blog
MySQL Replication and GTID-Based Failover – A Deep Dive Into Errant Transactions

For years, MySQL replication used to be based on binary log events – all a slave knew was the exact event and the exact position it just read from the master. Any single transaction from a master may have ended in different binary logs, and in different positions in these logs. It was a simple solution that came with limitations – more complex topology changes could require an admin to stop replication on the hosts involved. Or these changes could cause some other issues, e.g., a slave couldn’t be moved down the replication chain without time-consuming rebuild process (we couldn’t easily change replication from A -> B -> C to A -> C -> B without stopping replication on both B and C). We’ve all had to work around these limitations while dreaming about a global transaction identifier.
GTID was introduced along with MySQL 5.6, and brought along some major changes in the way MySQL operates. First of all, every transaction has an unique identifier which identifies it in a same way on every server. It’s not important anymore in which binary log position a transaction was recorded, all you need to know is the GTID: ‘966073f3-b6a4-11e4-af2c-080027880ca6:4’. GTID is built from two parts – the unique identifier of a server where a transaction was first executed, and a sequence number. In the above example, we can see that the transaction was executed by the server with server_uuid of ‘966073f3-b6a4-11e4-af2c-080027880ca6’ and it’s 4th transaction executed there. This information is enough to perform complex topology changes – MySQL knows which transactions have been executed and therefore it knows which transactions need to be executed next. Forget about binary logs, it’s all in the GTID.
So, where can you find GTID’s? You’ll find them in two places. On a slave, in ‘show slave status;’ you’ll find two columns: Retrieved_Gtid_Set and Executed_Gtid_Set. First one covers GTID’s which were retrieved from the master via replication, the second informs about all transactions which were executed on given host – both via replication or executed locally.
Setting up a Replication Cluster the Easy way
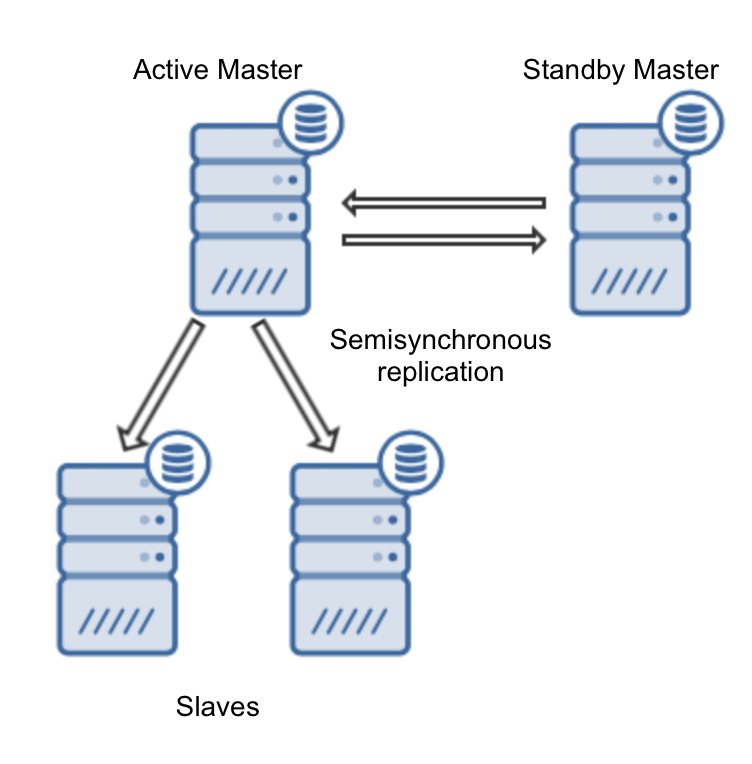
Deployment of MySQL replication cluster is very easy in ClusterControl (you can try it for free). The only prerequisite is that all hosts, which you will use to deploy MySQL nodes to, can be accessed from the ClusterControl instance using passwordless SSH connection.
When connectivity is in place, you can deploy a cluster by using the “Deploy” option. When the wizard window is open, you need to make couple of decisions – what do you want to do? Deploy a new cluster? Deploy a Postgresql node or import existing cluster.
We want to deploy a new cluster. We will then be presented with following screen in which we need to decide what type of cluster we want to deploy. Let’s pick replication and then pass the required details about ssh connectivity.
When ready, click on Continue. This time we need to decide which MySQL vendor we’d like to use, what version and couple of configuration settings including, among others, password for the root account in MySQL.
