blog
Cloud Vendor Deep-Dive: PostgreSQL on AWS Aurora

How deep should we go with this? I’ll start by saying that as of this writing, I could locate only 3 books on Amazon about PostgreSQL in the cloud, and 117 discussions on PostgreSQL mailing lists about Aurora PostgreSQL. That doesn’t look like a lot, and it leaves me, the curious PostgreSQL end user, with the official documentation as the only place where I could really learn some more. As I don’t have the ability, nor the knowledge to adventure myself much deeper, there is AWS re:Invent 2018 for those who are looking for that kind of thrill. I can settle for Werner’s article on quorums.
To get warmed up, I started from the Aurora PostgreSQL homepage where I noted that the benchmark showing that Aurora PostgreSQL is three times faster than a standard PostgreSQL running on the same hardware dates back to PostgreSQL 9.6. As I’ve learned later, 9.6.9 is currently the default option when setting up a new cluster. That is very good news for those who don’t want to, or cannot upgrade right away. And why only 99.99% availability? One explanation can be found in Bruce Momjian’s article.
Compatibility
According to AWS, Aurora PostgreSQL is a drop-in replacement for PostgreSQL, and the documentation states:
The code, tools, and applications you use today with your existing MySQL and PostgreSQL databases can be used with Aurora.
That is reinforced by Aurora FAQs:
It means that most of the code, applications, drivers and tools you already use today with your PostgreSQL databases can be used with Aurora with little or no change. The Amazon Aurora database engine is designed to be wire-compatible with PostgreSQL 9.6 and 10, and supports the same set of PostgreSQL extensions that are supported with RDS for PostgreSQL 9.6 and 10, making it easy to move applications between the two engines.
“most” in the above text suggests that there isn’t a 100% guarantee in which case those seeking certainty should consider purchasing technical support from either AWS Professional Services, or Aamazon Aurora partners. As a side note, I did notice that none of the PostgreSQL professional Hosting Providers employing core community contributors are on that list.
From Aurora FAQs page we also learn that Aurora PostgreSQL supports the same extensions as RDS, which in turn lists most of the community extensions and a few extras.
Concepts
As part of Amazon RDS, Aurora PostgreSQL comes with its own terminology:
- Cluster: A Primary DB instance in read/write mode and zero or more Aurora Replicas. The primary DB is often labeled a Master in `AWS diagrams`_, or Writer in the AWS Console. Based on the reference diagram we can make an interesting observation: Aurora writes three times. As the latency between the AZs is typically higher than within the same AZ, the transaction is considered committed as soon it’s written on the data copy within the same AZ, otherwise the latency and potential outages between AZs.
- Cluster Volume: Virtual database storage volume spanning multiple AZs.
- Aurora URL: A `host:port` pair.
- Cluster Endpoint: Aurora URL for the Primary DB. There is one Cluster Endpoint.
- Reader Endpoint: Aurora URL for the replica set. To make an analogy with DNS it’s an alias (CNAME). Read requests are load balanced between available replicas.
- Custom Endpoint: Aurora URL to a group consisting of one or more DB instances.
- Instance Endpoint: Aurora URL to a specific DB instance.
- Aurora Version: Product version returned by `SELECT AURORA_VERSION();`.
PostgreSQL Performance and Monitoring on AWS Aurora
Sizing
Aurora PostgreSQL applies a best guess configuration which is based on the DB instance size and storage capacity, leaving further tuning to the DBA through the use of DB Parameters groups.
When selecting the DB instance, base your selection on the desired value for max_connections.
Scaling
Aurora PostgreSQL features auto and manual scaling. Horizontal scaling of read replicas is automated through the use of performance metrics. Vertical scaling can be automated via APIs.
Horizontal scaling takes the offline for a few minutes while replacing compute engine and performing any maintenance operations (upgrades, patching). Therefore AWS recommend performing such operations during maintenance windows.
Scaling in both directions is a breeze:
At the storage level, space is added in 10G increments. Allocated storage is never reclaimed, see below for how to address this limitation.
