blog
How to Setup Streaming Replication for High Availability with PostgresSQL 9.0
Master – slave replication
PostgreSQL historically did not have support for replication – replication was provided using external tools like Pgpool and Slony. Since these solutions did not come out of the box, most of them required quite some work to set them up. This was a serious drawback, and it made people look into MySQL, where replication has been available for a long time.
Starting with PostgreSQL 9.0, replication has been added natively to PostgreSQL – streaming of WAL has been chosen as a method to move data between master and slave. Let’s take a look at how you can add a slave to the standalone PostgreSQL master.
You will need to have two hosts with PostgreSQL. In our case, the master will have IP of 10.0.0.101 and our slave-to-be will have IP of 10.0.0.102. Let’s assume 10.0.0.101 has PostgreSQL up and running. We also have an instance running on 10.0.0.102, and we will stop the service to add it as a slave.
First – grants. We need to create a user that we will use for the replication. On the master, we’ll run:
postgres=# CREATE ROLE repl WITH REPLICATION PASSWORD 'password' LOGIN;
CREATE ROLENext, we need to add the following entry to pg_hba.conf file on the master and reload PostgreSQL:
host replication repl 10.0.0.102/32 md5
service postgresql reloadWe can also add a similar entry to our slave’s pg_hba.conf – it may come in handy in the future if we promote it to a master:
host replication repl 10.0.0.101/32 md5Next, we need to make a couple of changes in postgresql.conf on both master and a slave. Some of them are needed only in case our master would become a slave at some point – we want to make them beforehand.
- wal_level – set it to hot_standby
- max_wal_senders – it should be set to more than the number of current slaves
- checkpoint_segments – value bigger than default 3. 16 may be a good start
- wal_keep_segments – same value as checkpoint_segments
- hot_standby – enable it
Next step would be to transfer the data from the master to the slave. To accomplish that, we are going to use pg_basebackup tool but first we need to remove current contents of the data directory on our slave- to-be:
rm -rf /var/lib/postgresql/9.4/main/*Once it’s done, we execute pg_basebackup on our slave:
pg_basebackup --xlog-method=stream -D /var/lib/postgresql/9.4/main/ -U repl -h 10.0.0.101Once the command finishes, you should see new data in PostgreSQL’s data directory on the slave. There are a couple of steps left, though. We need to prepare a recovery.conf file which will let our slave connect to the master. A file with the following content has to be created in /var/lib/postgresql/9.4/main/recovery.conf:
standby_mode = 'on'
primary_conninfo = 'host=10.0.0.101 port=5432 user=repl password=password'
trigger_file = '/tmp/failover.trigger'Finally, we have to make sure all privileges are set correctly on the PostgreSQL data directory. We are now all set to start our slave.
chmod -R g-rwx,o-rwx /var/lib/postgresql/9.4/main/ ; chown -R postgres.postgres /var/lib/postgresql/9.4/main/
service postgresql startWe can now confirm from our master that slave has connected and is replicating:
$ psql
psql (9.4.8)
Type "help" for help.
postgres=# select client_addr, state, sent_location, write_location,
postgres-# flush_location, replay_location from pg_stat_replication;
client_addr | state | sent_location | write_location | flush_location | replay_location
-------------+-----------+---------------+----------------+----------------+-----------------
10.0.0.102 | streaming | 0/130011E0 | 0/130011E0 | 0/130011E0 | 0/130011E0
(1 row)As you can see, the process itself is not hard but it takes a while to perform and there are couple of steps where user can make a mistake and end up with replication not working correctly. Automation tools help with such tasks. Let’s take a look how to add another slave to our topology using ClusterControl:
First, we need to pick an ‘Add Replication Slave’ job.
