blog
An Overview of MySQL Database High Availability

There are many many approaches to MySQL high availability – from traditional, loosely-coupled database setups based on asynchronous replication to more modern, tightly-coupled architectures based on synchronous replication. These offer varying degrees of protection, and DBAs almost always have to choose a tradeoff between high-availability and cost.
This is the third installment in the ‘Become a MySQL DBA’ series, and discusses the pros and cons of different approaches to high availability in MySQL. Our previous posts in the DBA series include Backup and Restore and Monitoring & Trending.
High Availability – What Does it Mean?
Availability is somewhat self-explanatory. If your database can be queried by your application, it is available. High, on the other hand, is a separate story. For some organizations, ‘high’ means max several minutes of downtime over the year. For others, it might mean a few hours per month. If you’ve read the previous blogs in this series, you may have noticed a pattern – “it depends on the business requirements”. This applies here also – you need to know your requirements in terms of how long downtime you can accept as it may limit your HA options significantly. What you need to keep in mind is that the length of a database incident, that causes some disturbance in database access, may be related to the HA method you choose. On the other hand, whether this disturbance affects end users is a different thing. For starters – does your application use a cache? How often does it need to be refreshed? Is it acceptable for your application to show stale data for some period of time? And for how long?
Caching Layer – For Database Reads and Writes?
A cache that sits between the application and the database might be a way of decoupling those two from each other.
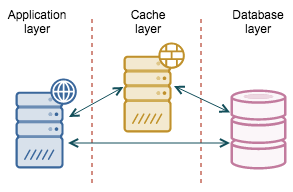
For reads you can use one of many cache solutions – memcached, Redis, couchbase. Cache refresh can be performed by a background thread which, when needed, gets the data out of MySQL and stores it in the caching layer. It could be that the data is outdated because the database is not reachable and the background thread is not able to refresh the cache. While the database is down, the application serves the data out of cache – as long as it’s ok to serve stale data for some time, you are just fine and users may not even experience any issues.
With writes, it is a similar story – you may want to cache writes in a queue. In the background, you would have threads that read the data out of the queue and store them into the database. Ideally those background threads keep the queue empty and any write request is handled immediately. If the database is down, the queue can serve as a write buffer – the application can still make modifications to the data but the results are not immediately stored in the database – they will be later on, when the database gets back online and the background threads start working on the backlog.
There are many ways to keep users happy and unaware of the issues behind the scenes – all user-related modifications can be immediately presented to the user, to give an impression that everything is just fine. Other users will not see those changes until the write queue is flushed to the database. Of course, it depends on what kind of data we are talking about – in many cases (e.g., social media site, web forum, chat engine, comment engine), it might be just fine. One way or another, this “illusion” can be maintained only for some period of time though. Eventually, the database has to be brought up again. Let’s talk now about our options for database high availability.
Block-Level Replication (DRBD)
We’ll start with DRBD – Distributed Replicated Block Device. In short, imagine that you could create a RAID1 over the network. This is, more or less, what DRBD does. You have two nodes (or three in the latest versions), each of them have a block device dedicated to storing data. One of them is in active mode, mounted and basically works as a database server. The rest of them are in passive standby mode – any changes made on the active node’s block device are replicated to the passive nodes and applied. Replication can be synchronous, asynchronous or memory synchronous. The point of this exercise is that, should the active node fail, the passive nodes have an exact copy of the data (if you use replication in synchronous mode, that is). You can then promote a passive node to active, mount the block volume, start the services you want (like, MySQL for example), and you have a replacement node up and running.