Storage
As mentioned above, Aurora PostgreSQL was engineered to take advantage of quorums in order to improve performance consistency.
Since the underlying storage is shared by all DB instances within the same cluster, no additional writes on standby nodes are required. Also, adding or removing DB instances doesn’t change the underlying data.
Wondering what those IOs units mean on the monthly bill? Aurora FAQs comes to the rescue again to explain what an IO is, in the context of monitoring and billing. A Read IO as the equivalent of an 8KiB database page read, and a Write IO as the equivalent of 4KiB written to the storage layer.
High Concurrency
In order to take full advantage of Aurora’s high-concurrency design, it is recommended that applications are configured to drive a large number of concurrent queries and transactions.
Applications designed to direct read and write queries to respectively standby and primary database nodes will benefit from Aurora PostgreSQL reader replica endpoint.
Connections are load balanced between read replicas.
Using custom endpoints database instances with more capacity can be grouped together in order to run an intensive workload such as analytics.
DB Instance Endpoints can be used for fine-grained load balancing or fast failover.
Note that in order for the Reader Endpoints to load balance individual queries, each query must be sent as a new connection.
Caching
Aurora PostgreSQL uses a Survivable Cache Warming technique which ensures that the date in the buffer cache is preserved, eliminating the need for repopulating or warming-up the cache following a database restart.
Replication
Replication lag time between replicas is kept within single digit millisecond. Although not available for PostgreSQL, it’s good to know that cross-region replication lag is kept within 10s of milliseconds.
According to documentation replica lag increases during periods of heavy write requests.
Query Execution Plans
Based on the assumption that query performance degrades over time due to various database changes, the role of this Aurora PostgreSQL component is to maintain a list of approved or rejected query execution plans.
Plans are approved or rejected using either proactive or reactive methods.
When an execution plan is marked as rejected, the Query Execution Plan overrides the PostgreSQL optimizer decisions and prevents the “bad” plan from being executed.
This feature requires Aurora 2.1.0 or later.
PostgreSQL High Availability and Replication on AWS Aurora
At the storage layer, Aurora PostgreSQL ensures durability by replicating each 10GB of storage volume, six times across 3 AZs (each region consists of typically 3 AZs) using physical synchronous replication. That makes it possible for database writes to continue working even when 2 copies of data are lost. Read availability survives the loss of 3 copies of data.
Read replicas ensure that a failed primary instance can be quickly replaced by promoting one of the 15 available replicas. When selecting a multi-AZ deployment one read replica is automatically created. Failover requires no user intervention, and database operations resume in less than 30 seconds.
For single-AZ deployments, the recovery procedure includes a restore from the last known good backup. According to Aurora FAQs the process completes in under 15 minutes if the database needs to be restored in a different AZ. The documentation isn’t that specific, claiming that it takes less than 10 minutes to complete the restore process.
No change is required on the application side in order to connect to the new DB instance as the cluster endpoint doesn’t change during a replica promotion or instance restore.
