blog
The New Way to Manage Open Source Databases

Not so long ago, the database industry consisted of a handful of vendors. Databases were mainly relational, and ran on single machines. High availability was implemented via active-standby ‘clusters’. With a vertical ’scale-up’ model, it was mostly about shared storage (SAN or DRBD) or asynchronous replication of logs to synchronize state to a standby node. In 2001, when I started working with NDB Cluster (what would later become MySQL Cluster), the concept of holding an entire database in main-memory was weird – ‘what if you switch off the server?’. Distributing a database across multiple servers was worrying – ‘you’ve got pieces of data here and there’. And the whole idea of an open source database for mission critical workloads was laughable.
Fast forward 15 years and we’ve now got dozens of database vendors on the market – mostly open source, different models (key value, document, graph, …) and distributed by default. Memory-resident data is pretty much the norm to achieve high performance and low latency. Three of the top 5 most popular databases (according to db-engines ranking) are open source (MySQL, PostgreSQL and MongoDB). Nowadays, you are more likely to manage a fleet of database servers distributed across different datacenters. You might even have some of your databases managed by a 3rd party cloud vendor.
So, what’s it like to manage databases in 2018?
AUTOMATION
With so many tasks to manage and only so many hours in a day, one would be mad to do things manually.
Automation is a great way to get things done. When we had few databases to manage, operating the database would be very hands-on, with some tasks scripted in something like bash or perl – e.g., a script to backup the database, another one to move backup files to some location. Failover would be manual, and we would even be debating whether it should be automated or not.

Nowadays, automation is a no-brainer. There are a number of IT automation or configuration management systems that can be leveraged – Puppet, Chef, Ansible and Salt all offer general-purpose frameworks that can be used to build automation for different database topologies. Cluster management software written specifically to manage database setups include MongoDB Ops Manager and ClusterControl. They enable the ops teams to manage their clusters with something which is readily available off-the-shelf. Building a cluster management system from scratch using a configuration management system is no small feat. It requires significant expertise in the automation tool as well as understanding of management operations like backup scheduling and verification, automatic failover with subsequent reconfiguration of systems, rolling out configuration changes, patching, version upgrade or downgrade, etc.
And of course, there is the rise of DBaaS service platforms, where deployment, health, failover, backups, etc., is all controlled by software. Cloud providers are indeed very good at automation. Amazon RDS is a great example of database automation at scale – it automates deployment, patch upgrades, backups, point in time restore, scaling of replicas and high availability/failover.
PETS vs CATTLE
In the 90’s and until the dotcom boom and bust, Sun Microsystems and Oracle made a fortune selling scale- up databases on big SMTP hardware. Throw in there some SAN storage and Veritas failover software and you’d have got yourself a state of the art active-standby failover cluster for high availability. Database servers were relatively few in numbers, but powerful as they would grow vertically. They were given names (just as you name your pets!), and were looked after by DBAs.

Nowadays, databases are cheap and run well on commodity hardware. There’s lots of them, and we give them numbers – just like cattle. If one breaks, we can just get a new one.

It’s also a new breed of cattle – open source cattle! Three of the top five databases, according to db-engines, are all open source – they’re slowly but surely eating away into the marketshare of the two proprietary vendors. Open source is the new datacenter standard, not just for operating system but also for databases.
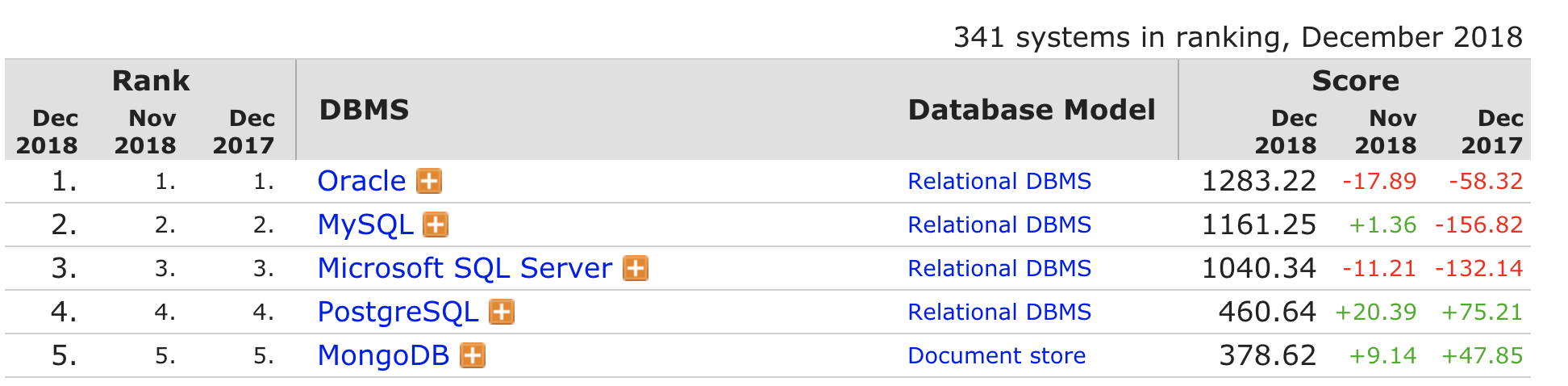
So what does this mean for you? Well, in the future, you’re more likely to be managing an open source database – or even multiple ones for applications using heterogeneous data collections. In a world of polyglot persistence and microservices, the underlying datastore is now dictated by the nature of the data. From an architectural point of view, single instance databases with disk-based HA are giving way to clusters that are potentially distributed across multiple datacenters.
Do we need a DBA?
The DBA role is a specialized one – it takes years of experience to become one. In the past, when there were only a couple of proprietary database vendors to choose from, you would have specialized DBAs with a specific set of skills and experience. It was also required – databases like Oracle or SQL Server have huge feature sets, built over decades. They are not easy to manage. They were typically deployed as the sole database for an application, and needed to be monitored, data backed up, and any issues that presented themselves had to be dealt with. These tasks were exactly what the DBAs were here to focus on.
In the past decade though, a whole new database industry has emerged – with dozens and dozens of open source databases, as well as cloud database services. As we saw earlier, it is not uncommon for an application to be using a couple of different datastores. But companies rarely have a DBA for these datastores they use. Where do you find a MongoDB or Cassandra or

