blog
The what, why, and how of Elasticsearch failover

Elasticsearch failover – what is it? Why did it happen? Why would you bother? Failover is a common situation in a database world. Some failovers are planned upfront, tested in detail and executed by following a detailed runbook. Other failovers may happen in your Elasticsearch cluster out of the blue, catching you by surprise. Why is it important to configure your Elasticsearch database to be able to run automated failovers? Let’s do a dive into the world of Elasticsearch failover by starting with what it really means and what are the common causes that may trigger a failover.
Common causes of failover for Elasticsearch databases
In the database world, failover is a process that changes node roles within the cluster. Depending on the database technology, nodes may assume different roles. Typically one of them is a leader of the cluster.
Leader, primary, source, master – what the node is called differs between datastores; what is important is that only one node typically assumes this role (there are also multi-master clusters). The master node’s responsibility depends on the database technology as well.
In Elasticsearch the master node is responsible for index management – it can delete or create an index – it also manages the shard allocation across nodes in the cluster. There must always be one master node available in the cluster and failover has to happen and a new master node elected when there is none.
What are the common cases for the failover to happen in an Elasticsearch cluster?
Network partitioning
Network, typically, is one of the most common reasons why Elasticsearch failover (or, to be honest, in most database clusters, not only Elasticsearch) happens. The reason can vary – an incorrectly configured firewall, problems with network software, problems with routers, etc.
Whatever is happening, the master node may be isolated from the rest of the cluster. In such cases, due to algorithms that are intended to prevent the situation where multiple master nodes are available and perform conflicting actions, a node will step down from its role and a new master node elected. The process is called election, we will cover it later in more detail.
Node failure
Another pretty common problem is a node failure. Failures happen. A VM can become unstable, hardware may break, the host server may experience service interruption. In that case, the master node may become unresponsive or even completely unavailable – it may crash, it may get corrupted, it may completely disappear.
These kinds of issues are not happening on a daily basis – hardware usually is quite resilient. The problem is scale – if you use just a dozen instances, you may not experience hardware problems almost at all. On the other hand, if you work with hundreds or thousands of nodes, a node becoming suddenly unavailable becomes something you have to consider as standard.
Such failure can leave the cluster without the master node. It is not feasible to operate in this state therefore, unless the unavailability is very brief, a new master node will become elected.
Software bugs
Last but not least, software may experience bugs. Nothing is ideal and there is no way to test all the aspects of a software in all possible combinations of hardware, operating systems and additional software that may be installed. This leads to the case where, under a particular set of conditions, Elasticsearch may start to behave incorrectly, even to the extent that it starts to crash. If the process crashes on the master node, a failover has to occur and a new master node has to be elected.
The importance of automated failover and how it’s implemented in Elasticsearch
As we have discussed, Elasticsearch cluster has to have a single master node. This is required for it to operate correctly and provide the functionality it is supposed to deliver. There is no other way to make sure your Elasticsearch cluster can sustain unexpected failure of the master node than ensuring it can perform an automated failover. Let’s take a look at what is required for the automated failover to happen.
Let’s first talk about the concepts and prerequisites that are important for the failover to conduct election of a new master node. One fundamental Elasticsearch node role is “master-eligible” – these nodes may assume the role of master and, typically, take part in the election process.
Then we have a quorum – the sum of all nodes that can vote for a new master. A quorum exists as long as a majority of the voting nodes is available. What it means is that some nodes may fail and the election process will not be impacted by that as long as enough nodes are available.
For example, if we have a cluster of three nodes and the master node fails, two nodes remain and two out of three is the majority (more than 50% nodes are available). In that case, one of those two nodes will assume the role of master. For a 5 node cluster, two nodes can fail and the remaining three will still be the majority and be able to proceed with failover and master election.
Based on this, we can say that a three node Elasticsearch cluster can tolerate a single node failure and a five-node cluster can tolerate a two-node — any more will impact the cluster.
The mechanism is intended not only to ensure promotion of a new master but also it is preventing split brain from happening. What it means is that, if the node is in minority, it will step down from its master role even if it is still up and running.