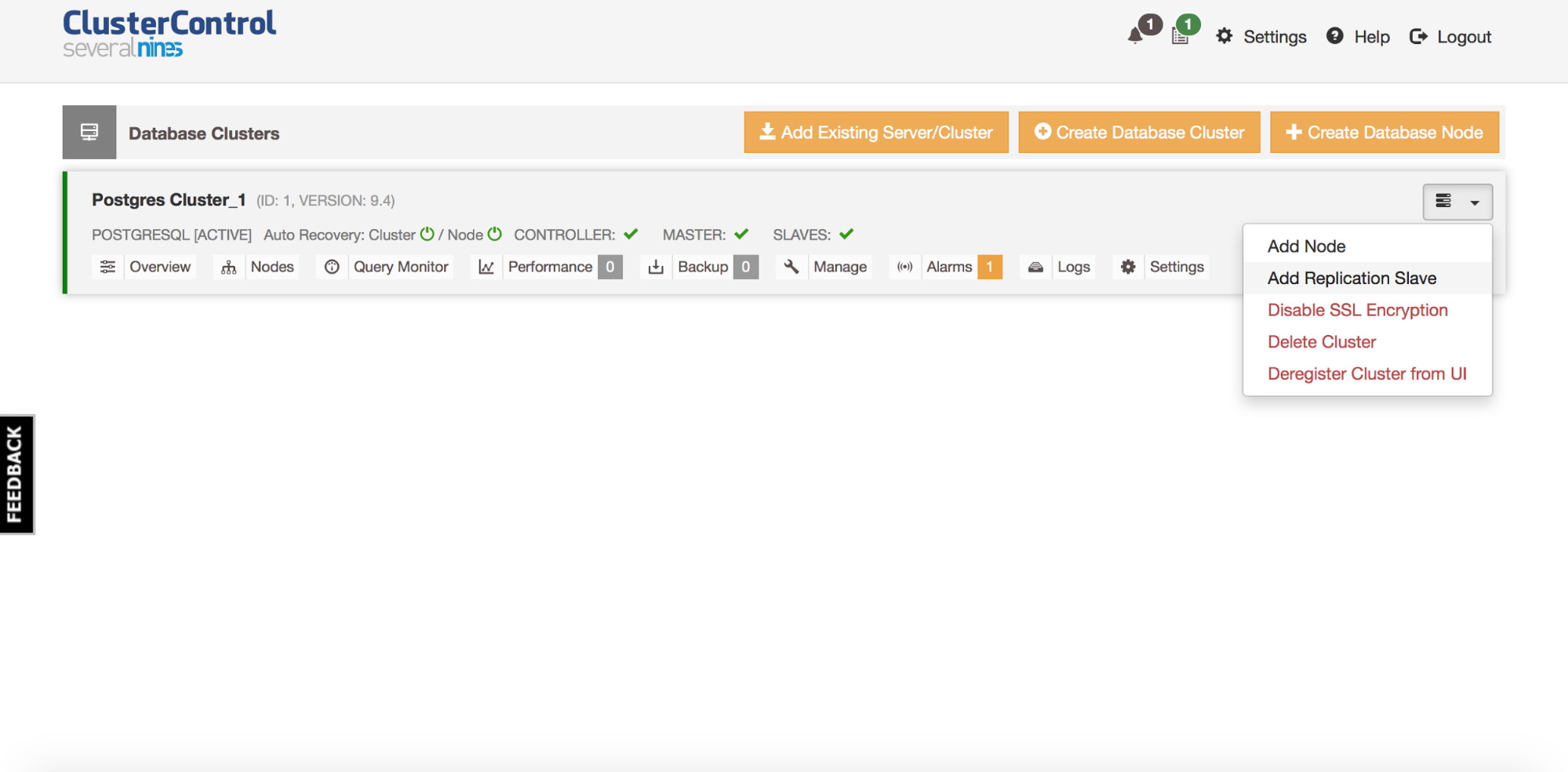
You’ll be presented with a following dialog box:
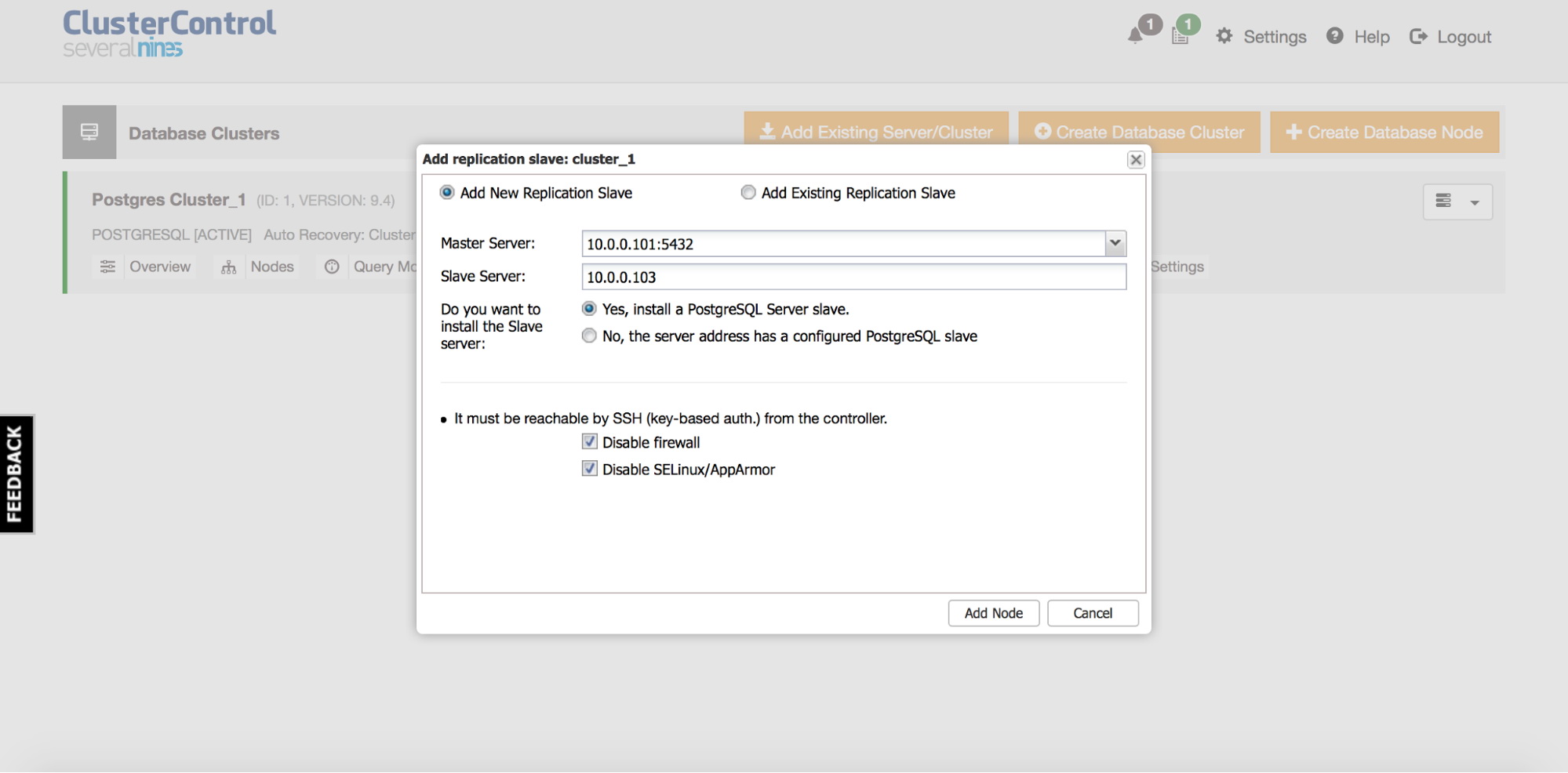
Here you have to pick whether you want to add a new replication slave from scratch or replication is already configured and all we have to do is to register the slave with ClusterControl. Requirements are the same as for any other nodes managed by ClusterControl – the node has to be reachable from the controller using SSH. You can also choose to disable firewall and SELinux or AppArmor.
Once you start the job, you can monitor its progress in the Logs section.