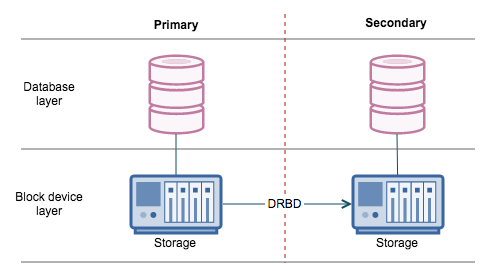
There are couple of disadvantages in the DRBD setup. One of them is the active – passive approach. It’s a problem on multiple layers. For starters, you have to have two nodes while you can use only one of them. You cannot use the passive node for ad-hoc or reporting queries, you cannot take backups off it. Additionally, fail-over equals to starting a crashed MySQL (like someone just pulled the power plug) – InnoDB recovery will kick in and while data may not be lost (subject to InnoDB’s durability settings), the process may take significant amount of time, workload depending. Once the node is up, it willl need some time to warm up – you can’t prewarm it as it is not active. Last but not least, we are talking about 1:1 or 1:2 setups – only one active node and one or two copies. Theoretically you could use DRBD to keep a copy of master -> slave setup but we haven’t seen it in production nor it makes sense from a cost point of view.
MySQL Replication
MySQL replication is one of the oldest and probably the most popular way of achieving MySQL high availability. The concept is simple – you have a master that replicates to one or more slaves. If a slave goes down, you use another slave. If the master is down, you promote one of the slaves to act as a new master. When you get into details, though, things become more complex.
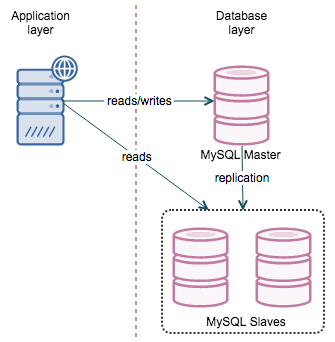
Master failover consists of several phases:
- You need to locate the most advanced slave
- If there are more of them, pick one as a new master and reslave the rest to the new master
- If there is only one “most advanced” slave, you should try to identify missing transactions and replay them on the rest of the slaves to get them in sync
- If #3 is not possible, you’ll have to rebuild slaves from scratch, using the data from the new master
- Perform the switch (change proxy configuration, move virtual IP, anything you need to move the traffic to the new master)
This is a cumbersome process and while it’s possible to manually perform all the steps, its very easy to make mistakes. There are options to automate it, though. One of the best solutions is MHA – a tool which handles the failover, forced or planned, it doesn’t matter. It is designed to find a slave that is the most up to date compared with the master. It will also try to apply any missing transactions to this slave (if the binary logs on the master are available). Finally, it should reslave all of the slaves, wherever possible, to the new master. MMM is another solution that performs failover, although this might not work well for some users.
Along with MySQL 5.6, Oracle introduced Global Transaction Identifiers and this opened a whole new world for HA possibilities in MySQL replication. For starters, you can easily reslave any slave to any master – something which had not been possible with regular replication. There is no need to check binlog positions, all you need to know is CHANGE MASTER TO … MASTER_AUTO_POSITION=1; Even though the reslaving part is easy, you still have to keep an eye on the slave’s status and determine which one will be the best candidate for a master. Regarding tooling: MHA can be used in GTID replication in a similar way as with regular replication. In addition, in such setup it is possible to use binlog servers as a source of missing transactions. Oracle also created a tool – mysqlfailover which performs periodical or constant health checks for the system and has support for both automated and user-initiated failover.
The main issue with standard MySQL replication is that by default it is asynchronous which means, in short, that in the event of master’s crash, it is possible that not all transactions were replicated to at least one of the slaves. If a master is not accessible (so tools like MHA can’t parse its binlogs to extract missing data), it means that this data is lost. To eliminate this problem, semi-sync replication was added to MySQL. It ensures that at least one of the slaves got the transaction and wrote it in its relay logs. It may be lagging but the data is there. Therefore, if you use MySQL replication, you may consider setting up one of your slaves as a semi-sync slave. This is not without impact, though – commits will be slower since the master needs to wait for the semi-sync slave to log the transactions. Still, its something that you may want to consider – it is possible that for your workload it won’t make a visible difference. By default, ClusterControl works in this mode with MySQL replication. If you are using GTID-based failover, you should also be aware of Errant Transactions.
Clustering
The ultimate solution to HA is to use a synchronous (or at least “virtually” synchronous) cluster. This leads us to MySQL Cluster and Galera (in all it’s flavors).