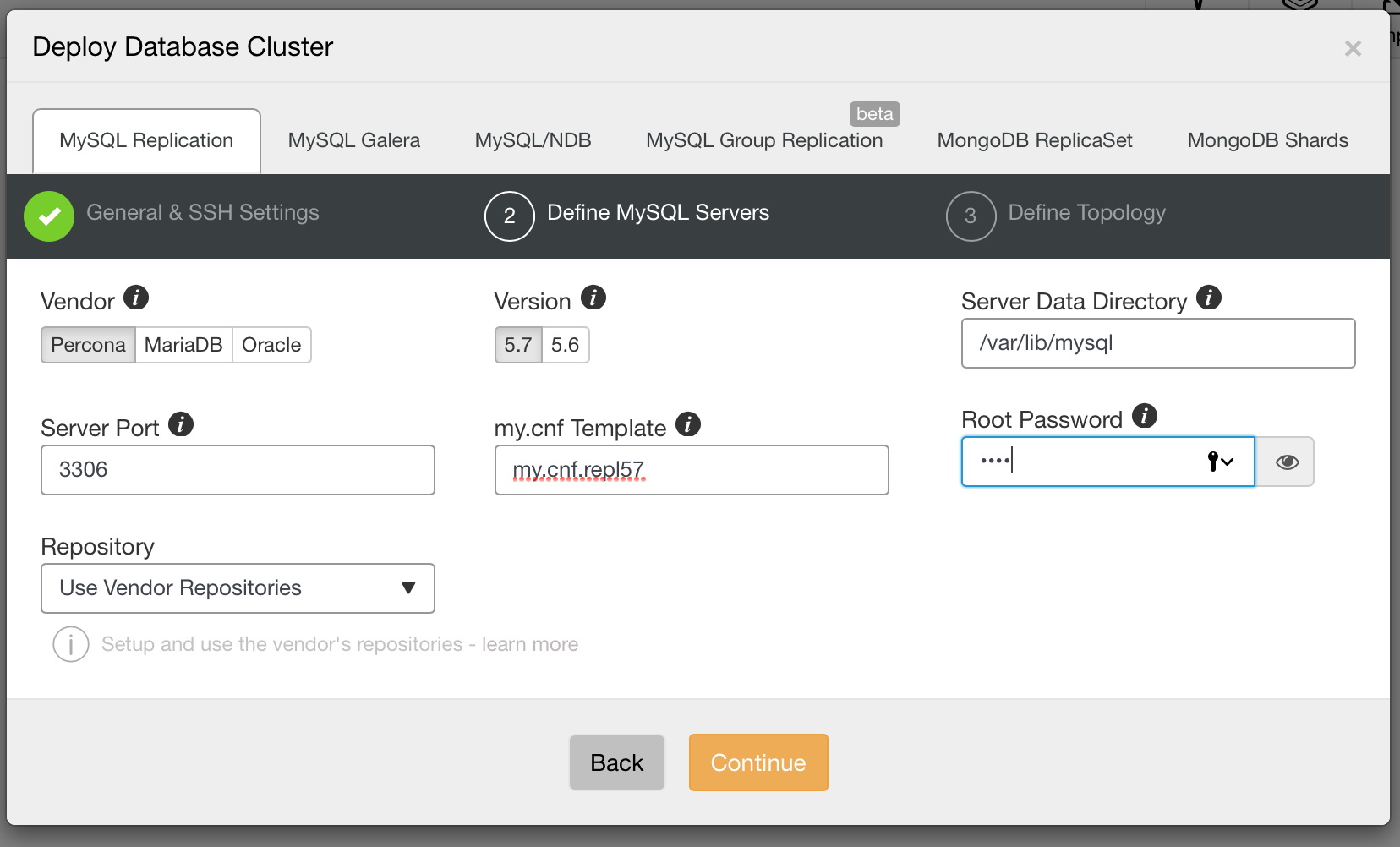
Finally, we need to decide on the replication topology – you can either use a typical master – slave setup or create more complex, active – standby master – master pair (+ slaves should you want to add them). Once ready, just click on “Deploy” and in couple of minutes you should have your cluster deployed.
