blog
Comparing DBaaS Failover Solutions to Manual Recovery Setups

We have recently written several blogs covering how different cloud providers handle database failover. We compared failover performance in Amazon Aurora, Amazon RDS and ClusterControl, tested the failover behavior in Amazon RDS, and also on Google Cloud Platform. While those services provide great options when it comes to failover, they may not be right for every application.
In this blog post we will spend a bit of time analysing the pros and cons of using the DBaaS solutions compared with designing an environment manually or by using a database management platform, like ClusterControl.
Implementing High Availability Databases with Managed Solutions
The primary reason to use existing solutions is ease of use. You can deploy a highly available solution with automated failover in just a couple of clicks. There’s no need for combining different tools together, managing the databases by hand, deploying tools, writing scripts, designing the monitoring, or any other database management operations. Everything is already in place. This can seriously reduce the learning curve and requires less experience to set up a highly-available environment for the databases; allowing basically everyone to deploy such setups.
In most of the cases with these solutions, the failover process is executed within a reasonable time. It may be blazing fast as with Amazon Aurora or somewhat slower as with Google Cloud Platform SQL nodes. For the majority of the cases, these types of results are acceptable.
The bottom line. If you can accept 30 – 60 seconds of downtime, you should be ok using any of the DBaaS platforms.
The Downside of Using a Managed Solution for HA
While DBaaS solutions are simple to use, they also come with some serious drawbacks. For starters, there is always a vendor lock-in component to consider. Once you deploy a cluster in Amazon Web Services it is quite tricky to migrate out of that provider. There are no easy methods to download the full dataset through a physical backup. With most providers, only manually executed logical backups are available. Sure, there are always options to achieve this, but it is typically a complex, time-consuming process, which still may require some downtime after all.
Using a provider like Amazon RDS also comes with limitations. Some actions cannot be easily performed which would be very simple to accomplish on environments deployed in a fully user-controlled manner (e.g. AWS EC2). Some of these limitations have already been covered in other blogs, but to summarize is that no DBaaS service gives you the same level of flexibility as regular MySQL GTID-based replication. You can promote any slave, you can re-slave every node off any other…virtually every action is possible. With tools like RDS you face design-induced limitations you cannot bypass.
The problem is also with an ability to understand performance details. When you design your own highly available setup, you become knowledgeable about potential performance issues that may show up. On the other hand, RDS and similar environments are pretty much “black boxes.” Yes, we have learned that Amazon RDS uses DRBD to create a shadow copy of the master, we know that Aurora uses shared, replicated storage to implement very fast failovers. That’s just a general knowledge. We cannot tell what are the performance implications of those solutions other than what we might casually notice. What are common issues associated with them? How stable are those solutions? Only the developers behind the solution know for sure.
What is the Alternative to DBaaS Solutions?
You may wonder, is there an alternative to DBaaS? After all, it is so convenient to run the managed service where you can access most of the typical actions via UI. You can create and restore backups, failover is handled automatically for you. The environment is easy-to-use which can be compelling for companies who do not have dedicated and experienced staff for dealing with databases.
ClusterControl provides a great alternative to cloud-based DBaaS services. It provides you with a graphical user interface, which can be used to deploy, manage, and monitor open source databases.
In couple of clicks you can easily deploy a highly-available database cluster, with automated failover (faster than most of the DBaaS offerings), backup management, advanced monitoring, and other features like integration with external tools (e.g. Slack or PagerDuty) or upgrade management. All this while completely avoiding vendor lock-in.
ClusterControl doesn’t care where your databases are located as long as it can connect to them using SSH. You can have setups in cloud, on-prem, or in a mixed environment of multiple cloud providers. As long as connectivity is there, ClusterControl will be able to manage the environment. Utilizing the solutions you want (and not the ones that you are not familiar nor aware of) allows you to take full control over the environment at any point in time.
Whatever setup you deployed with ClusterControl, you can easily manage it in a more traditional, manual or scripted way. ClusterControl even provides you with command line interface, which will let you incorporate tasks executed by ClusterControl into your shell scripts. You have all the control you want – nothing is a black box, every piece of the environment would be built using open source solutions combined together and deployed by ClusterControl.
