blog
PostgreSQL Index vs InnoDB Index – Understanding the Differences

Considering the current major use-case of a database as to retrieve data, it becomes very important that its performance is very high and It can only be achieved if data is fetched in the most efficient possible way from storage. There have been many successful inventions and implementations done to achieve the same. One of the well known approaches adopted by most databases is to have an index on the table.
What is a Database Index?
Database Index, as the name suggests, maintains an index to the actual data and thereby improves performance to retrieve data from the actual table. In a more database terminology, the index allows fetching page containing indexed data in a very minimal traversal as data is sorted in specific order. Index benefit comes at the cost of additional storage space in order to write additional data. Indexes are specific to the underlying table and consist of one or more keys (i.e. one or more columns of the specified table). There are primarily two types of index architecture
- Clustered Index – Index data gets stored along with other part of data and data gets sorted based on index key. At most there can be only one index in this category for a specified table.
- Non-Clustered Index – Index data gets stored separately and it has a pointer to the storage where other part of data is stored. This is also known as secondary index. There can be as many indexes of this category as you want on a specified table.
There are various data structures used for implementing indexes, some of the widely adopted by the majority of databases are B-Tree and Hash.
What is a PostgreSQL Index?
PostgreSQL supports only non-clustered index. That means index data and complete data (here onward referred to as heap data) are stored in a separate storage. Non-clustered indexes are like “Table of Content” in any document, wherein first we check the page number and then check those page numbers to read the whole content. In order to get the complete data based on an index, it maintains a pointer to corresponding heap data. It’s the same as after knowing page number, it needs to go to that page and get the actual content of the page.
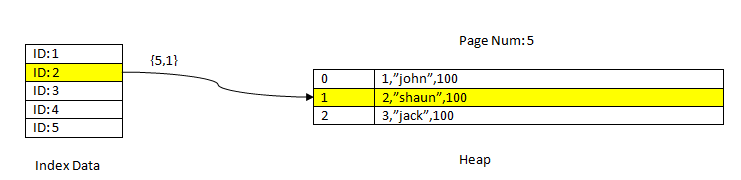
For example, consider a table with three columns and an index on column ID. In order to READ the data based on the key ID=2, first, the Indexed data with the ID value 2 is searched. This contains a pointer (called as Item Pointer) in terms of the page number (i.e. block number) and offset of data within that page. In the current example, the index points to page number 5 and the second line item in the page which in turn keeps offset to the whole data(2,”Shaun”,100). Notice whole data also contains the indexed data which means the same data is repeated in two storages.
How does INDEX help to improve performance? Well, in order to select any INDEX record, it does not scan all pages sequentially, rather it just needs to partially scan some of the pages using the underlying Index data structure. But there is a twist, since each record found from Index data, it needs to look in Heap data for whole data, which causes a lot of random I/O and it’s considered to perform slower than Sequential I/O. So only if a small percentage of records are getting selected (which decided based on the PostgreSQL optimizer Cost), then only PostgreSQL chooses Index Scan otherwise even though there is an index on the table, it continues to use Sequence Scan.
In summary, though Index creation speeds up the performance ,it should be carefully chosen as it has overhead in terms of storage, degraded INSERT performance.
Now we may wonder, in-case we need only the index part of data, can we fetch only from the index storage page? Well, the answer to this is directly related to how MVCC works on the index storage as explained next.
Using MVCC for Indexing
Like Heap pages, index page maintains multiple versions of index tuple but it does not maintain visibility information. As explained in my previous MVCC blog, in order to decide suitable visible version of tuples, it requires comparing transaction. The transaction which inserted/updated/deleted tuple are maintained along with heap tuple but the same is not maintained with index tuple. This is purely done to save storage and it’s a trade-off between space and performance.
Now coming back to the original question, since the visibility information in Index tuple is not there, it needs to consult the corresponding heap tuple to see if the data selected is visible. So even though other parts of the data from heap tuple is not required, still need to access the heap pages to check visibility. But again, there is a twist in-case all tuples on a given page (page pointed by index i.e. ItemPointer) are visible then does not need to refer each item of Heap page for “visibility check” and hence the data can be returned only from the Index page. This special case is called “Index Only Scan”. In order to support this, PostgreSQL maintains a visibility map for each page to check the page level visibility.
