blog
Architecting for Failure – Disaster Recovery of MySQL Galera Cluster

Failure is a fact of life, and cannot be avoided. No IT vendor in their right mind will claim 100% system availability, although some might claim several nines 🙂 We might have armies of ops soldiers doing everything they possibly can to avoid failure, yet we still need to prepare for it. What do you do when the sh*t hits the fan?
![]()
Whether you use unbreakable private datacenters or public cloud platforms, Disaster Recovery (DR) is indeed a key issue. This is not about copying your data to a backup site and being able to restore it, this is about business continuity and how fast you can recover services when disaster strikes.
In this blog post, we will look into different ways of designing your Galera Clusters for fault tolerance, including failover and failback strategies.
Disaster Recovery (DR)
Disaster recovery involves a set of policies and procedures to enable the recovery or continuation of infrastructure following a natural or human-induced disaster. A DR site is a backup site in another location where an organization can relocate following a disaster, such as fire, flood, terrorist threat or other disruptive event. A DR site is an integral part of a Disaster Recovery/Business Continuity plan.
Most large IT organizations have some sort of DR plan, not so for smaller organisations though – because of the high cost vs the relative risk. Thanks to the economics of public clouds, this is changing though. Smaller organisations with tighter budgets are also able to have something in place.
Setting up Galera Cluster for DR Site
A good DR strategy will try to minimize downtime, so that in the event of a major failure, a backup site can instantly take over to continue operations. One key requirement is to have the latest data available. Galera is a great technology for that, as it can be deployed in different ways – one cluster stretched across multiple sites, multiple clusters kept in sync via asynchronous replication, mixture of synchronous and asynchronous replication, and so on. The actual solution will be dictated by factors like WAN latency, eventual vs strong data consistency and budget.
Let’s have a look at the different options to deploy Galera and how this affects the database part of your DR strategy.
Active Passive Master-Master Cluster
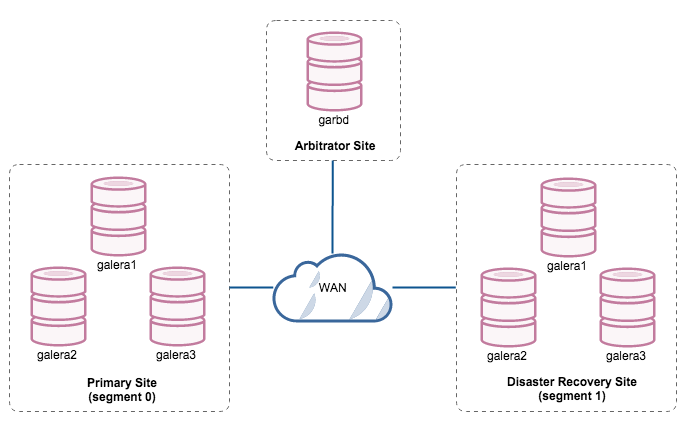
This consists of 6 Galera nodes on two sites, forming a Galera cluster across WAN. You would need a third site to act as an arbitrator, voting for quorum and preserving the “primary component” if the primary site is unreachable. The DR site should be available immediately, without any intervention.
Failover strategy:
- Redirect your traffic to the DR site (e.g. update DNS records, etc.). The assumption here is that the DR site’s application instances are configured to access the local database nodes.
Failback strategy:
- Redirect your traffic back to primary site.
Advantages:
- Failover and failback without downtime. Applications can switch to both sites back and forth.
- Easier to switch side without extra steps on re-bootstrapping and reprovisioning the cluster. Both sites can receive reads/writes at any moment provided the cluster is in quorum.
- SST (or IST) during failback won’t be painful as a set of nodes is available to serve the joiner on each site.
Disadvantages:
- Highest cost. You need to have at least three sites with minimum of 7 nodes (including garbd).
- With the disaster recovery site mostly inactive, this would not be the best utilisation of your resources.
- Requires low and reliable latency between sites, or else there is a risk for lag – especially for large transactions (even with different segment IDs assigned)
- Risk for performance degradation is higher with more nodes in the same cluster, as they are synchronous copies. Nodes with uniform specs are required.
- Tightly coupled cluster across both sites. This means there is a high level of communication between the two sets of nodes, and e.g., a cluster failure will affect both sites. (on the other hand, a loosely coupled system means that the two databases would be largely independent, but with occasional synchronisation points)
Active Passive Master-Master Node
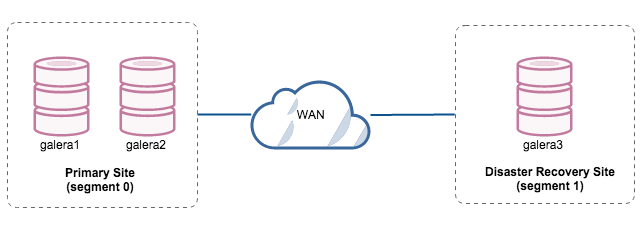
Two nodes are located in the primary site while the third node is located in the disaster recovery site. If the primary site is down, the cluster will fail as it is out of quorum. galera3 will need to be bootstrapped manually as a single node primary component. Once the primary site comes back up, galera 1 and galera2 need to rejoin galera3 to get synced. Having a pretty large gcache should help to reduce the risk of SST over WAN.
Failover strategy:
- Bootstrap galera3 as primary component running as “single node cluster”.
- Point database traffic to the DR site.
Failback strategy:
- Let galera1 and galera2 join the cluster.
- Once synced, point database traffic to the primary site.
Advantages:
- Reads/writes to any node.
