blog
PostgreSQL Bi-Directional Logical Replication — A Deep Dive

PostgreSQL offers a robust, open-source, reliable, and flexible database system allowing businesses to scale their data operations effectively. PostgreSQL continues to improve to meet the needs of modern applications. One of its recent improvements is in its logical replication feature.
PostgreSQL logical replication replicates data from one node to another based on a replication identity, usually a primary key. The logical replication feature works with the publish-subscribe model, where a master database, called the publisher, can send data changes to other databases, called the subscribers.
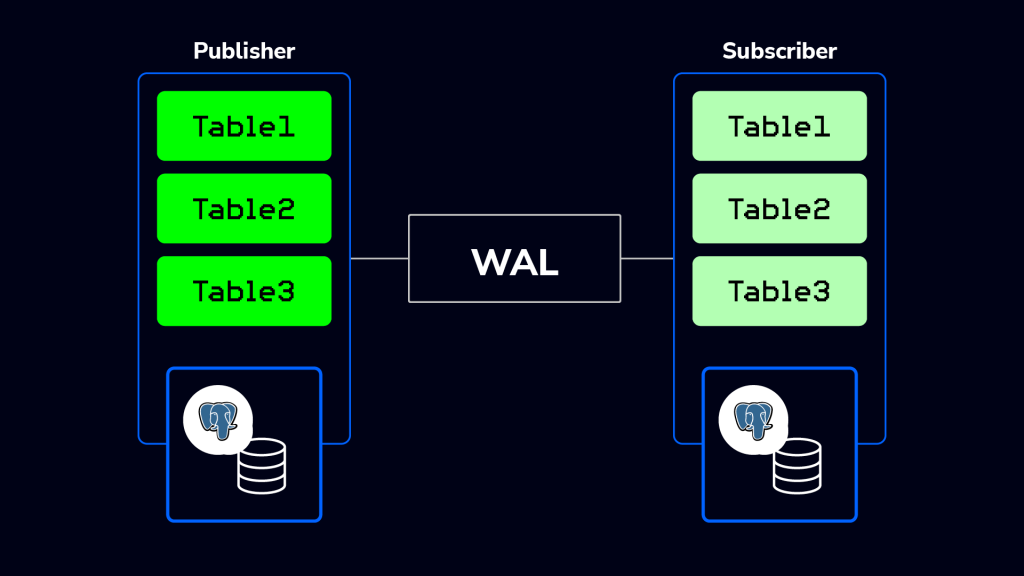
However, this model has a limitation. It supports only one data flow, from the publisher to the subscriber. When the subscriber nodes get updates, they do not send them back to the publisher. This makes it hard to manage read and write on multiple nodes simultaneously.
PostgreSQL added bi-directional logical replication in version 16 to solve this problem. Businesses with geographically distributed databases can perform read and write requests, and changes are streamed to each node smoothly while keeping data consistent and in sync.
With PostgreSQL’s bi-directional logical replication, updates made on one node can be replicated on other nodes and vice versa. This ensures data consistency throughout the system. It also uses the same publish-subscribe model, but here, each node acts as both the publisher and subscriber that sends and receives updates.
This blog will explore PostgreSQL’s bi-directional logical replication, its advantages, and its drawbacks. Towards the end, we’ll show you how ClusterControl can enable you perform bi-directional logical replication with ease, ensuring data consistency and scalability.
What is PostgreSQL Bi-Directional Logical Replication?
PostgreSQL bi-directional logical replication is a setup where two or more PostgreSQL databases can exchange data simultaneously. It is often called a multi-master replication.