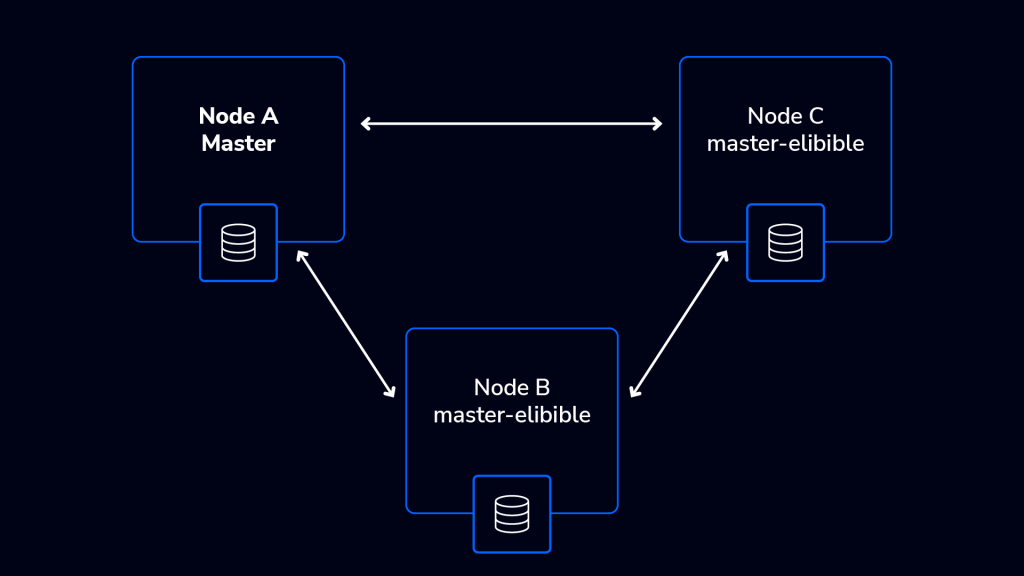
Let’s assume there is a network issue that affects the master’s ability to communicate with the other nodes.
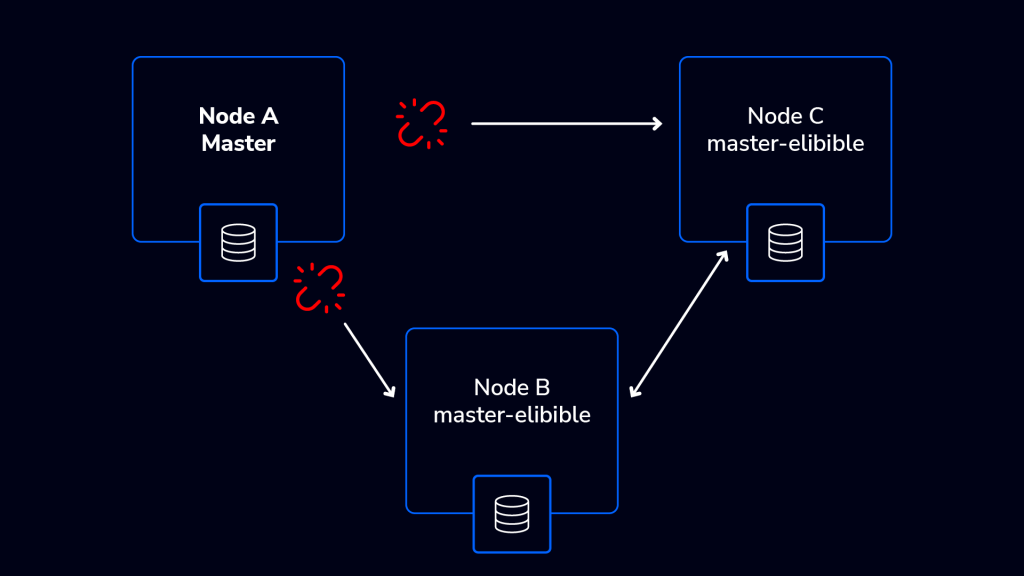
What happens next?