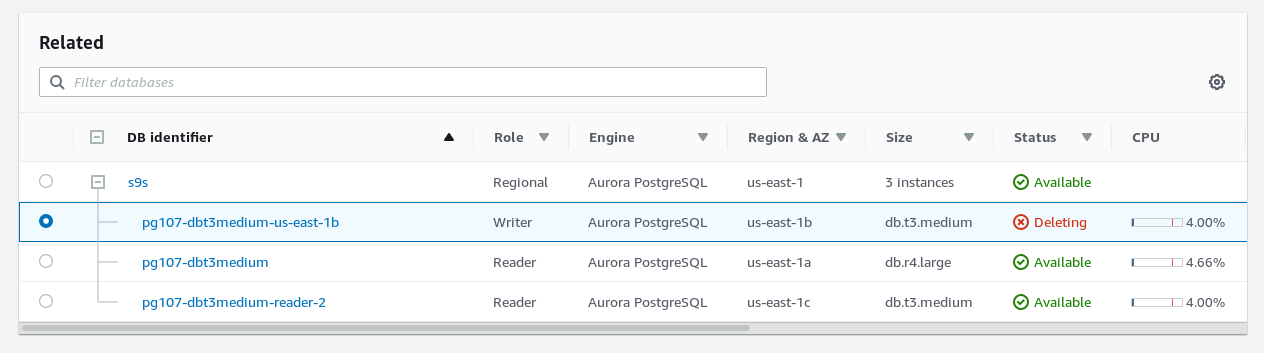
Step 1: delete the primary instance to force a failover:
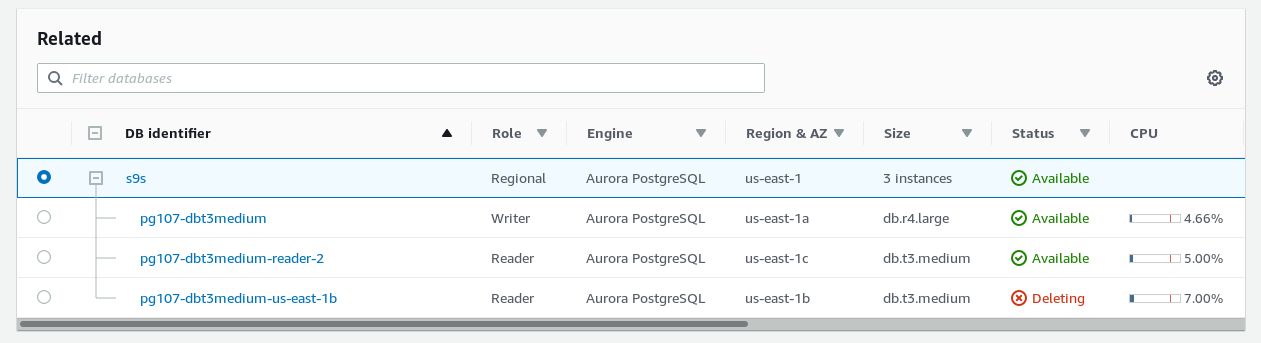
Step 2: automatic failover completed
For busy databases, the recovery time following a restart or crash is dramatically reduced since Aurora PostgreSQL doesn’t need to replay the transaction logs.
As part of full-managed service, bad data blocks and disks are automatically replaced.
Failover when replicas exist takes up to 120 seconds with often time under 60 seconds. Faster recovery times can be achieved by when failover conditions are pre-determined, in which case replicas can be assigned failover priorities.
Aurora PostgreSQL plays nice with Amazon RDS – an Aurora instance can act as a read replica for a primary RDS instance.
Aurora PostgreSQL supports Logical Replication which, just like in the community version, can be used to overcome built-in replication limitations. There is no automation or AWS console interface.
Security for PostgreSQL on AWS Aurora
At network level, Aurora PostgreSQL leverages AWS core components, VPC for cloud network isolation and Security Groups for network access control.
There is no superuser access. When creating a cluster, Aurora PostgreSQL creates a master account with a subset of superuser permissions:
postgres@pg107-dbt3medium-restored-cluster:5432 postgres> du+ postgres
List of roles
Role name | Attributes | Member of | Description
-----------+-------------------------------+-----------------+-------------
postgres | Create role, Create DB +| {rds_superuser} |
| Password valid until infinity | |To secure data in transit, Aurora PostgreSQL provides native SSL/TLS support which can be configured per DB instance.
All data at rest can be encrypted with minimal performance impact. This also applies to backups, snapshots, and replicas.
Authentication is controlled by IAM policies, and tagging allows further control over what users are allowed to do and on what resources.
API calls used by all cloud services are logged in CloudTrail.
Client side Restricted Password Management is available via the rds.restrict_password_commands parameter.
PostgreSQL Backup and Recovery on AWS Aurora
Backups are enabled by default and cannot be disabled. They provide point-in-time-recovery using a full daily snapshot as a base backup.
Restoring from an automated backup has a couple of disadvantages: the time to restore may be several hours and data loss may be up to 5 minutes preceding the outage. Amazon RDS Multi-AZ Deployments solve this problem by promoting a read replica to primary, with no data loss.