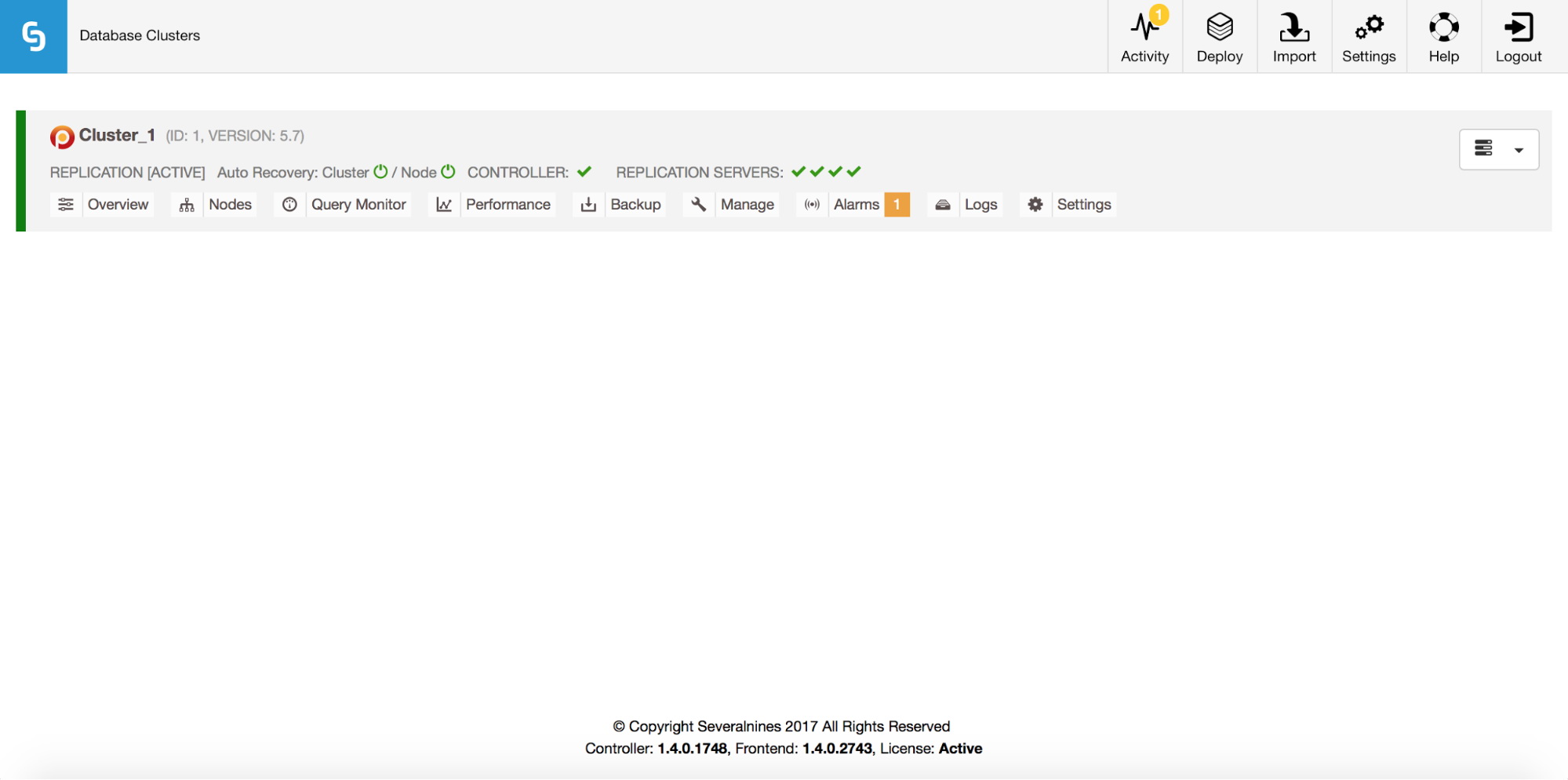
Once this is done, you will see your cluster in the cluster list of ClusterControl’s UI.
Having the replication up and running we can take a closer look at how GTID works.
Errant transactions – what is the issue?
As we mentioned at the beginning of this post, GTID’s brought a significant change in the way people should think about MySQL replication. It’s all about habits. Let’s say, for some reason, that an application performed a write on one of the slaves. It shouldn’t have happened but surprisingly, it happens all the time. As a result, replication stops with duplicate key error. There are couple of ways to deal with such problem. One of them would be to delete the offending row and restart replication. Other one would be to skip the binary log event and then restart replication.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Both ways should bring replication back to work, but they may introduce data drift so it is necessary to remember that slave consistency should be checked after such event (pt-table-checksum and pt-table-sync works well here).