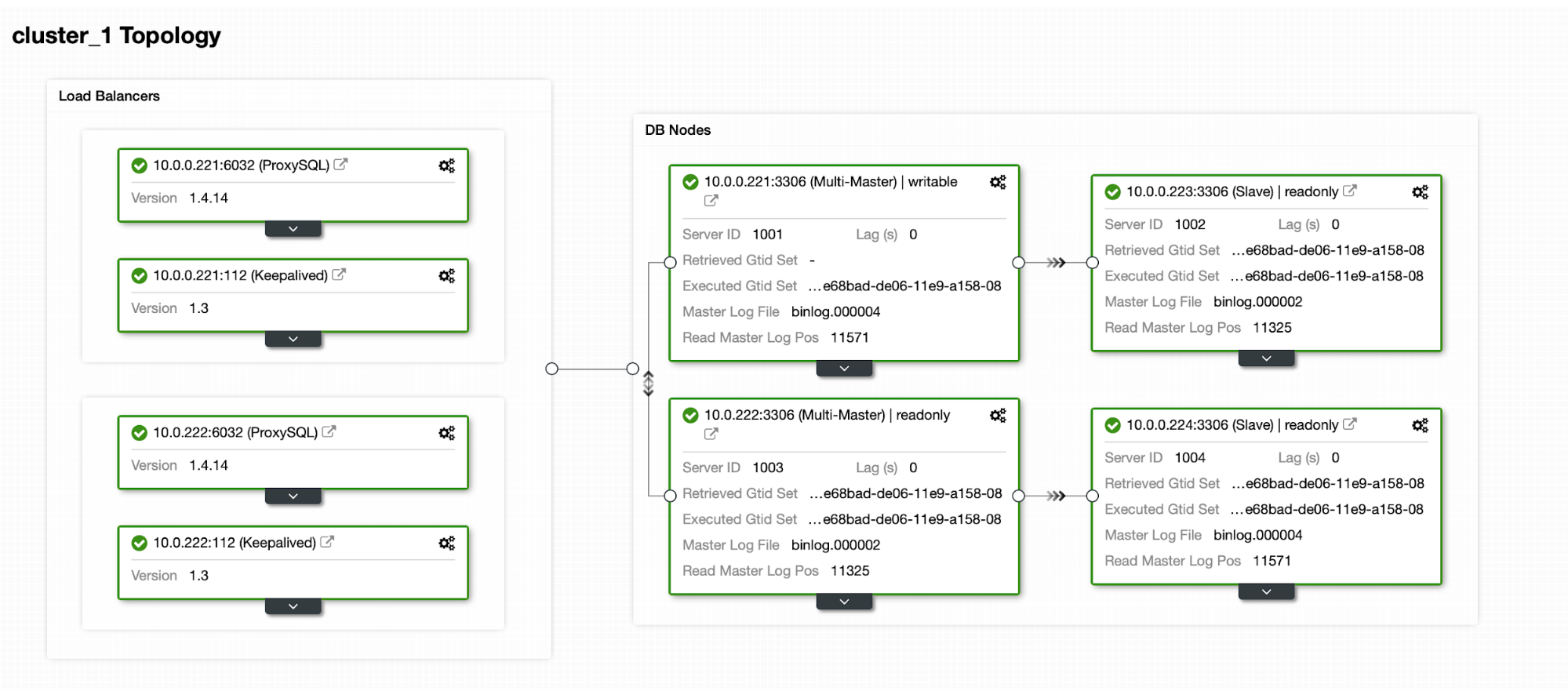
Let’s take a look at how easily you can deploy a MySQL Replication cluster using ClusterControl. Let’s assume you have the environment prepared with ClusterControl installed on one instance and all other nodes accessible via SSH from ClusterControl host.
We will start with picking the “Deploy” wizard.