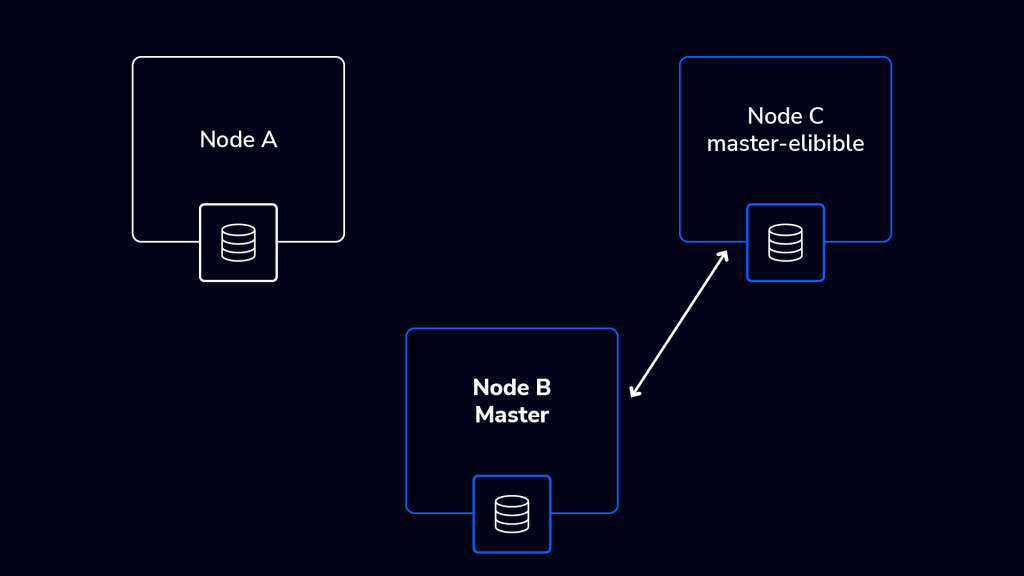
Node A steps down as a master node – it is in the minority – one out of three nodes. At the same time, nodes B and C have the quorum (2 out of 3) and perform an election in which node B has been picked up as a master node in the cluster. Although the cluster is degraded and cannot tolerate further failures for the time being, it will remain operational so long as another doesn’t occur before it re-establishes a third node.
Achieving automated failover for Elasticsearch in ClusterControl
As we have discussed earlier, failover in Elasticsearch clusters is automated and no additional steps are required except for properly setting the node roles when you deploy the cluster (or afterwards, it doesn’t matter).
In the case of ClusterControl for Elasticsearch, this is also automatically done for you by our software and it also simplifies other common operational tasks that become burdensome at scale, like deployment — I’ll take you through the steps.
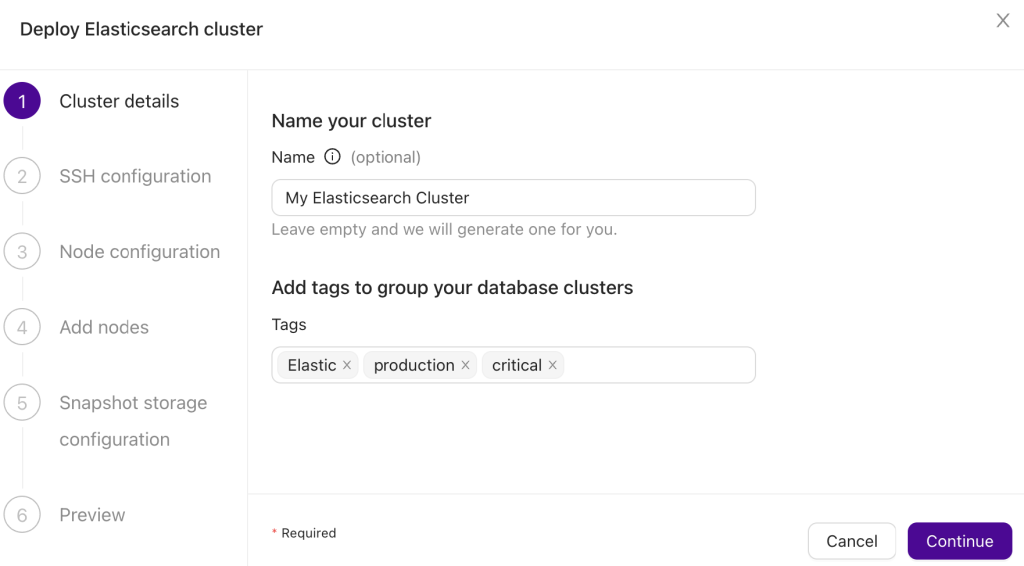
Pick a version and name the cluster
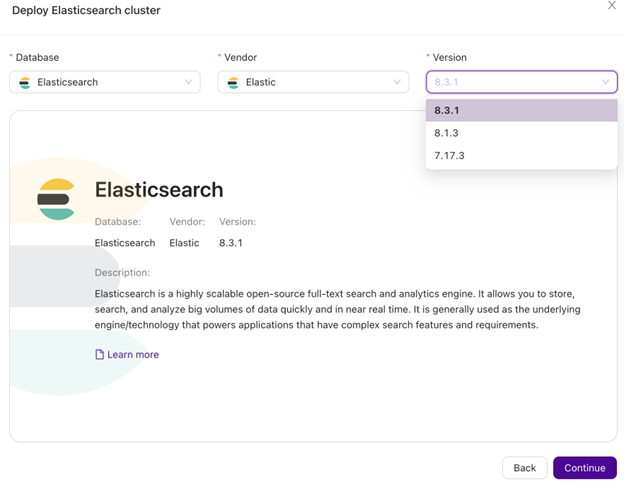
You have to start by picking the database type for the cluster (Elasticsearch) and the version that you want to install. In the next screen, you are supposed to define the cluster name. You can also tag it however you want.