If a similar problem happens while using GTID, you’ll notice some differences. Deleting the offending row may seem to fix the issue, replication should be able to commence. The other method, using sql_slave_skip_counter won’t work at all – it’ll return an error. Remember, it’s now not about binlog events, it’s all about GTID being executed or not.
Why deleting the row only ‘seems’ to fix the issue? One of the most important things to keep in mind regarding GTID is that a slave, when connecting to the master, checks if it is missing any transactions which were executed on the master. These are called errant transactions. If a slave finds such transactions, it will execute them. Let’s assume we ran following SQL to clear an offending row:
DELETE FROM mytable WHERE id=100;Let’s check show slave status:
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,And see where the 84d15910-b6a4-11e4-af2c-080027880ca6:1 comes from:
mysql> SHOW VARIABLES LIKE 'server_uuid'G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)As you can see, we have 29 transactions that came from the master, UUID of 966073f3-b6a4-11e4-af2c-080027880ca6 and one that was executed locally. Let’s say that at some point we failover and the master (966073f3-b6a4-11e4-af2c-080027880ca6) becomes a slave. It will check its list of executed GTID’s and will not find this one: 84d15910-b6a4-11e4-af2c-080027880ca6:1. As a result, the related SQL will be executed:
DELETE FROM mytable WHERE id=100;This is not something we expected… If, in the meantime, the binlog containing this transaction would be purged on the old slave, then the new slave will complain after failover:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'How to detect errant transactions?
MySQL provides two functions which come in very handy when you want to compare GTID sets on different hosts.
GTID_SUBSET() takes two GTID sets and checks if the first set is a subset of the second one.
Let’s say we have following state.
Master:
mysql> show master statusG
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Slave:
mysql> show slave statusG
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4We can check if the slave has any errant transactions by executing the following SQL:
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subsetG
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)Looks like there are errant transactions. How do we identify them? We can use another function, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as misingG
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)Our missing GTID’s are ab8f5793-b907-11e4-bebd-080027880ca6:3-4 – those transactions were executed on the slave but not on the master.
How to solve issues caused by errant transactions?
There are two ways – inject empty transactions or exclude transactions from GTID history.
To inject empty transactions we can use the following SQL:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)This has to be executed on every host in the replication topology that does not have those GTID’s executed. If the master is available, you can inject those transactions there and let them replicate down the chain. If the master is not available (for example, it crashed), those empty transactions have to be executed on every slave. Oracle developed a tool called mysqlslavetrx which is designed to automate this process.
Another approach is to remove the GTID’s from history:
Stop slave:
mysql> STOP SLAVE;Print Executed_Gtid_Set on the slave:
mysql> SHOW MASTER STATUSGReset GTID info:
RESET MASTER;Set GTID_PURGED to a correct GTID set. based on data from SHOW MASTER STATUS. You should exclude errant transactions from the set.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Start slave.
mysql> START SLAVEGIn every case, you should verify consistency of your slaves using pt-table-checksum and pt-table-sync (if needed) – errant transaction may result in a data drift.
Failover in ClusterControl
Starting from version 1.4, ClusterControl enhanced its failover handling processes for MySQL Replication. You can still perform a manual master switch by promoting one of the slaves to master. The rest of the slaves will then fail-over to the new master. From version 1.4, ClusterControl also have the ability to perform a fully-automated failover should the master fail. We covered it in-depth in a blog post describing ClusterControl and automated failover. We’d still like to mention one feature, directly related to the topic of this post.
By default, ClusterControl performs failover in a “safe way” – at the time of failover (or switchover, if it’s the user who executed a master switch), ClusterControl picks a master candidate and then verifies that this node does not have any errant transactions which would impact replication once it is promoted to master. If an errant transaction is detected, ClusterControl will stop the failover process and the master candidate will not be promoted to become a new master.
If you want to be 100% certain that ClusterControl will promote a new master even if some issues (like errant transactions) are detected, you can do that using the replication_stop_on_error=0 setting in cmon configuration. Of course, as we discussed, it may lead to problems with replication – slaves may start asking for a binary log event which is not available anymore.
To handle such cases, we added experimental support for slave rebuilding. If you set replication_auto_rebuild_slave=1 in the cmon configuration and your slave is marked as down with the following error in MySQL, ClusterControl will attempt to rebuild the slave using data from the master:
Got fatal error 1236 from master when reading data from binary log: ‘The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.’
Such a setting may not always be appropriate as the rebuilding process will induce an increased load on the master. It may also be that your dataset is very large and a regular rebuild is not an option – that’s why this behavior is disabled by default.