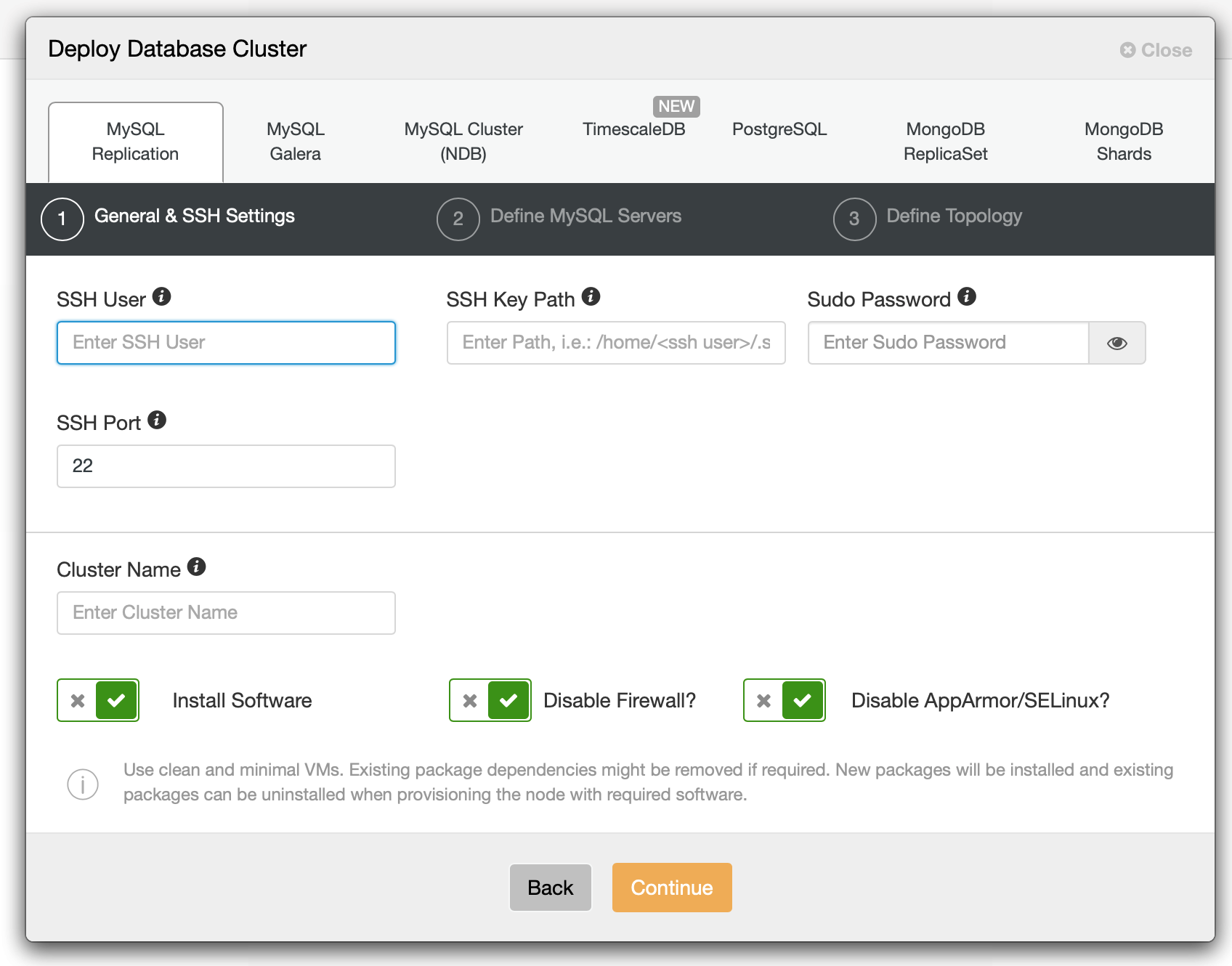
At the first step we have to define how ClusterControl should connect to the nodes on which databases are to be deployed. Both root access or sudo (with or without the password) are supported.