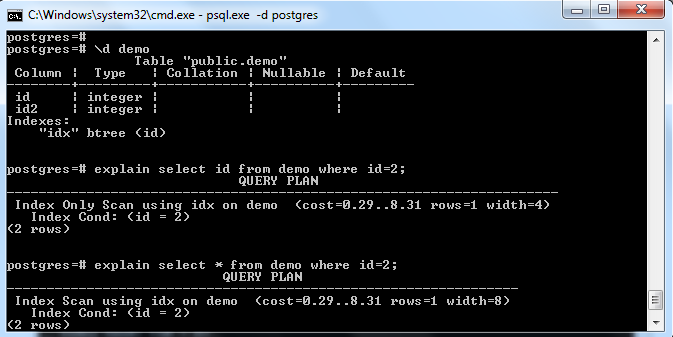
As shown in the above image, there is an index on the table “demo“ with a key on column “id”. If we try to select only index field (i.e. id) then it chose the “Index Only Scan” (considering referring page fully visible).
Clustered Index
There is no support of direct clustered index in PostgreSQL but there is an indirect way to partially achieve the same. This is achieved by below SQL commands:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]The first command instructs the database to cluster a table (i.e. to sort table) using the given index. This index should have been already created. This clustering is only one time operation and its impact does not remain after the subsequent operation on this table i.e. if more records are inserted/updated, the table may not remain ordered. If needed by the user to still keep table clustered (ordered) then they can use the first command without giving an index name.
The second command is only useful to re-cluster table (i.e. the table which was already clustered using some index). This command re-clusters all tables in the current database visible to the current connected user.
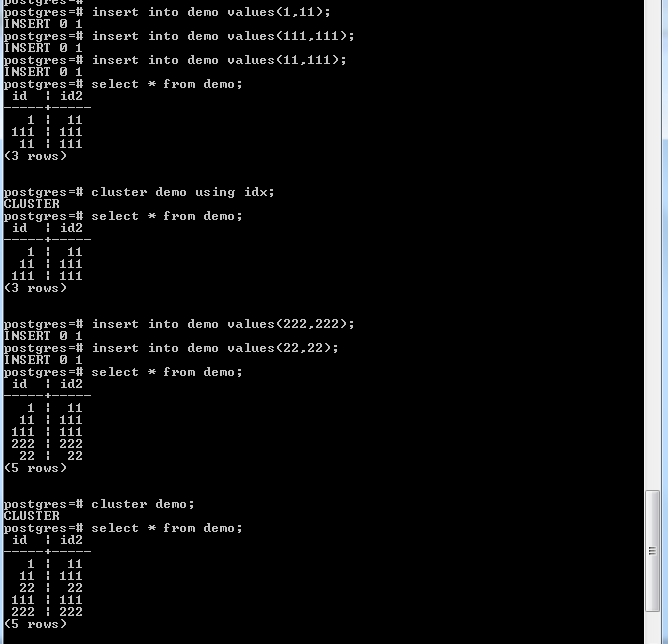
For example in the below figure, the first SELECT returns records in unsorted order as there is no clustered index. Even though there is already non-clustered index but the records get selected from the heap area where the records are not sorted.
The second SELECT returns the records sorted by column “id” as it has been clustered using index containing column “id”.
The third SELECT returns partial records in sorted order but newly inserted records are not sorted. The fourth SELECT again returns all records in sorted order as the table has been clustered again
Index Type
PostgreSQL provides several types of indexes as below:
- B-Tree
- Hash
- GiST
- GIN
- BRIN
Each index type implements different kinds of underlying data-structure, which is best suited for different types of queries. By default B-Tree index gets created, which is widely used indexes. Details of each index type will be covered in a future blog.
Misc: Partial and Expression Index
We have only discussed about indexes on one or more columns of a table but there are other two ways to create indexes on PostgreSQL
- Partial Index: Partial Index is an index built using the subset of a key column for a particular table. The subset is defined by the conditional expression given during create index. So with the partial index, storage space for storing index data gets saved. So the user should choose the condition in such a way that those are not very common values, as for more frequent (common) values anyway index scan will not be chosen. The rest of the functionality remains the same as for a normal index.
 Example: Partial Index
Example: Partial Index - Expression Index: Expression indexes gives another kind of flexibility in PostgreSQL. All indexes discussed till now, including partial indexes, are on a particular set of columns. But what if a query involves access of a table based on the expression (expression involving one or more columns), without an expression index it will not choose index scan. So in order to fast access this kind of queries, PostgreSQL allows to create an index on an expression. The rest of the functionality remains the same as for a normal index.