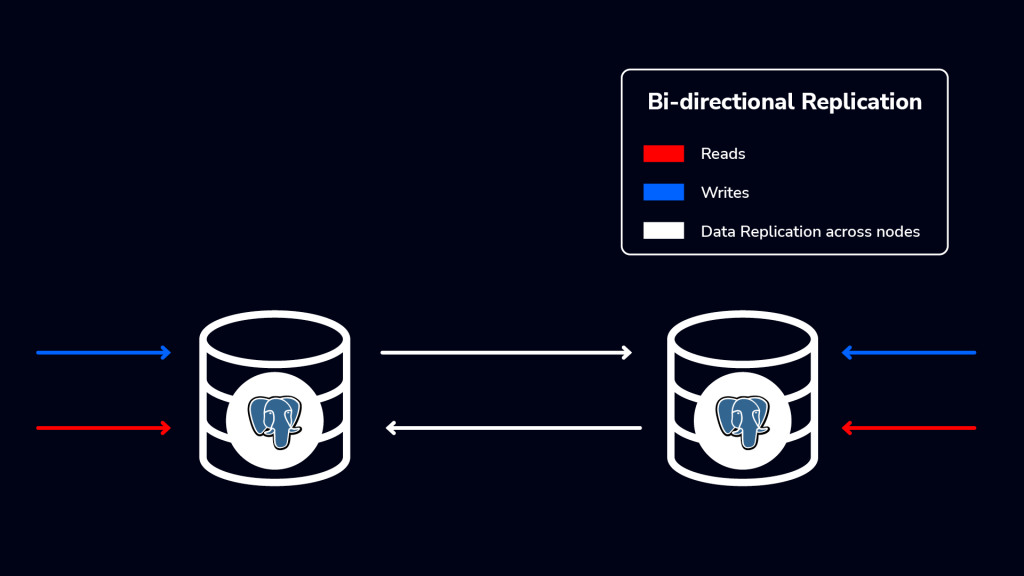
When you make changes in one database, they are automatically replicated to the other databases, creating a mirrored data environment across multiple nodes. All nodes are publishers and subscribers, meaning that they can both read, write, and replicate updates.
PostgreSQL enhances the WITH statement to enable bi-directional logical replication. It uses the WITH(ORIGIN = NONE) filtering option to ensure that only new data is replicated across nodes. This helps prevent issues like repeated replication loops caused by repeated changes from different nodes.
For example, one database creates data and sends it to a second one, detecting it as new data and replicating it. The cycle creates an endless replication loop within the nodes, which repeatedly copy the same data back and forth. The WITH(ORIGIN=NONE) option ensures that only the original data is shared and replicated.
Bi-directional logical replication is an asynchronous operation. This means that once you make any change on one database, it does not reflect immediately on the other nodes. Instead, these changes are propagated over time, allowing each node to continue processing transactions independently. This enhances high availability within all nodes, allowing each node to continue handling requests even if other nodes fail. This is beneficial for databases spread across different regions.
Pros and Cons of PostgreSQL Bi-Directional Logical Replication
Since bi-directional logical replication allows changes to be replicated in both directions, there are advantages and disadvantages. Here are some key advantages and challenges of using PostgreSQL Bi-Directional Logical Replication:
Pros:
Proper load balancing
Bi-directional logical replication enhances load balancing within the systems. Read and write operations can be distributed across multiple servers, improving the system’s performance. This setup ensures that no server is redundant, enhancing the overall efficiency of the infrastructure.
High availability and disaster recovery
With its active-active configuration, bi-directional logical replication improves the system’s high availability. This configuration ensures that the other nodes will operate seamlessly without interruption if one node goes down due to failure, a catastrophic event affecting a single location, or maintenance. In such a situation, applications connected to the databases can quickly failover to another node.
Geographically distributed data
For global applications, data can be replicated on servers in different regions. This reduces latency for users accessing the database from multiple locations.
Easy Data Migration and Synchronization
Bi-directional logical replication removes the complexities of data migration and synchronization, especially when moving across multiple versions.
Cons:
No schema consistency across all databases
For bi-directional replication to work effectively, all tables across the different databases must have the same structure (names and columns). Bi-directional logical replication does not replicate schema changes such as adding or removing columns, modifying constraints, or altering table structures. Only data changes (INSERT, UPDATE, DELETE) are replicated. If a schema change is required, it must be manually applied to all nodes to maintain consistency.
You must manually maintain schema consistency across all databases, which can take time from actual database maintenance.
Increased replication overhead.
Bi-directional replication requires applying and tracking changes and updates from multiple nodes. In the long run, it may lead to increased network traffic, and latency since more data is exchanged between replicas. It can also cause high CPU and memory usage.
Lack of automatic conflict resolution.
PostgreSQL Bi-directional Logical Replication lacks automatic conflict detection and resolution features. This means that when two nodes update the same row simultaneously, PostgreSQL cannot determine which one is more important. The lack of automatic conflict resolution leads to data inconsistencies, further complicating database management.