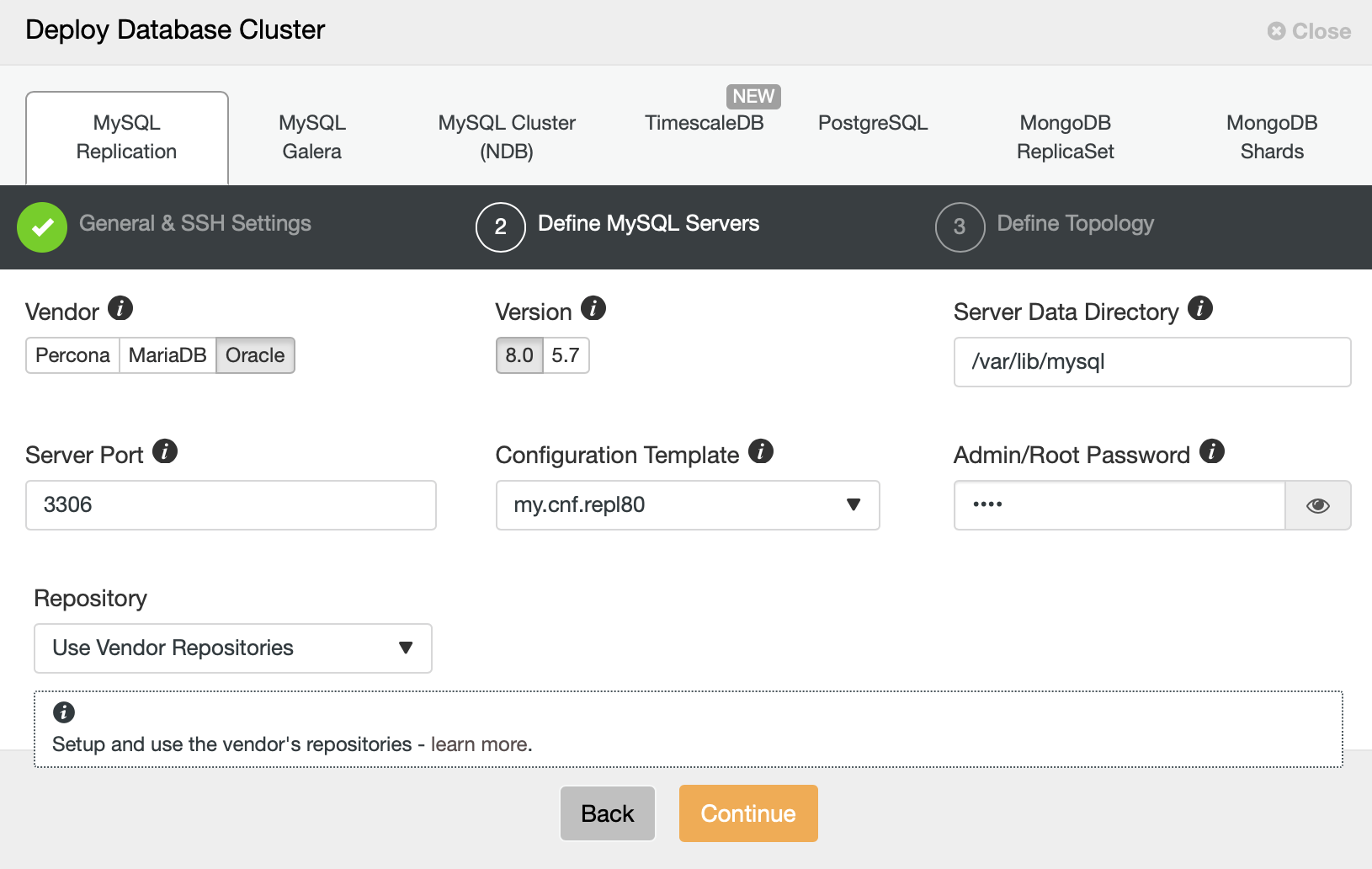
Then, we want to pick a vendor, version and pass the password for the administrative user in our MySQL database.