- Easy failover with single command to promote the disaster recovery site as primary component.
- Simple architecture setup and easy to administer.
- Low cost (only 3 nodes required)
Disadvantages:
- Failover is manual, as the administrator needs to promote the single node as primary component. There would be downtime in the meantime.
- Performance might be an issue, as the DR site will be running with a single node to run all the load. It may be possible to scale out with more nodes after switching to the DR site, but beware of the additional load.
- Failback will be harder if SST happens over WAN.
- Increased risk, due to tightly coupled system between the primary and DR sites
Active Passive Master-Slave Cluster via Async Replication
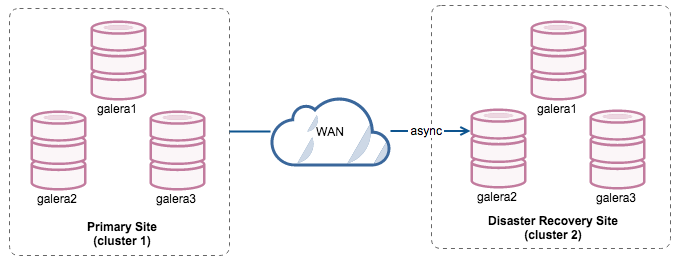
This setup will make the primary and DR site independent of each other, loosely connected with asynchronous replication. One of the Galera nodes in the DR site will be a slave, that replicates from one of the Galera nodes (master) in the primary site. Ensure that both sites are producing binary logs with GTID and log_slave_updates is enabled – the updates that come from the asynchronous replication stream will be applied to the other nodes in the cluster.
By having two separate clusters, they will be loosely coupled and not affect each other. E.g. a cluster failure on the primary site will not affect the backup site. Performance-wise, WAN latency will not impact updates on the active cluster. These are shipped asynchronously to the backup site. The DR cluster could potentially run on smaller instances in a public cloud environment, as long as they can keep up with the primary cluster. The instances can be upgraded if needed.
It’s also possible to have a dedicated slave instance as replication relay, instead of using one of the Galera nodes as slave.
Failover strategy:
- Ensure the slave in the DR site is up-to-date (up until the point when the primary site was down).
- Stop replication slave between slave and primary site. Make sure all replication events are applied.
- Direct database traffic on the DR site.
Failback strategy:
- On primary site, setup one of the Galera nodes (e.g., galera3) as slave to replicate from a (master) node in the DR site (galera2).
- Once the primary site catches up, switch database traffic back to the primary cluster.
- Stop the replication between primary site and DR site.
- Re-slave one of the Galera nodes on DR site to replicate from the primary site.
Advantages:
- No downtime required during failover/failback.
- No performance impact on the primary site since it is independent from the backup site.
- Disaster recovery site can be used for other purposes like data backup, binary logs backup and reporting or large analytical queries (OLAP).
Disadvantages:
- There is a chance of missing some data during failover if the slave was behind.
- Pretty costly, as you have to setup a similar number of nodes on the disaster recovery site.
- The failback strategy can be risky, it requires some expertise on switching master/slave role.
Active Passive Master-Slave Replication Node
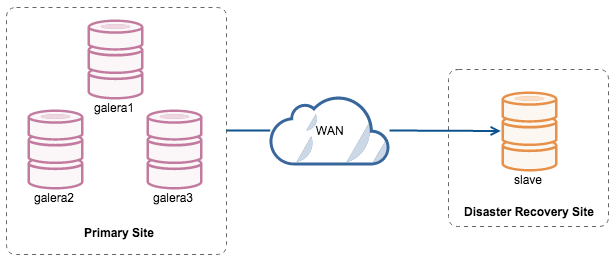
Galera cluster on the primary site replicates to a single-instance slave in the DR site using asynchronous MySQL replication with GTID. Note that MariaDB had a different GTID implementation, so it has slightly different instructions.
Take extra precaution to ensure the slave is replicating without replication lag, to avoid any data loss during failover. From the slave point-of-view, switching to another master should be easy with GTID.
Failover to DR site:
- Ensure the slave has caught up with the master. If it does not and the primary site is already down, you might miss some data. This will make things harder.
- If the slave has READ_ONLY=on, disable it so it can receive writes.
- Redirect database traffic to the DR site
Failback to primary site:
- Use xtrabackup to move the data from the DR site to a Galera node on primary site – this is online process which may cause some performance drops but it’s non-blocking for InnoDB-only databases
- Once data is in place, slave the Galera node off the DR host using the data from xtrabackup
- At the same time, slave the DR site off the Galera node – to form master-master replication
- Rebuild the rest of the Galera cluster using either xtrabackup or SST
- Wait until primary site catches up on replication with DR site
- Perform a failback by stopping the writes to DR, ensure that replication is in sync and finally repoint writes to the production
- Set the slave as read-only, stop the replication from DR to prod leaving only prod -> DR replication
Advantages:
- Replication slave should not cause performance impact to the Galera cluster.
- If you are using MariaDB, you can utilize multi-source replication, where the slave in the DR site is able to replicate from multiple masters.
- Lowest cost and relatively faster to deploy.
- Slave on disaster recovery site can be used for other purposes like data backup, binary logs backup and running huge analytical queries (OLAP).
Disadvantages:
- There is a chance of missing data during failover if the slave was behind.
- More hassle in failover/failback procedures.
- Downtime during failover.
The above are a few options for your disaster recovery plan. You can design your own, make sure you perform failover/failback tests and document all procedures. Trust us – when disaster strikes, you won’t be as cool as when you’re reading this post.