Database Snapshots are fast and don’t impact the cluster performance. They can be copied or shared with other users.
Taking a snapshot is almost instantaneous:

Restoring a snapshot is also fast. Compare with PITR:
Backups and snapshots are stored in S3 which offers eleven 9’s of durability.
Aside from backups and snapshots, Aurora PostgreSQL allows databases to be cloned. This is an efficient method for creating copies of large data sets. For example, cloning multi-terabytes of data take only minutes and there is no performance impact.
Aurora PostgreSQL – Point-in-Time Recovery Demo
Connecting to cluster:
~ $ export PGUSER=postgres PGPASSWORD=postgres PGHOST=s9s-us-east-1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
~ $ psql
Pager usage is off.
psql (11.3, server 10.7)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.Populate a table with data:
postgres@s9s-us-east-1:5432 postgres> create table s9s (id serial not null, msg text, created timestamptz not null default now());
CREATE TABLE
postgres@s9s-us-east-1:5432 postgres> select * from s9s;
id | msg | created
----+------+-------------------------------
1 | test | 2019-06-25 07:57:40.022125+00
2 | test | 2019-06-25 07:57:57.666222+00
3 | test | 2019-06-25 07:58:05.593214+00
4 | test | 2019-06-25 07:58:08.212324+00
5 | test | 2019-06-25 07:58:10.156834+00
6 | test | 2019-06-25 07:59:58.573371+00
7 | test | 2019-06-25 07:59:59.5233+00
8 | test | 2019-06-25 08:00:00.318474+00
9 | test | 2019-06-25 08:00:11.153298+00
10 | test | 2019-06-25 08:00:12.287245+00
(10 rows)Initiate the restore:
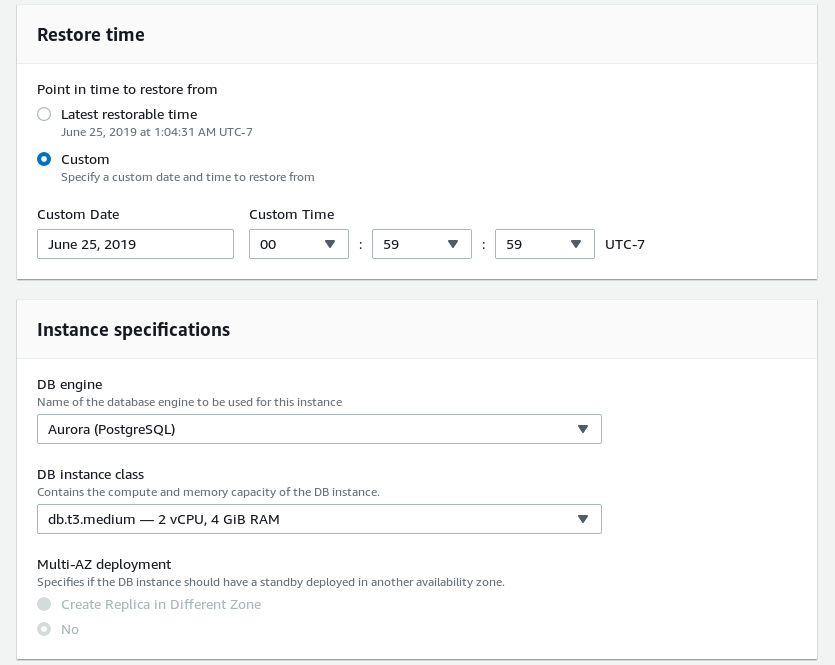
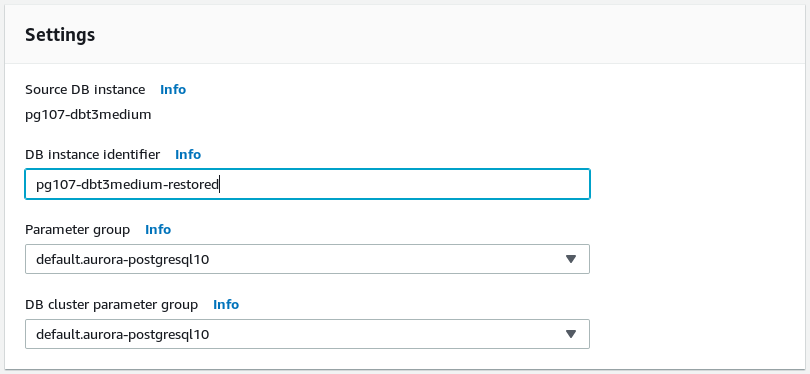
Once the restore is complete log in and check:
~ $ psql -h pg107-dbt3medium-restored-cluster.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
Pager usage is off.