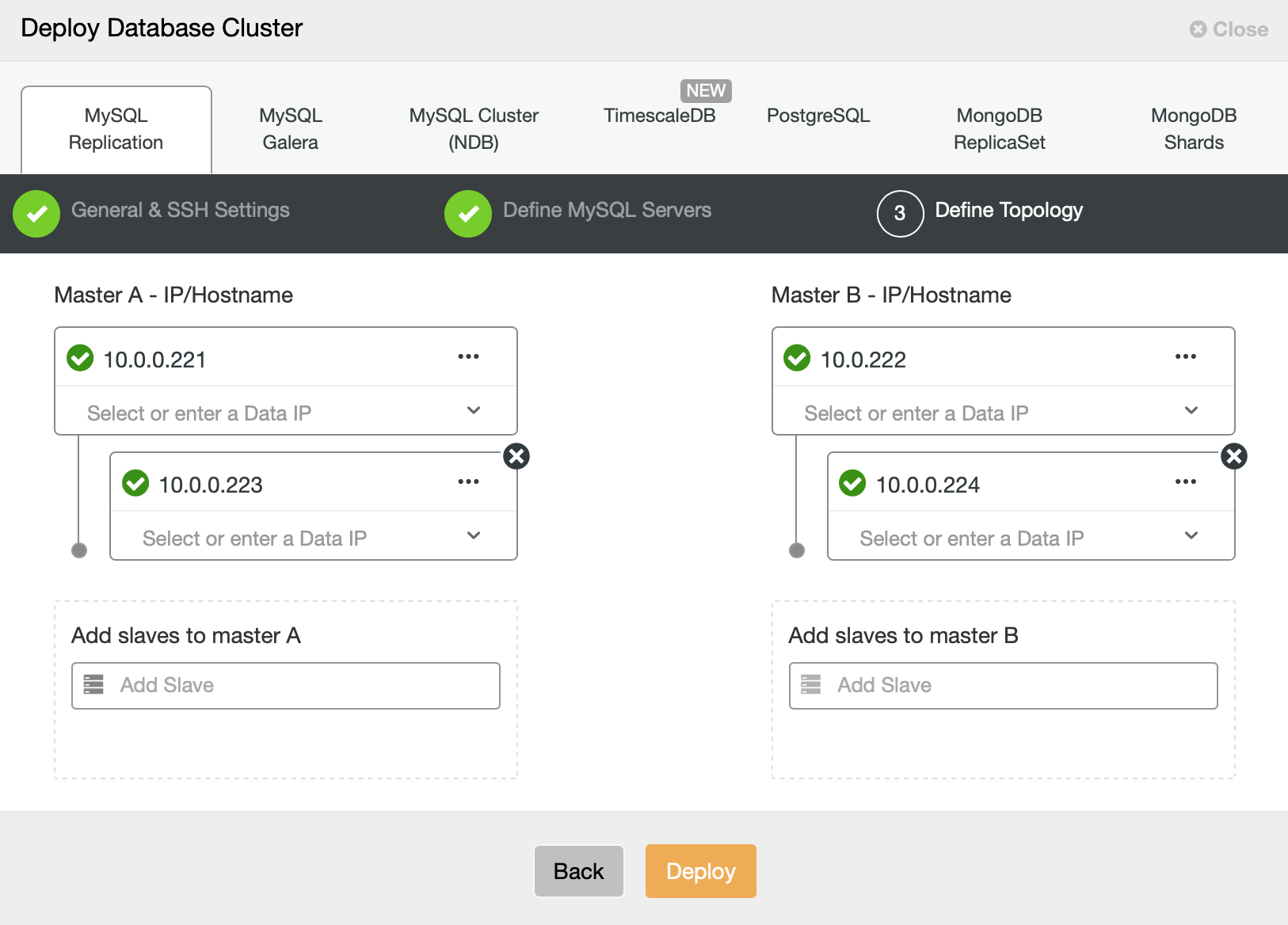
Finally, we want to define the topology for our new cluster. As you can see, this is already quite complex setup, unlike something you can deploy using AWS RDS or GCP SQL node.
All we have to do now is to wait for the process to complete. ClusterControl will do its best to understand the environment it is deploying to and install required set of packages, including the database itself.

Once the cluster is up-and-running, you can proceed with deploying the proxy layer (which will provide your application with a single point of entry into the database layer). This is more or less what happens behind the scenes with DBaaS, where you also have endpoints to connect to the database cluster. It is quite common to use a single endpoint for writes and multiple endpoints for reaching particular replicas.