SSH connectivity
As the next step we have to define how ClusterControl should connect to the nodes in the cluster.
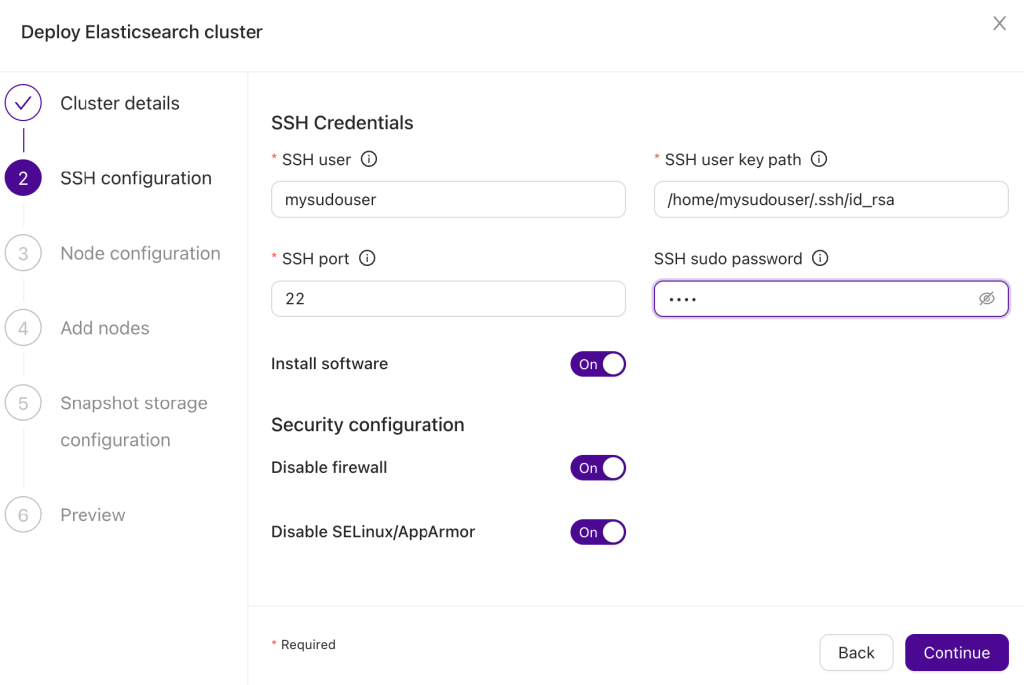
ClusterControl requires SSH connectivity to be in place. Connectivity should be done via passwordless SSH key. Both direct connection as root and sudo are supported. Sudo can be done using sudo password or without one.
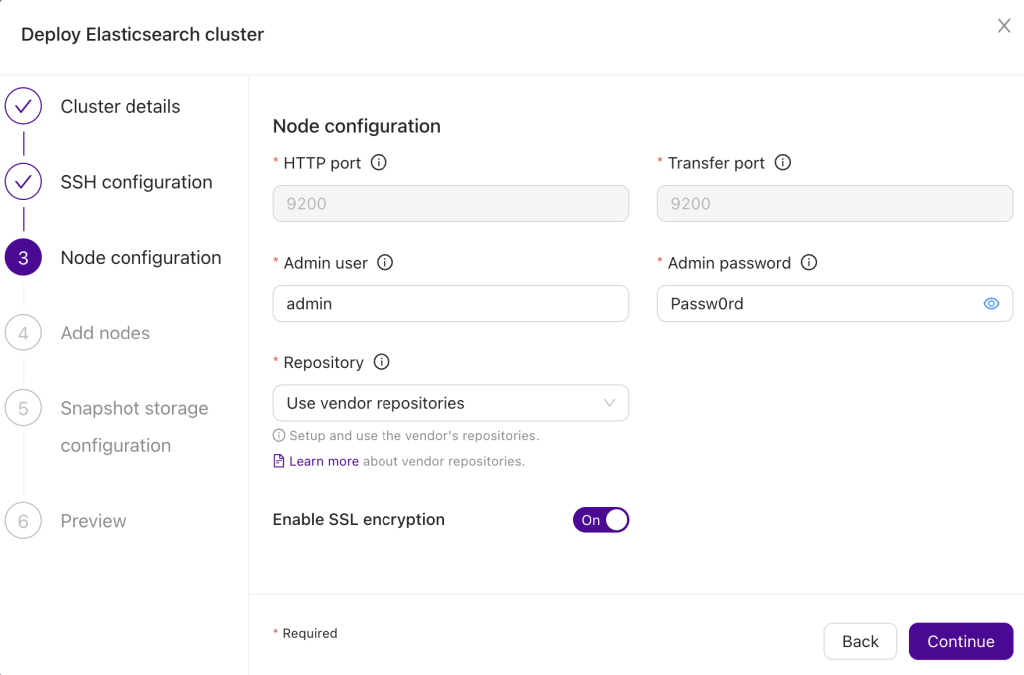
As the next step, we want to define details about the cluster – admin user and its password, repositories (ClusterControl can either setup vendor repositories or do not touch repository configuration and use whatever has been locally configured) as well as SSL encryption.