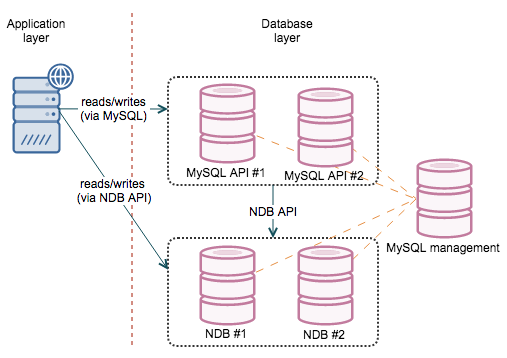
MySQL Cluster is based on the NDB engine and delivers great point-select performance or inserts. It provides internal redundancy for the data as well as in connectivity layer. This is one of the best solutions, as long as it is feasible to use in your particular case. This is also its main issue – it is not your regular MySQL/InnoDB and behaves differently. The way it stores data (partitioned across multiple data nodes) makes some of the queries much more expensive as there is quite a bit of network activity needed to grab the data and prepare a result. More information in our MySQL Cluster training slides.
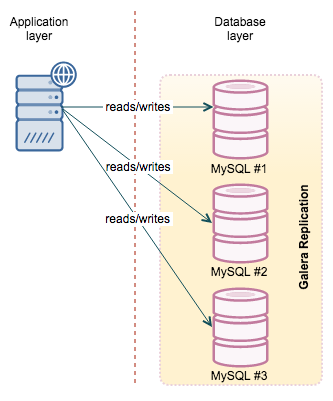
Galera, be it Codership’s vanilla version, MariaDB Cluster or Percona XtraDB Cluster, much closer resembles MySQL with InnoDB. Actually, it does use InnoDB as storage engine. There are a couple of things to keep an eye on (very big transactions, DDL’s) but for most of the cases, it is the same MySQL/InnoDB that we are used to. Galera does not split the data, it uses multiple nodes, each has a full copy of the dataset – similar concept to the master/slave. The main difference is that the replication protocol is “virtually” synchronous which means that the data is almost immediately available across the cluster – there is no slave lag. Another important aspect, when comparing Galera to NDB cluster, is the fact that every node has a full dataset available. It makes it harder to scale (you can’t add more nodes to add more data capacity of the cluster) but on the other hand, it is easier to run all kind of queries, reporting included – no need to move the data across the network. More information on this online tutorial for Galera Cluster.
Both clusters, practically speaking (there are some exceptions on both sides), work as a single instance. Therefore it is not important which node you connect to as long as you get connected – you can read and write from any node.
From those options, Galera is a more likely choice for the common user – its workload patterns are mostly close to the standalone MySQL, maintenance is also somewhat similar to what users are used to do. This is one of the biggest advantages of using Galera. MySQL Cluster (NDB) may be a great fit for your needs but you have to do some testing to ensure its indeed the case. This webinar discusses the differences between Galera and NDB.
Proxy Layer
Having MySQL setup one way or another is not enough to achieve high availability. Next step would be to solve another problem – how should I connect to the database layer so I’ll always connect to hosts which are up and available?
Here, a proxy layer can be very useful. There are couple of options to pick from.
HAProxy
HAProxy is probably the most popular software proxy out there, at least in MySQL world. It is fast, easy to configure and there are numerous howto’s and config snippets in the Internet which makes it easy to set it up. On the other hand, HAProxy does not have any sophisticated database logic and is not aware of what’s going on in MySQL or Galera Cluster. It can check MySQL’s port but that’s all – it’s either up or down. It can be a serious problem for both regular replication and setups based on Galera Cluster.