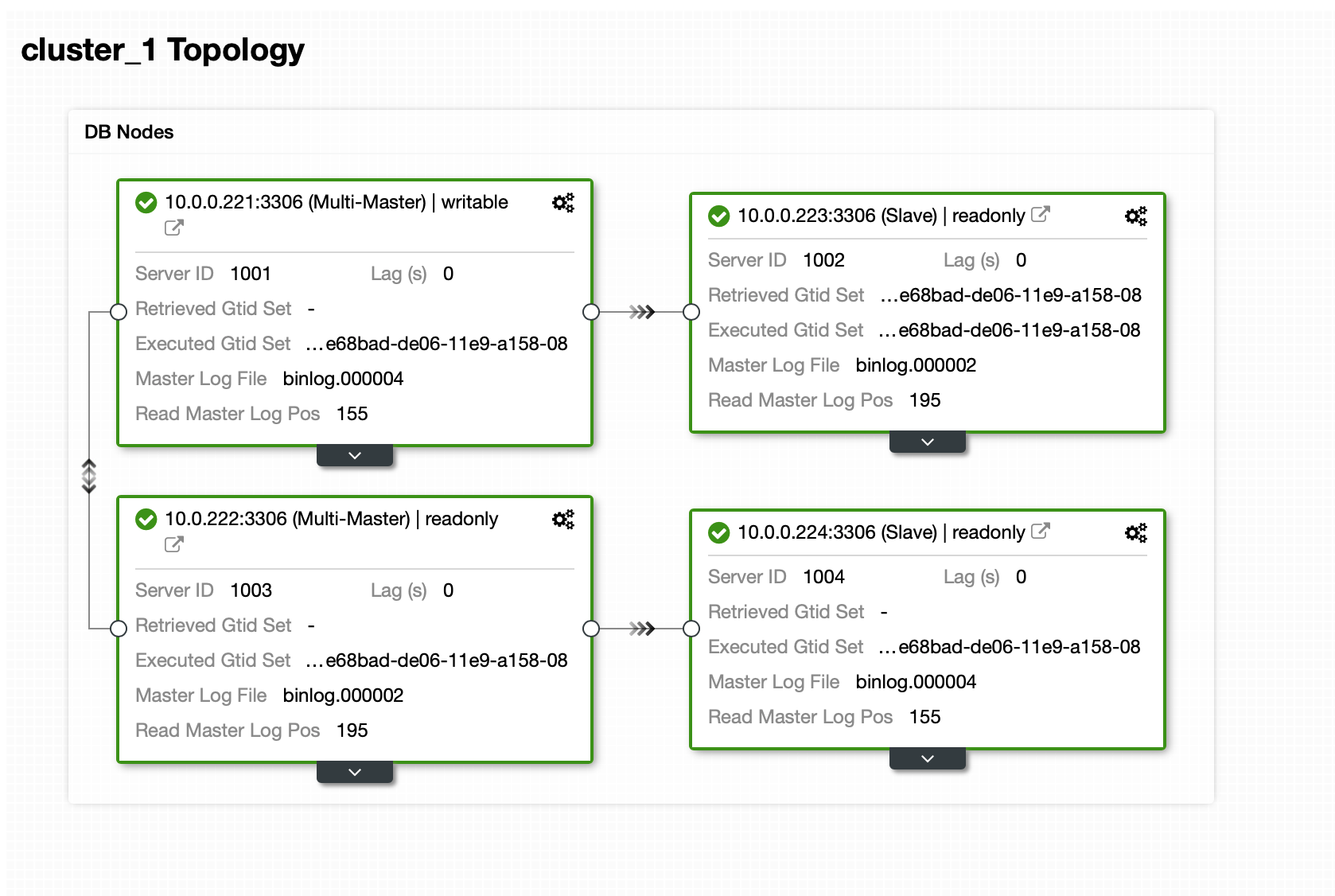
Here we will use ProxySQL, which will do the dirty work for us – it will understand the topology, sends writes only to the master and load balance read-only queries across all replicas that we have.
To deploy ProxySQL we will go to Manage -> Load Balancers.