No native DDL replication across nodes.
PostgreSQL Bi-directional Logical Replication does not replicate Data Definition Language (DDL) changes. While it can propagate INSERT, UPDATE, AND DELETE operations across nodes, modification operations like ALTER TABLE, DROP COLUMN, and CREATE INDEX must be applied manually. Such a limitation leads to synchronization errors across all nodes, especially in a production setup.
Sequence co-ordination issues
Since PostgreSQL uses sequences for auto-increments, ID collisions may occur when different nodes insert records having the same sequence value. In a Bi-directional logical replication setup, sequences are not replicated. Each node generates its values differently, leading to duplicate primary keys on all the connected nodes.
Implementing PostgreSQL Bi-Directional Logical Replication
To demonstrate how PostgreSQL’s bi-directional logical replication works, in this article, you will set up two PostgresSQL databases on an Ubuntu system.
Step 1: Install PostgreSQL 16
On your server, ensure that PostgreSQL 16 is installed. If it’s not, start by adding the PostgreSQL APT repository using the following commands.
# Add PostgreSQL APT repository
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -After this, update the package list on your server, and install PostgreSQL 16.
# Update package lists
sudo apt-get update
# Install PostgreSQL 16
sudo apt-get install postgresql-16Step 2: Switch to the postgres user
To configure the databases, switch the postgres user using the following commands
sudo -i -u postgresStep 3: Create and Configure Databases
Now that the PostgreSQL version 16 is installed, configure two separate database clusters within the server using the following commands
# Initialize database clusters
pg_createcluster 16 database1 --datadir=/var/lib/postgresql/16/database1
pg_createcluster 16 database2 --datadir=/var/lib/postgresql/16/database2Here, the pg_createcluster creates new PostgreSQL clusters on the Ubuntu Server.
The --datadir= specifies where to store the data for the two clusters.
Next, set a unique port, and enable logical replication by editing the postgresql.conf configuration.
# For database1
echo "port = 5432" >> /etc/postgresql/16/database1/postgresql.conf
echo "wal_level = logical" >> /etc/postgresql/16/database1/postgresql.conf
# For database2
echo "port = 5433" >> /etc/postgresql/16/database2/postgresql.conf
echo "wal_level = logical" >> /etc/postgresql/16/database2/postgresql.confThe commands modify the postgresql.conf files for the database clusters created earlier, database1 and database2. It configures them to operate on different ports for logical replication. Setting these clusters on different ports prevents conflicts, and allows these clusters to operate on the same host.
Set the Write-Ahead Log (WAL) Level ( wal-level ) parameter to logical to ensure that the WAL contains enough information for logical decoding.
Also, to configure pg_hba.conf to allow all replication connections, add the following lines to both clusters’ pg_hba.conf files. To do this, navigate to /etc/postgresql/16/database1/pg_hba.conf and ensure this line is set to the following:
# Allow replication connections from localhost
host replication all 127.0.0.1/32 trustStep 4: Start each database instance
Start each PostgreSQL database instance using the following commands
# Start database1
pg_ctlcluster 16 database1 start
# Start database2
pg_ctlcluster 16 database2 startStep 5: Create tables in each database
In each database cluster you created, create a table called mytable with a column column1 using the following command:
postgres=# CREATE TABLE mytable (
column1 VARCHAR(255)
);Step 6: Create Publications
Connect to each database and create a publication:
-- On database1
postgres=# CREATE PUBLICATION pub_db1 FOR TABLE mytable;
-- On database2
postgres=# CREATE PUBLICATION pub_db2 FOR TABLE mytable;Step 7: Create Subscriptions with Origin Filtering
Here, you will set up subscriptions on each of the databases we created to subscribe to the publication. You’d use the origin = none parameter to ensure that there are no infinite loops:
-- On database1
postgres=# CREATE SUBSCRIPTION sub_db2
CONNECTION 'host=127.0.0.1 port=5433 user=postgres dbname=postgres'
PUBLICATION pub_db2 WITH (origin = 'none');
-- On database2
postgres=# CREATE SUBSCRIPTION sub_db1
CONNECTION 'host=127.0.0.1 port=5432 user=postgres dbname=postgres'
PUBLICATION pub_db1 WITH (origin = 'none');Step 8: Verify Replication
After the setup, test the replication on the database clusters by inserting data into mytable on database1 and verifying the appearance on database2
-- On Database 1
postgres=# INSERT INTO mytable (column1) VALUES ('test data');You’d see the following output below.
