blog
Why You Should Still Be Using the MMAPv1 Storage Engine for MongoDB

While this storage engine has been deprecated as far back as MongoDB version 4.0, there are some important features in it. MMAPv1 is the original storage engine in MongoDB and is based on mapped files. Only the 64-bit Intel architecture (x86_64) supports this storage engine.
MMAPv1 drives excellent performance at workloads with…
- Large updates
- High volume reads
- High volume inserts
- High utilization of system memory
MMAPv1 Architecture
MMAPv1 is a B-tree based system which powers many of the functions such as storage interaction and memory management to the operating system.
It was the default database for MongoDB for versions earlier than 3.2 until the introduction of the WiredTiger storage engine. Its name comes from the fact that it uses memory mapped files to access data. It does so by directly loading and modifying file contents, which are in a virtual memory through a mmap() syscall methodology.
All records are contiguously located on the disk and in the case that a document becomes larger than the allocated record size, then MongoDB allocates a new record. For MMAPv1 this is advantageous for sequential data access but at the same time a limitation as it comes with a time cost since all document indexes need to be updated and this may result to storage fragmentation.
The basic architecture of the MMAPv1 storage engine is shown below.
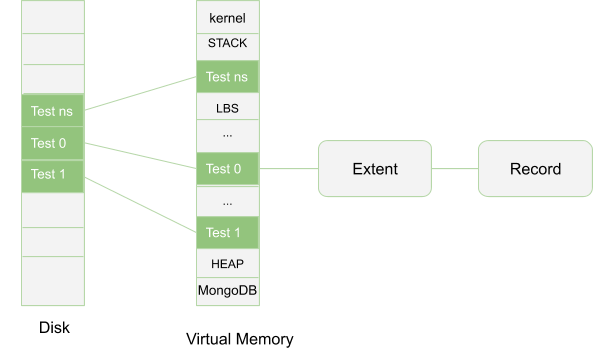
As mentioned above, if a document size surpasses the allocated record size, it will result to a reallocation which is not a good thing. To avoid this the MMAPv1 engine utilizes a Power of 2 Sized Allocation so that every document is stored in a record that contains the document itself (including some extra space known as padding). The padding is then used to allow for any document growth that may result from updates while it reduces the chances of reallocations. Otherwise, if reallocations occur you may end up having storage fragmentation. Padding trades additional space to improve on efficiency hence reducing fragmentation. For workloads with high volumes of inserts, updates or deletes, the power of 2 allocation should be most preferred whereas exact fit allocation is ideal fo collections that do not involve any update or delete workloads.
Power of 2 Sized Allocation
For smooth document growth, this strategy is employed in the MMAPv1 storage engine. Every record has a size in bytes which is a power of 2, i.e. (32, 64, 128, 256, 512…2MB). 2MB being the default larger limit any document that surpasses this, its memory is rounded to the nearest multiple of 2MB. For example, if a document is 200MB, this size will be rounded off to 256MB and 56MB trade of space will be available for any additional growth.This enables documents to grow instead of triggering a reallocation the system will need to make when documents reach their limits of available space.
Merits of Power 2 Sized Allocations
- Reuse of freed records to reduce fragmentation: With this concept, records are memory quantized to have a fixed size which is large enough to accommodate new documents that would fit into to allocated space created by an earlier document deletion or relocation.
- Reduces document moves: As mentioned before, by default MongoDB inserts and updates that make document size larger than the set record size will result in updating of the indexes too. This simply means the documents have been moved. However, when there is enough space for growth within a document, the document will not be moved hence less updates to indexes.
Memory Usage
All free memory on machine in the MMAPv1 storage engine is used as cache. Correctly sized working sets and optimal performance is achieved through a working set that fits into memory. Besides, for every 60 seconds, the MMAPv1 flushes changes to data to disk hence saving on the cache memory. This value can be changed such that the flushing may be done frequently. Because all free memory is used as cache, don’t be shocked that system resource monitoring tools will indicate that MongoDB uses a lot of memory since this usage is dynamic.
Merits of MMAPv1 Storage Engine
- Reduced on-disk fragmentation when using the pre-allocation strategy.
- Very efficient reads when the working set has been configured to fit into memory.
- In-place updates i.e individual field updates can result in more data being stored hence improving on large documents update with minimal concurrent writers.
- With a low number of concurrent writers, the write performance can be improved through the data flushing to disk frequently concept.
- Collection-level locking facilitates write operations. Locking scheme is one of the most important factors in database performance. In this case, only 1 client can access the database at a time. This creates a scenario such that operations flow more quickly than when presented in a serial manner by the storage engine.
Limitations of the MMAPv1 Storage Engine
- High space utilization when doing iterations. MMAPv1 lacks a compression strategy for the file system hence does an over-allocation of record space.
- Collection access restriction for many clients when doing a write operation. MMAPv1 uses collection-level-locking strategy which means 2 or more clients cannot access the same collection at the same time hence a write blocks all reads to this collection. This is leads to coarse concurrency that makes it impossible to scale the MMAPv1 engine.
- System crash may potentially result in data loss if the journaling option is not enabled. However, even if it is, the window is too small but at least may safe you from a large data loss scenario.
- Inefficient storage utilization. When using the pre-allocation strategy, some documents will occupy more space on disk than the data itself would.
- If the working set size exceeds the allocated memory, performance drops to a large extent. Besides, document significant growth after initial storage may trigger additional I/O hence cause performance issue.
Comparing MMAPv1 and WiredTiger Storage Engines
| Key Feature | MMAPv1 | WiredTiger |
|---|---|---|
| CPU performance | Adding more CPU cores unfortunately does not boost the performance | Performance improves with multicore systems |
| Encryption | Due to memory-mapped files being used, it does not support any encryption | Encryption for both data in transit and rest is available in both MongoDB enterprise and Beta installation |
| Scalability | Concurrent writes that result from collection-level locking make it impossible to scale out. | High chances of scaling out since the least locking level is the document itself. |
| Tuning | Very little chances of tuning this storage engine | Plenty of tuning can be done around variables such as cache size, checkpoint intervals and read/write tickets |
| Data compression | No data compression hence more space may be used | Snappy and zlib compression methods available hence documents may occupy less space than in MMAPv1 |
| Atomic transactions | Only applicable for a single document | As from version 4.0 atomic transaction on multi-documents is supported. |
| Memory | All free memory on machine is used as its cache | Filesystem cache and internal cache are utilized |
| Updates | Supports in-place updates hence excels at workloads with heavy volume inserts, reads and in-place updates | Does not support in-place updates.The whole document has to be rewritten. |
Conclusion
When coming to storage engine selection for a database, many people don’t know which one to choose. The choice normally relies on the workload that it will be subjected unto. On a general gauge, the MMAPv1 would make a poor choice and that’s why MongoDB made a lot of advancements to the WiredTiger option. However, it still may outdo some other storage engines depending on the use case for example where you need to perform only read workloads or need to store many separate collections with large documents whereby 1 or 2 fields are frequently updated.