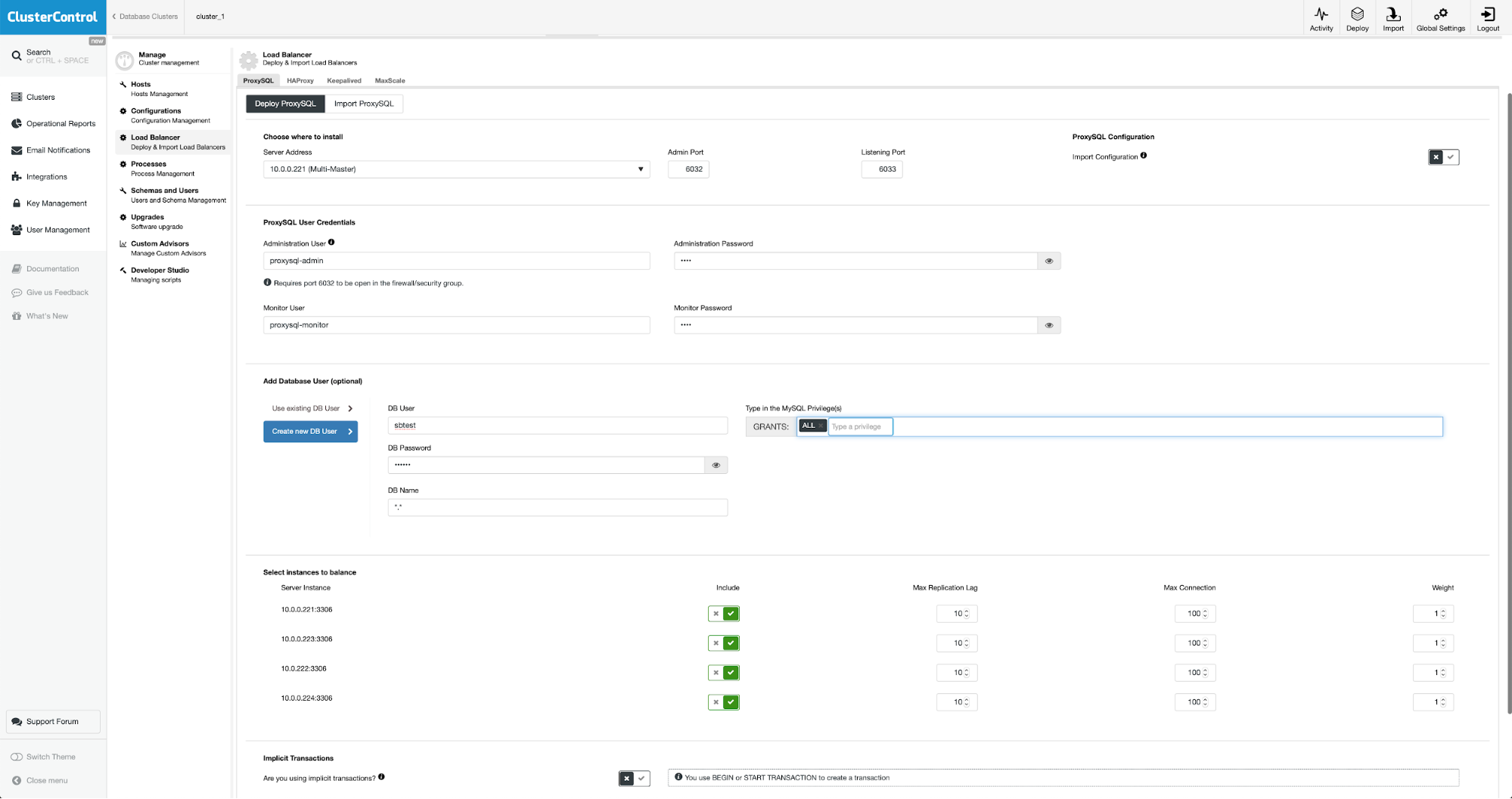
We have to fill all required fields: hosts to deploy on, credentials for the administrative and monitoring user, we may import existing user from MySQL into ProxySQL or create a new one. All the details about ProxySQL can be easily found in multiple blogs in our blog section.
We want at least two ProxySQL nodes to be deployed to ensure high-availability. Then, once they are deployed, we will deploy Keepalived on top of ProxySQL. This will ensure that Virtual IP will be configured and pointing to one of the ProxySQL instances, as long as there will be at least one healthy node.