psql (11.3, server 10.7)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres@pg107-dbt3medium-restored-cluster:5432 postgres> select * from s9s;
id | msg | created
----+------+-------------------------------
1 | test | 2019-06-25 07:57:40.022125+00
2 | test | 2019-06-25 07:57:57.666222+00
3 | test | 2019-06-25 07:58:05.593214+00
4 | test | 2019-06-25 07:58:08.212324+00
5 | test | 2019-06-25 07:58:10.156834+00
6 | test | 2019-06-25 07:59:58.573371+00
(6 rows)Best Practices
Monitoring and Auditing
- Integrate database activity streams with third party monitoring in order to monitor database activity for compliance and regulatory requirements.
- A fully-managed database service doesn’t mean lack of responsibility — define metrics to monitor the CPU, RAM, Disk Space, Network, and Database Connections.
- Aurora PostgreSQL integrates with AWS standard monitoring tool CloudWatch, as well as providing additional monitors for Aurora Metrics, Aurora Enhanced Metrics, Performance Insight Counters, Aurora PostgreSQL Replication, and also for RDS Metrics that can be further grouped by RDS Dimensions.
- Monitor Average Active Sessions DB Load by Wait for signs of connections overhead, SQL queries that need tuning, resource contention or an undersized DB instance class.
- Setup Event Notifications.
- Configure error log parameters.
- Monitor configuration changes to database cluster components: instances, subnet groups, snapshots, security groups.
Replication
- Use native table partitioning for workloads that exceed the maximum DB instance class and storage capacity
Encryption
- Encrypted database must have backups enabled to ensure data can be restored in case the encryption key is revoked.
Master Account
- Do not use psql to change the master user password.
Sizing
- Consider using different instance classes in a cluster in order to reduce costs.
Parameter Groups
- Fine tune using Parameter Groups in order to save $$$.
Parameter Groups Demo
Current settings:
postgres@s9s-us-east-1:5432 postgres> show shared_buffers ;
shared_buffers
----------------
10112136kB
(1 row)Create a new parameter group and set the new cluster wide value:

Associate the custom parameter group with the cluster:
Reboot the writer and check the value:
postgres@s9s-us-east-1:5432 postgres> show shared_buffers ;
shared_buffers
----------------
1GB
(1 row)- Set the local timezone
By default, the timezone is in UTC:
postgres@s9s-us-east-1:5432 postgres> show timezone;
TimeZone
----------
UTC
(1 row)Setting the new timezone:
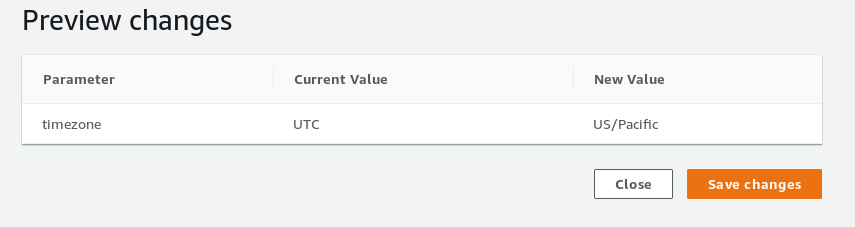
And then check:
postgres@s9s-us-east-1:5432 postgres> show timezone;
TimeZone
------------
US/Pacific
(1 row)Note that the list of timezone values accepted by Amazon Aurora is not the timezonesets found in upstream PostgreSQL.