# On Database 2
postgres=# SELECT * FROM mytable;
column1
-----------
test data
(1 row)To test the bi-directional flow, insert data in database2 as well, and view it on database1 using the following commands
-- On database2
postgres=# INSERT INTO mytable (column1) VALUES ('test data2');You should see the following output
# On Database 1
postgres=# SELECT * FROM mytable;
column1
------------
test data
test data2
(2 rows)You would see the test_data row created in database1 in the table mytable on database2, and vice versa. This shows that the bi-directional replication works on the database clusters on the server.
From the demonstration above, you can see that cross-replication between two databases are possible. However, in a production environment where the number of databases increases as the complexity grows, it may be difficult to manage. Each additional database requires configuring publications and subscriptions, which would lead to a lot of connections that are difficult to manage and scale.
Also, as the number of these databases increases, there is a high chance of network latency because the time taken to replicate these changes will increase. This may impact performance, especially if these databases handle high transaction volumes.
PostgreSQL Bi-Directional Logical Replication with ClusterControl
ClusterControl automates the deployment, monitoring, and scaling of open-source databases such as PostgreSQL. It supports multiple distributions of PostgreSQL, such as vanilla PostgreSQL, PostgreSQL EnterpriseDB, and TimescaleDB, as well as extensions like pgvector and PostGIS, facilitating the deployment of highly available database clusters.
It provides automated failover mechanisms, load balancers like HAProxy, connection pooling with PgBouncer, and other tools for backup and restore operations.
ClusterControl enhances PostgreSQL’s replication features by providing automated deployment, management, and monitoring of replication setups. It allows real-time monitoring and alerting, allowing users to track the replication status.
After installing ClusterControl, you can reduce the steps to deploy and setup a PostgreSQL Logical replication cluster to a few steps and scale without the bottleneck of misconfigurations.
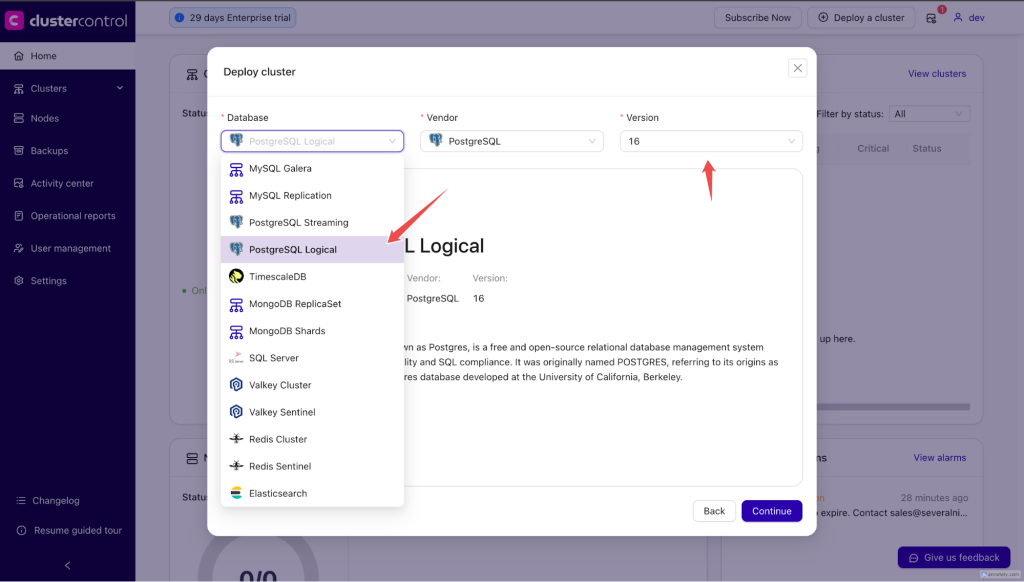
On the ClusterControl UI, select PostgreSQL Logical as the database flavor and the PostgreSQL version as in the image below.