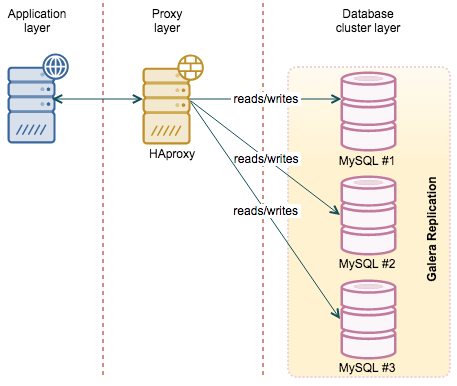
Regular replication has two types of hosts – master, serving reads and writes, and read-only slaves. If we set up an automated failover using, for example, MHA, it may happen that the master is no longer a master and one of the slaves is no longer a slave. Proxy configuration has to be changed, ideally – dynamically. Galera cluster, on the other hand, has nodes which may be in various states. A node can be a donor, serving data to the joining node. A node can be joining the cluster. A node also can be desynced manually (for example, during the time you’re taking a backup). Finally, a node can be in non-Primary state. It is not a 0/1 situation – we may want to avoid nodes which are in the donor state as they do significant amount of I/O and it can cause impact to production. We also do not want to use joining nodes as they most likely are not up to date in terms of executed writesets. More details can be found in this webinar on HAProxy.
HAProxy, out of the box, do not have any options to handle such cases. It has a feature which we may utilize to enhance its abilities – HTTP check. Basically, instead of checking if a given port is open or close, HAProxy may do a HTTP connection to a given port. It it receives 200 code, it assumes that the service is up. Any other code, let’s say 503 (which is pretty popular in scripts) will trigger ‘service down’ state. This, along with xinetd and a simple (or more complex) script allows a DBA to implement more complex logic behind the scenes. The script may check the MySQL replication topology and return the correct error code depending on whether a host is a slave or not, depending on which backend is used (usually we define one backend for a master and one for all slaves, as described here). For Galera, it may check the node’s state and, based on some logic, decide if it’s ok to serve reads from the node or not.
MaxScale
One of the latest additions to the MySQL ecosystem is MaxScale, a proxy developed by MariaDB Corporation. The main difference over HAProxy is that MaxScale is database-aware. It was designed to work with MySQL and it gives a DBA more flexibility. It also has a significant number of features, in addition to being a proxy. For example, should you need a binlog server, MaxScale may help you here. From an HA point of view though, the most important feature is its ability to understand MySQL states. If you use regular replication, MaxScale will be able to determine which node is the master and which one is a slave. In case of failover, this makes one less config change to keep in mind. In case of Galera Cluster, MaxScale has the ability to understand which node is joined and which is not. This helps to keep traffic away from nodes which are, for example, receiving incremental state transfer. If you have Galera, MaxScale also picks up one of the nodes as a “master” even though there is no “master” in a sense of normal replication. It is still very useful – in case you’d like to perform a read/write split (to avoid deadlocks, for example), you can rely on the proxy to direct your writes to a single node in the cluster while the reads will hit the other nodes. We previously blogged about how to deploy/configure MaxScale.
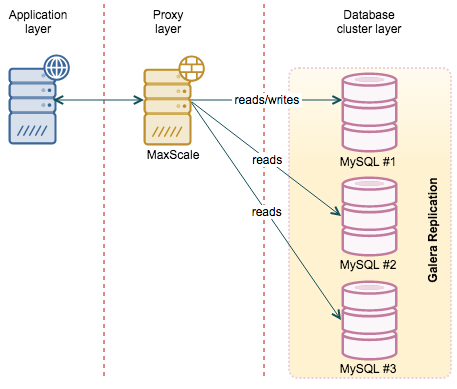
There are also some issues with MaxScale that you need to be aware of. Even though it is GA, it is relatively new software. Therefore detailed tests should be carried out to check if the features that you will rely upon do work as advertised. Another problem, somehow connected, is that MaxScale uses quite a bit of CPU. It is understandable as some of the features require processing power, but it may be a limitation for environments with larger traffic. We assume that eventually, this will be optimized but for now, this is something you need to keep in mind. You might want to check out performance benchmark MaxScale vs HAProxy.