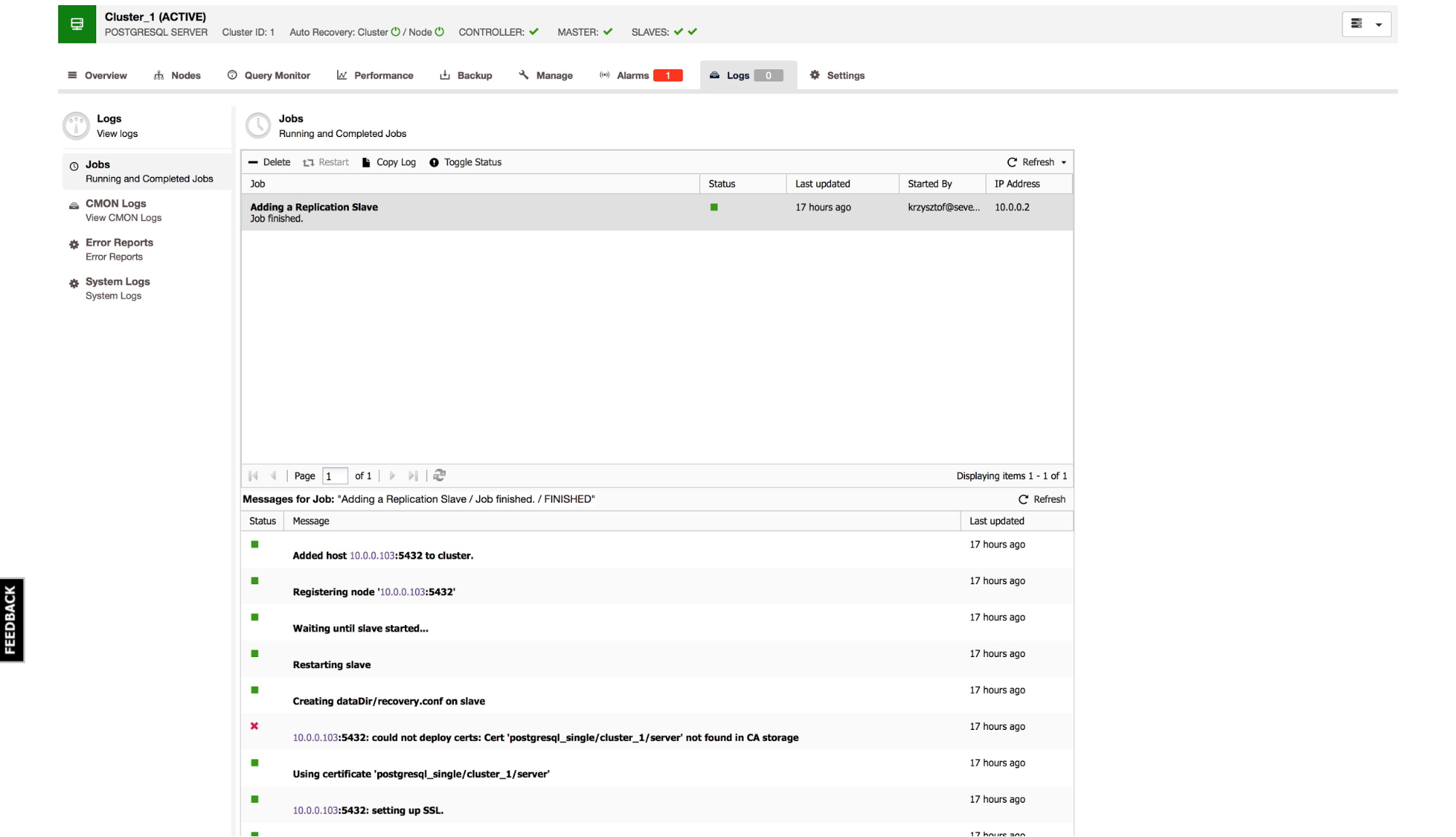
Summary
As you can see, setting up PostgreSQL replication is not a complex task. It can be made dead easy if you use an external tool to automate the process. This is a great way to scale out your PostgreSQL deployment and add high availability.
In the next blog post, we will see what other high availability solutions are available for PostgreSQL.