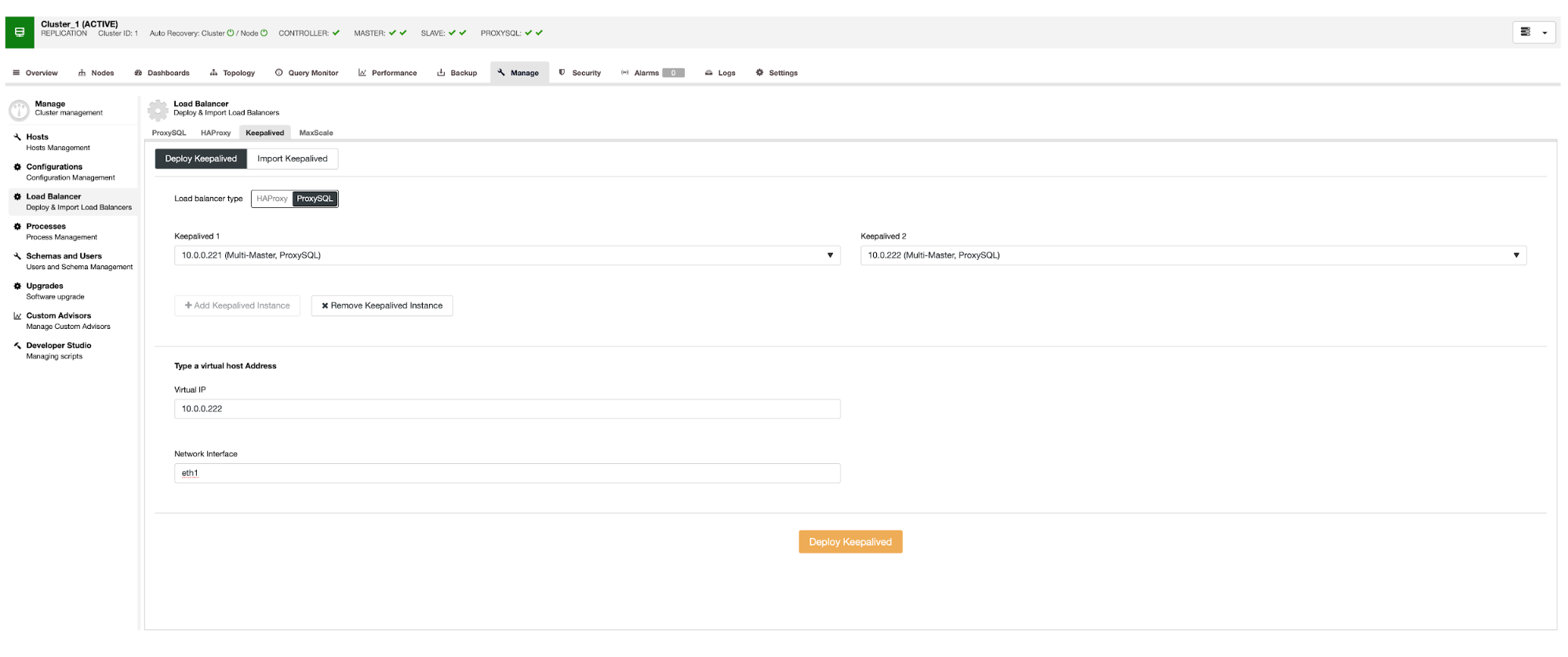
Here is the only potential problem if you go with cloud environments where routing works in a way that you cannot easily bring up a network interface. In such case you will have to modify the configuration of Keepalived, introduce ‘notify_master’ script and use a script, which will make the necessary IP changes – in case of EC2 it would have to detach Elastic IP from one host and attach it to the other host.
There are plenty of instructions on how to do that using widely-tested open source software in setups deployed by ClusterControl. You can easily find additional information, tips, and how-to’s which are relevant to your particular environment.
Conclusion
We hope you found this blog post insightful. If you would like to test ClusterControl, it comes with a 30 day enterprise trial where you have available all the features. You can download it for free and test if it fits in your environment.