Managing them would be just another task added to the todo list of the SysAdmin or DevOps or Site Reliability Engineering (SRE) team. And we see today that many companies do not have full-time DBAs. Responsibility is instead distributed across teams, with automation tools increasingly being used to take care of routine day-to-day tasks. For databases that have moved to the cloud, the operational aspects of how the data is being stored is outsourced entirely to the cloud provider. So instead of working on how to store data, the ops team can now focus on the use of the data.
Database Lifecycle
The average lifecycle of a database used to be much longer than what they are today. Once you chose a database platform, that was it. The decision would be made between two or three relational databases, usually by the DBA or somebody higher up in the organization. The company would find the money to purchase perpetual licenses. Once the decision was taken, you now had to live with it for the next 10+ years. Databases were monolithic, and applications would typically be using a single shared database.

Today, in a world of containers, cloud, microservices and CI/CD pipelines, it is not uncommon for developers to be making the technology choices – especially if it is an open source database that can be easily downloaded, or offered as a service, without having to speak to a sales rep, or having to seek budget from management. Organizations are being challenged to create value faster, so the rate of change to the infrastructure/applications has gone up dramatically. Monolithic databases are now split into multiple small databases, with each database managing domain data for an individual microservice. With the variety of database products available today in the open source ecosystem, teams have the choice and freedom to move to a better datastore. As services are commissioned and decommissioned, databases also follow – although the data itself might be archived or moved into a data lake. In an infrastructure landscape which is much more dynamic today, we find that our databases are living shorter lives.
DBA ROLE
The DBA, traditionally both guardian and gatekeeper of the database, would service the database needs of different application/infrastructure teams in the organisation. Any changes that required access or changes to the database would require the services of the DBA. However, conflicting priorities and lack of DBA availability could mean that the project would be blocked/delayed, and inevitable friction would follow.
High cost of collaboration and fast innovation/short time to market do not go well together. As we saw earlier, microservices is an example of how infrastructure and application services are now architected so as to decouple as much as possible. Databases are increasingly being automated, and control of the database is shifting to developers or project teams. Even things like schema changes are not as heavy as they used to be. They were much harder in the context of a central database for a monolithic application. With data being shared between different components, schema changes would need to be coordinated and careful planned – usually months in advance. DBAs had a key role in understanding and performing changes. The dynamics are different today, where the rate of change is much faster. It is not uncommon for development teams to be pushing code changes in production on a weekly or daily basis – or several times a day even! Databases need constant updates in order to keep up with application changes, and these are performed by developers. Some of the newer databases like MongoDB even make it very simple by having a schemaless model. What it effectively means is that the database schema is moving into the application code.

So if all the common core tasks are being automated away, what will happen to the DBA role in the future? Instead of focusing on administrative tasks, the DBA will function more as a mentor for other teams in the organisation. Organizations need to understand what data they have, and how that data can be put to use. After all, data is most valuable when shared and combined with other resources, not just stored. Schemaless sounds great, but we still need to keep track of our data – either in the database or in the code. Security is a challenge, and data breaches just keep getting worse. So if we are to make data great again, the DBA needs to shift to a horizontal advisor/enabler role that spans across teams. From a competence perspective, the modern DBA needs to understand how to design distributed high availability systems, and put in place efficient automation systems to take care of the mundane tasks. As companies deploy infrastructure across cloud or even container environments, understanding how to build highly available and scalable databases on these platforms will ensure the survival of the DBA.
Summary
We are sitting at a fascinating junction in the history of the database industry, which has gone through a massive transformation in the past 2 decades. The table below tries to summarize it.
| Old way | New way | |
|---|---|---|
| How? | Manual with help of scripts & tools/utilities | Automation via software (puppet, chef, ClusterControl) or DBaaS platforms. |
| What? | Few important DB instances, pets rather than cattle | Fleet of virtualized instances, polyglot persistence environment |
| Who | Specialized DBAs | “Everybody” – DBAs, SysAdmins, DevOps, Dev. |
| DBA role | Vertical role – DBA as guardian/gatekeeper, focus on traditional administrative tasks around logistics of data. | Horizontal role – DBA as mentor with focus on data. Shift towards non-operational tasks such as architecture, security, and strategy of data analysis/consumption/tuning. |
| Lifecycle | Long term lifespan, with changes planned in advance | Short to mid-term lifespan, with much faster rate of change |
| Competence | DB, OS, storage | DB, OS, Storage, distributed systems, networking & security, automation scripting |
I’d be interested to hear your thoughts on the open source database management and whether you’ve seen the same trends? What have your struggles or successes looked like with OSDBs in these past years? And what do you foresee happening next year?
We at Severalnines will continue to soldier on of course to help facilitate the management and automation of your open source databases into next year and beyond. So stay tuned for updates on that starting next January.
But in the meantime, do let me know your thoughts, and see you in 2019!
Photos by SoRad (Shutterstock) & The Simpsons; other photos are by their respective owners.