- Review instance parameters that are overridden by cluster parameters
- Use the parameter group comparison tool.
Snapshots
- Avoid additional storage charges by sharing the snapshots with another accounts to allow restoring into their respective environments.
Maintenance
- Change the default maintenance window according to organization schedule.
Failover
- Improve recovery time by configuring the Cluster Cache Management.
- Lower the kernel TCP keepalive values on the client and configure the application DNS cache and TTL, and PostgreSQL connection strings.
DBA Beware!
In addition to the known limitations avoid, or be aware of the following:
Encryption
- Once a database has been created the encryption state cannot be changed.
Aurora Serverless
- At this time, the PostgreSQL version of Aurora Serverless is only available in limited preview.
Parallel Query
- Amazon Parallel Query is not available, although the feature with the same name is available since PostgreSQL 9.6.
Endpoints
From Amazon Connection Management:
- 5 Custom Endpoints per cluster
- Custom Endpoint names cannot exceed 63 characters
- Cluster Endpoint names are unique within the same region
- As seen in the above screenshot (aurora-custom-endpoint-details) READER and ANY custom endpoint types aren’t available, use the CLI
- Custom Endpoints are unaware of replicas becoming temporarily unavailable
Replication
- When promoting a Replica to Primary, connections via the Reader Endpoint may continue to be directed for a brief time to the promoted Replica.
- Cross-region Replicas are not supported
- While released at the end of November 2017, the Amazon Aurora Multi-Master preview is still not available for PostgreSQL
- Watch for performance degradation when logical replication is enabled on the cluster.
- Logical Replication requires a published running PostgreSQL engine 10.6 or later.
Storage
- Maximum allocated storage does not shrink when data is deleted, neither is space reclaimed by restoring from snapshots. The only way to reclaim space is by performing a logical dump into a new cluster.
Backup and Recovery
- Backups retention isn’t extended while the cluster is stopped.
- Maximum retention period is 35 days — use manual snapshots for a longer retention period.
- point-in-time recovery restores to a new DB cluster.
- brief interruption of reads during failover to replicas.
- Disaster Recovery scenarios are not available cross-region.
Snapshots
- Restoring from snapshot creates a new endpoint (snapshots can only be restored to a new cluster).
- Following a snapshot restore, custom endpoints must be recreated.
- Restoring from snapshots resets the local timezone to UTC.
- Restoring from snapshots does not preserve the custom security groups.
- Snapshots can be shared with a maximum of 20 AWS account IDs.
- Snapshots cannot be shared between regions.
- Incremental snapshots are always copied as full snapshots, between regions and within the same region.
- Copying snapshots across regions does not preserve the non-default parameter groups.
Billing
- The 10 minutes bill applies to new instances, as well as following a capacity change (compute, or storage).
Authentication
- Using IAM database authentication imposes a limit on the number of connections per second.
- The master account has certain superuser privileges revoked.
Starting and Stopping
From Overview of Stopping and Staring an Aurora DB Cluster:
- Clusters cannot be left stopped indefinitely as they are started automatically after 7 days.
- Individual DB instances cannot be stopped.
Upgrades
- In-place major version upgrades are not supported.
- Parameter group changes for both DB instance and DB cluster take at least 5 minutes to propagate.
Cloning
- 15 clones per database (original or copy).
- Clones are not removed when deleting the source database.
Scaling
- Auto-Scaling requires that all replicas are available.
- There can be only `one auto-scaling policy`_ per metric per cluster.