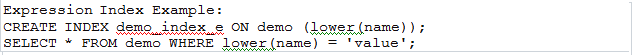 Example: Expression Index
Example: Expression Index
Index Storage in InnoDB
The usage and functionality of Index is mostly the same as that in PostgreSQL with a major difference in terms of Clustered Index.
InnoDB supports two categories of Indexes:
- Clustered Index
- Secondary Index
Clustered Index
Clustered Index is a special kind of index in InnoDB. Here the indexed data is not stored separately rather it is part of the whole row data. In other words, the clustered index just forces the table data to be sorted physically using the key column of the index. It can be considered as “Dictionary”, where data is sorted based on the alphabet.
Since the clustered index sort rows using an index key, there can be only one clustered index. Also, there must be one clustered index as InnoDB uses same to optimally manipulate data during various data operations.
Clustered index are created automatically (as part of table create) using one of the table columns as per below priority:
- Using the primary key if the primary key is mentioned as part of the table creation.
- Chooses any unique column where all the key columns are NOT NULL.
- Otherwise internally generates a hidden clustered index on a system column which contains the row ID of each row.
Unlike PostgreSQL non-clustered index, InnoDB access a row using clustered index faster because the index search leads directly to the page with all row data and hence avoiding random I/O.
Also getting the table data in sorted order using the clustered index is very fast as all data are already sorted and also whole data is available.
Secondary Index
The index created explicitly in InnoDB is considered to be a Secondary index, which is similar to PostgreSQL non-clustered index. Each record in the secondary index storage contains a primary key columns of the rows (which were used for creating Clustered Index) and also the columns specified to create a secondary index.
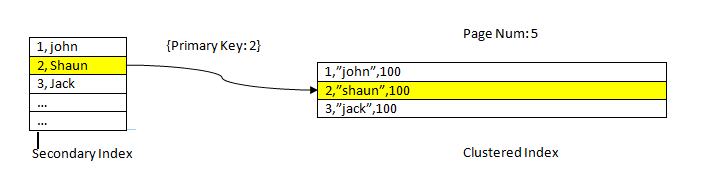
Fetching of data using a secondary index is similar as in-case of PostgreSQL except that InnoDB secondary index lookup gives a primary key as a pointer to fetch the remaining data from the clustered index.
For example, as shown in the above picture, the clustered index is on column ID, so table data is sorted by the same. The secondary Index is on column “name”, so as we can see the secondary index has both ID and name value. Once we lookup using the secondary index, it finds the appropriate slot with the corresponding key value. Then the corresponding primary key is used to refer to the remaining part of the data from the clustered index.
MVCC for Index
The clustered index MVCC usage the traditional InnoDB Undo Model (Actually the same as whole data MVCC, as the clustered index is nothing but whole data).
But the secondary Index MVCC usage a bit different approach to maintain MVCC. On update of the secondary index, the old index entry is delete-marked and new records are inserted in the same storage i.e. UPDATE is not in-place. Finally, old index entries get purged. By now you might have noticed that InnoDB secondary index MVCC is almost the same as that of PostgreSQL MVCC model.
Index Type
InnoDB supports only B-Tree type of Index and hence not required to be specified while creating index.
Misc: Adaptive Hash Indexes
As mentioned in the previous section that only B-Tree type index supported by InnoDB but there is a twist. InnoDB has the functionality to automatically detect if the query can benefit from building a hash index and also whole data of the table can fit into memory, then it automatically does so.
The hash index is built using the existing B-Tree index depending on the query. If there are multiple secondary B-Tree indexes, then it will choose the one which qualifies as per the query. The hash index built is not complete, it just builds partial index as per the data usage pattern.
This is one of the really powerful features to dynamically improve query performance.
Conclusion
The use of any index in any database is really helpful to improve READ performance but at the same time, it degrades INSERT/UPDATE performance as it needs to write additional data. So the index should be chosen very wisely and should be created only if the index keys are getting used as a predicate to fetch data.
InnoDB provides a very good feature in terms of the clustered index, which might be very useful depending on the use-cases. Also, its adaptive hash indexing is very powerful.
Whereas PostgreSQL provides various type of indexes, which can really give feature reach options and one or all can be used depending on the business use-case. Also the partial and the expression indexes are quite useful depending on the use case.