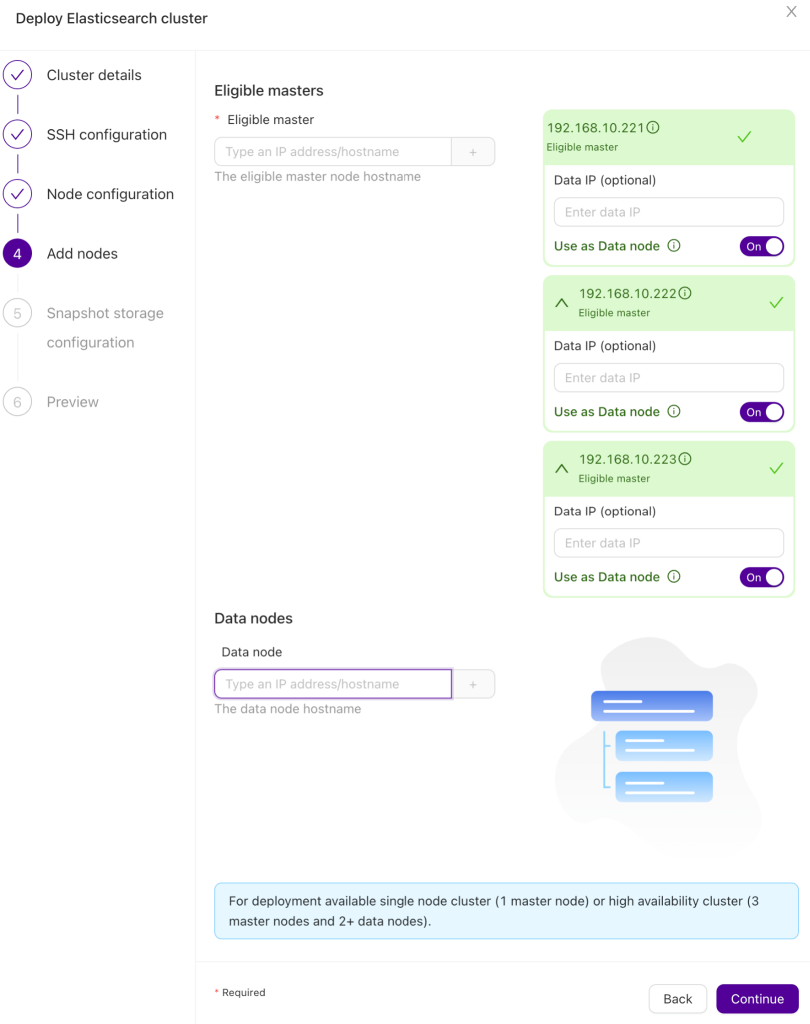
As a following step we have to define the nodes. ClusterControl requires them to be accessible via SSH through the method we defined in the previous steps — remember, you want to deploy three master-eligible nodes at minimum. Each of those nodes may also act as a data node but you can as well separate those roles across a larger volume of nodes.
As the last step we have to decide where the snapshots should be stored. ClusterControl can configure the shared storage (it will use NFS for that) so that it will be accessible for all of the nodes. Once this is done, ClusterControl will show you the summary of your choices and start the deployment process.
Wrapping Up
As you can see, Elasticsearch failover is something that you will probably experience at some point if you work with Elasticsearch in production environments. Luckily, ClusterControl can help you in deploying your Elasticsearch clusters in a way that they will be resilient and automated failover will happen if needed.
The ClusterControl platform is the only true alternative to the ELK Stack if you want to continue using Elasticsearch while getting orchestration help with your operational workload. Even better? You can run it in any environment you choose, even hybrid. So try ClusterControl free for 30-days (No CC required).