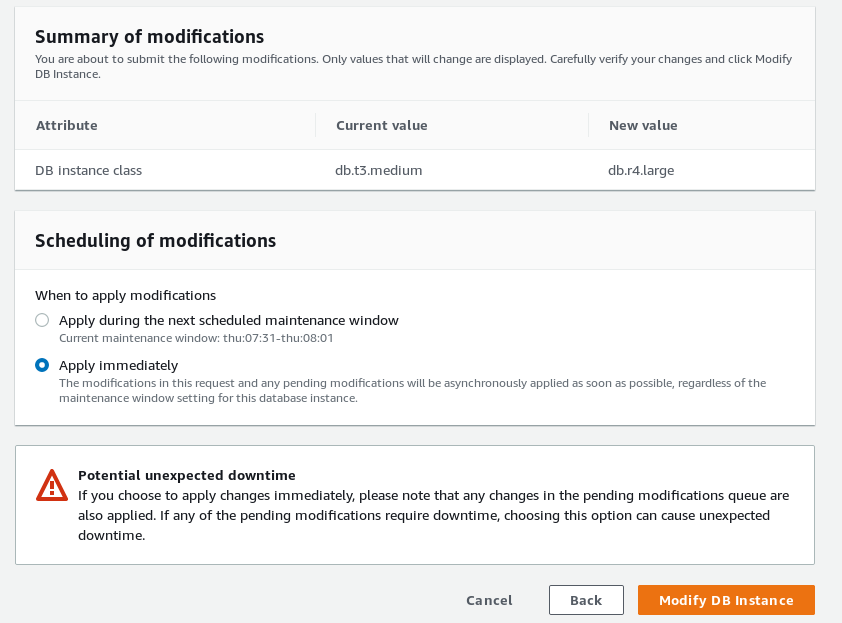
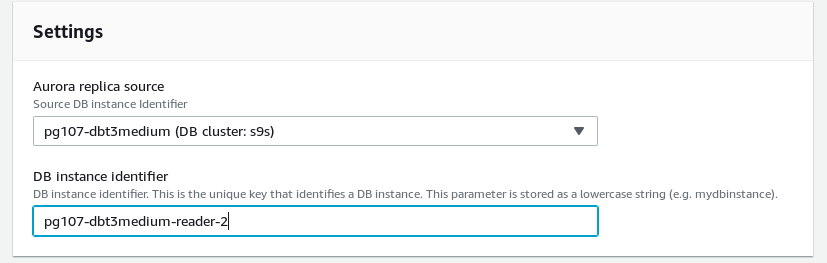
- Horizontal scaling of the primary DB instance (instance class) is not fully automatic. Before scaling the cluster triggers an automatic failover to one of the replicas. After scaling completes the new instance must be manually promoted from reader to writer:
 New instance left in reader mode after DB instance class change.
New instance left in reader mode after DB instance class change.
Monitoring
- Publishing PostgreSQL logs to CloudWatch requires a minimum database engine version of 9.6.6 and 10.4.
- Only some Aurora metrics are available in the RDS Console and other metrics have different names and measurement units.
- By default, Enhanced Monitoring logs are kept in CloudWatch for 30 days.
- Cloudwatch and Enhanced Monitoring metrics will differ, as they gather data from the hypervisor and respectively the agent running on the instance.
- Performance Insights_ aggregates the metrics across all databases within a DB Instance.
- SQL statements are limited to 500 characters when viewed with AWS Performance Insights CLI and API.
Migration
- Only RDS unencrypted DB Snapshots can be encrypted at rest.
- Migrations using the Aurora Read Replica technique take several hours per TiB.
Sizing
- The smallest available instance class is db.t3.medium and the largest db.r5.24xlarge. For comparison, the MySQL engine offers db.t2.small and db.t2.medium, however no db.r5.24xlarge in the upper range.
- max_connections upper limit is 262,143.
Query Plan Management
- Statements inside PL/pgSQL functions are unsupported.
Migration
Aurora PostgreSQL does not provide direct migration services, rather the task is offloaded to a specialized AWS product, namely AWS DMS.
Conclusion
As a fully-managed drop-in replacement for the upstream PostgreSQL, Amazon Aurora PostgreSQL takes advantage of the technologies that power the AWS cloud to remove the complexity required to setup services such as auto-scaling, query load-balancing, low-level data replication, incremental backups, and encryption.
The architecture and a conservative approach for upgrading the PostgreSQL engine provides the performance and the stability organizations from small to large are looking for.
The inherent limitations are just a proof that building a large scale Database as a Service is a complex task, leaving the highly specialized PostgreSQL Hosting Providers with a niche market they can tap into.