HA for Proxies
So, here we are, our database and proxy layers are up and running. Proxies are configured to split the workload across the database layer, ensuring that traffic is served even if some of the database instances are down. Next problem to solve is – what happens if your proxy goes down? How do you route traffic to your databases?
If you use Amazon Web Services, Elastic Load Balancer (ELB) is a great tool to solve this problem. All you need to do is to set it up with proxy nodes as backend and you are all good. Under the hood AWS will create several ELB instances that will be highly available and will route the traffic to those proxy nodes which are up.
If you do not use AWS, you may need to develop some other method. One of them could be to have a virtual IP assigned to one of the proxy instances. If the instance is down, the IP will be moved to another proxy. Keepalived is one of the tools that could provide this kind of functionality, but there are others as well. One of the advantages of this setup is that you only have two proxy nodes on which you need to introduce configuration changes (as compared to a number of instances, as described in the next paragraph). Two nodes is the minimal requirement for HA. The disadvantage is that only one of them will be up at any given time – this could be a limitation if the workload is high.
Another approach could be to collocate proxy servers on application servers. Then you can configure the application to connect to the database nodes using a proxy installed on localhost. The reasoning behind it is that by sharing hardware we minimize the chance that the proxy will be down while application server will be up. It is more probable that both services will be either up or down and if a given application instance works, it will be able to connect to the proxy. The main advantage of this setup is that we have multiple proxy nodes, which helps to scale. On the other hand, it is more cumbersome to maintain – any configuration changes have to be introduced on every node.
Do We Need a Proxy Layer?
While a proxy layer is useful, it is not required. It’s especially true if we are talking about Galera Cluster. In such case you can as well read and write to any of the nodes and if a given node doesn’t respond, you can just skip it and move the next one. You may encounter issues with deadlocks but as long as you are ok with it (or you can work around them), there’s no need to add additional complexity. If you’d like to perform an automated failover in MySQL replication, things are different – you have a single point where you can write – a master. One of possibilities is to use a virtual IP as a point where the application can write. Then you can move it from host to host, following the replication chain changes, ensuring that it always points to the current master.
Split-Brain Scenarios
There are cases where issues in communication between data replicas may lead to two separate data sets, each one randomly serving applications without coordinating with the other one.
Let’s take a look at the simplest example – one master, two slaves, VIP pointing to the master, automated failover.
- Master loses network connection
- Failover is deemed as needed
- one of the slaves is staged to be a new master
- the other slave is reslaved
- VIP is assigned to the new master.
So far so good. There’s a ticking bomb hidden in the basement, though. The old master lost the network connection – this was main reason for the failover, but it also means that it was not possible to connect to it and take down the VIP. If its connection recovers, you’ll end up with two hosts having the same VIP. For a while at least, as you would probably have some scripts to detect such a situation and take down VIP on the old master. During this short time, some of the writes will hit the old master creating a data mismatch.
It’s hard to get protected against such situation. What you want to do is to have a STONITH implemented (Shoot The Other Node In The Head, one of the nicest acronyms in IT). Basically, you want to ensure that after a successful failover, the former master is down as in “down and will never come back up”. There are numerous ways to achieve this and it mostly depends on your environment. Barebone servers are more flexible here.
You may want to use a separate network to form a “backup” link – one switch, couple of patchcords. Something disconnected from main network, routers etc. You can use such a connection to check the health of the other node – maybe it’s just a primary network that failed? Such dedicated connection can also be used for a IPMI or some other KVM-ish access. Maybe you have access to the manageable power strip and you can turn off a power outlet? There are many ways to shutdown the server remotely if you are in the datacenter. In a cloud environment, things are different but the least you could do is to utilize different NIC’s and create a bonded interface (keeping fingers crossed that, behind the scenes, they do not use exactly the same hardware). If using AWS, you can also try and stop the node using the EC2 CLI.
We are aware that this topic is more suitable for a book than a mere blog post. High Availability in MySQL is a complex topic which requires plentiful of research and depends heavily on the environment that you use. We’ve tried to cover some of the main aspects, but do not hesitate to hit the comment button and let us know your thoughts.



