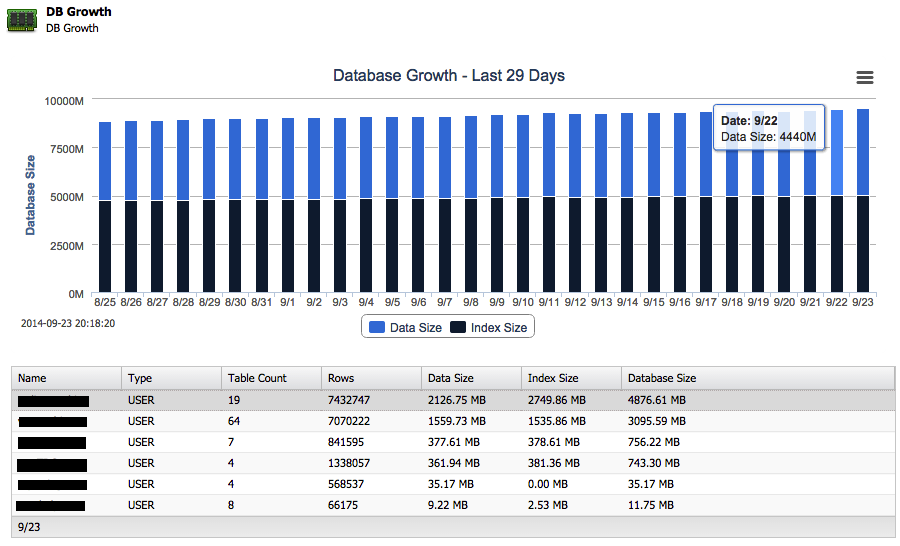
Database Usage
To determine frequency of backups, use the Cluster Load graph to determine the write load over the past weeks or months. You can use that to calculate the max amount of data that could potentially be lost if you lost your cluster and had to restore from the last backup.
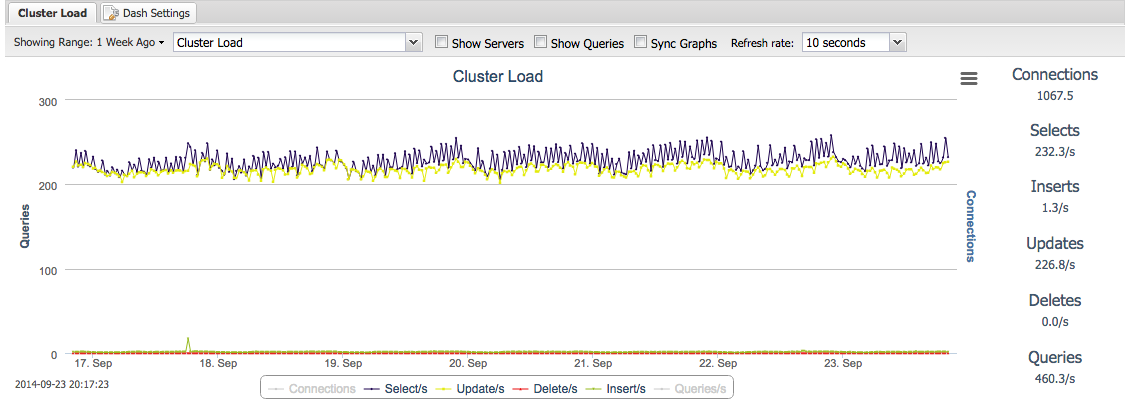
Backup policy
A backup policy could be as follows:
- Full backup (xtrabackup) every Sunday at 03:00
- Incremental backup (xtrabackup) Monday to Saturday at 03:00
mysqldump are also convenient to have, as they are easily transportable to other servers.
Make sure you backup your data before making significant changes, e.g, schema, software or hardware changes. In conjunction with binary logging then you will avoid data loss and you can at least revert to the position before the failed change (e.g an erroneous drop table).
If using binary logs, we recommend you set expire_log_days=X+1 in my.cnf, where X are the number of days between full backups.
Galera backup strategy
Use your monitoring data to understand the workload, and then plan your backup strategy. The following flowchart helps illustrate the decision process:
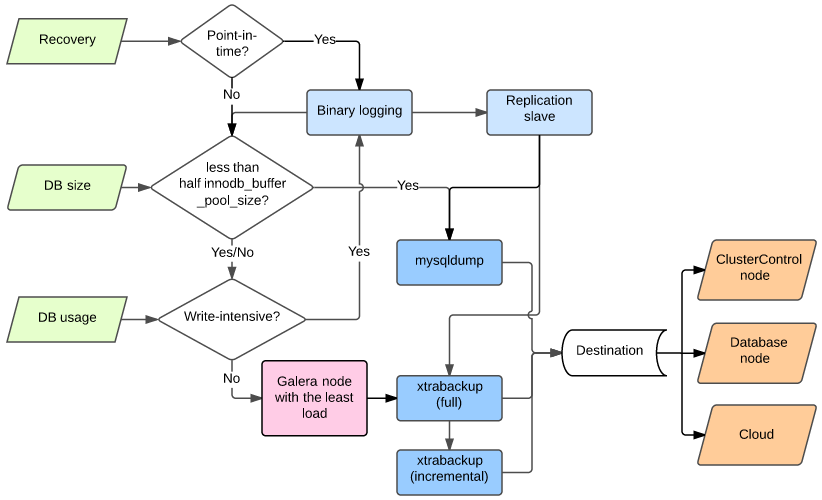
The flowchart above is work in progress, so any suggestions on improvements are very welcome. For instance, xtrabackup can be used in most circumstances.
Your database size and usage usually grows with time, and having a good backup strategy also becomes more important. So if you have not given it careful thought, perhaps now is a good time.