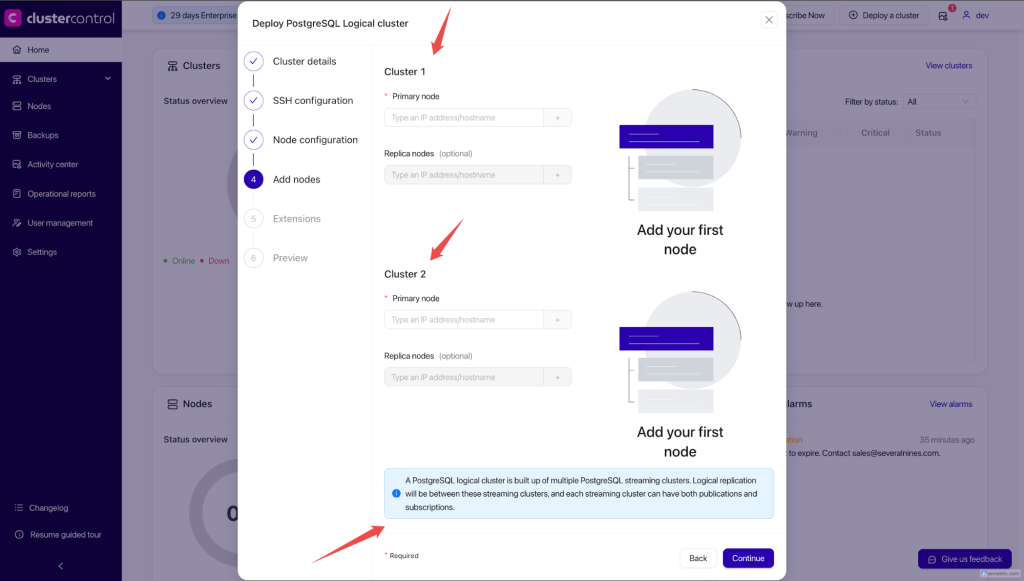
With a few configurations as in the image below, your PostgreSQL bi-directional replication cluster will be setup.
Enhancing PostgreSQL Bi-Directional Logical Replication with ClusterControl: A Scalable Solution
This blog explains bi-directional logical replication and how its concept transforms data management. However, managing bi-directional logical replication can be a hassle, especially in production systems with multiple databases in different regions.
Over time, production systems risk data inconsistencies due to conflicts, which may lead to system failures. While our demonstration shows a simplified approach, it is important to note that as the system scales up issues are bound to occur. This is where tools like ClusterControl work. It streamlines PostgreSQL’s setup, maintenance, scaling, and replication, ensuring that organizations have a resilient PostgreSQL infrastructure.
Install ClusterControl in 10-minutes. Free 30-day Enterprise trial included!
Script Installation Instructions
The installer script is the simplest way to get ClusterControl up and running. Run it on your chosen host, and it will take care of installing all required packages and dependencies.
Offline environments are supported as well. See the Offline Installation guide for more details.
On the ClusterControl server, run the following commands:
wget https://severalnines.com/downloads/cmon/install-cc
chmod +x install-ccWith your install script ready, run the command below. Replace S9S_CMON_PASSWORD and S9S_ROOT_PASSWORD placeholders with your choice password, or remove the environment variables from the command to interactively set the passwords. If you have multiple network interface cards, assign one IP address for the HOST variable in the command using HOST=<ip_address>.
S9S_CMON_PASSWORD=<your_password> S9S_ROOT_PASSWORD=<your_password> HOST=<ip_address> ./install-cc # as root or sudo userAfter the installation is complete, open a web browser, navigate to https://<ClusterControl_host>/, and create the first admin user by entering a username (note that “admin” is reserved) and a password on the welcome page. Once you’re in, you can deploy a new database cluster or import an existing one.
The installer script supports a range of environment variables for advanced setup. You can define them using export or by prefixing the install command.
See the list of supported variables and example use cases to tailor your installation.
Other Installation Options
Helm Chart
Deploy ClusterControl on Kubernetes using our official Helm chart.
Ansible Role
Automate installation and configuration using our Ansible playbooks.
Puppet Module
Manage your ClusterControl deployment with the Puppet module.
ClusterControl on Marketplaces
Prefer to launch ClusterControl directly from the cloud? It’s available on these platforms:



