blog
An Introduction to Data Lakes

The increase of unstructured data is a severe challenge to enterprises. Over the past decade, we could observe the rapid growth of data being produced and innovative changes to the way information is processed.
With the increasing number of portable devices, we can recognize the expansion of various data formats like binary data (images, audio/video) CSV, logs, XML, JSON, or unstructured data (emails, documents) which are challenging for database systems we knew.
Moreover maintaining data flows of each of various data access points cause trouble for commonly used data warehouses based on relational database systems.
It’s quite common that with the rapid application development companies may not even have a plan of how the data will be processed, but they have strong intent to use it at some point. While it’s possible to store unstructured data in the RDBMS system, storing it can be costly and complicated.
So how we can address all these problems?
In this blog, we would like to introduce you to the basics of an interesting “Data Lake” concept that may help you to address the mentioned challenges. We hope that this article will help you to get familiar with unstructured big data, especially if so far your main focus was on relational database systems.
What is a Data Lake?
A data lake is an abstract idea. In October of 2010, James Dixon, founder of Pentaho (now Hitachi Vantara), came up with the term “Data Lake.” In describing his concept, he said:
“If you think of a Data Mart as a store of bottled water, cleaned and packaged and structured for easy Consumption, the Data Lake is a large body of water in a more natural state. The contents of the Data Lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
From a more technical point of view, we can imagine a data lake as a repository that stores a vast amount of unprocessed data in its original format. While the hierarchical data warehouse systems store information in tables, a data lake uses flat architecture to store data. Each element in the “repository” has a unique identifier assigned and is marked with a set of metadata tags. When a business query arises, the catalog can be searched for specific information, and then a smaller, separated collection of data can be analyzed to help solve a particular problem.
The idea is simple: instead of placing data in a purpose-built data store, you move it into a data lake in its original format. This eliminates the upfront costs of data ingestion, like transformation. Once data is placed into the lake, it’s available for analysis by everyone in the organization.”
The data lake metaphor is developed because ‘lakes’ are a great concept to explain one of the basic principles of big data. That is, the need to collect all data and detect exceptions, trends, and patterns using analytics and machine learning. This is because one of the basic principles of data science is the more data you get, the better your data model will ultimately be. With access to all the data, you can model using the entire set of data versus just a sample set, which reduces the number of false positives you might get.
Data Lake vs. Data Warehouse
Data lakes and data warehouses are both widely used for storing “big data”, but they are not interchangeable terms. A data lake is a vast pool of raw data, the purpose for which is not yet defined while a data warehouse is a repository for structured, filtered data that has already been processed for a specific purpose.
Raw data is data that has not yet been processed for a purpose. The most significant difference between data lakes and data warehouses is the diverse structure of raw vs. processed data. Data lakes essentially store raw, unprocessed data, while data warehouses store processed and refined data.
Processed data is raw data that has been put to a particular use. Since data warehouses only house processed data, all of the data in a data warehouse has been used for a special purpose within the organization. This means that storage space is not wasted on data that may never be used.
Hadoop is Not a Replacement for MySQL
Data lakes are designed to handle large volumes of data and a large number of concurrent clients. It really shines when you operate it at scale. If the storage requirements of an application are not something that requires a distributed database. Such solutions are complementary, although since Hadoop MapReduce requires specific data processing knowledge, some companies try to combine the best from SQL and Hadoop.
Open Source Data Lake On-Prem Platform With SQL
SQL on Hadoop opens the doors for Hadoop to gain popularity in business because corporations do not have to invest in highly qualified personnel using eg. scripts written in Java.
Apache Hive has long been offering a structured, SQL-like language for Hadoop. However, commercially available alternatives provide greater efficiency and are continually getting faster (Cloudera Impala, Presto DB, Spark SQL).
An interesting idea here is to reuse your existing database clusters and combine into a single system. In November 2013 Facebook introduced Presto. Presto allows direct connection to various database sources, including Hive, Cassandra, relational databases or even proprietary data stores so the data is stored where it leaves.
Data Lake in the Cloud
Cloud providers are constantly increasing the range of services they offer and big data processing seems to be in the center of their focus. Let’s take a look at the three main cloud providers and how they support the idea of a data lake.
AWS S3 (Simple Storage Service)
AWS Cloud offers many “built-in services,” which can be used to create your data lake. The core service is Amazon S3, which is to store data storage, besides we can find :
- ETL platform AWS Glue,
- search and analytics platform Elasticsearch,
- Amazon Athena a query service to analyze data in Amazon S3 using standard SQL.
- Others which also can be used to create data lake (Amazon API Gateway, Amazon Cognito, Active Directory, IAM roles Amazon CloudWatch).
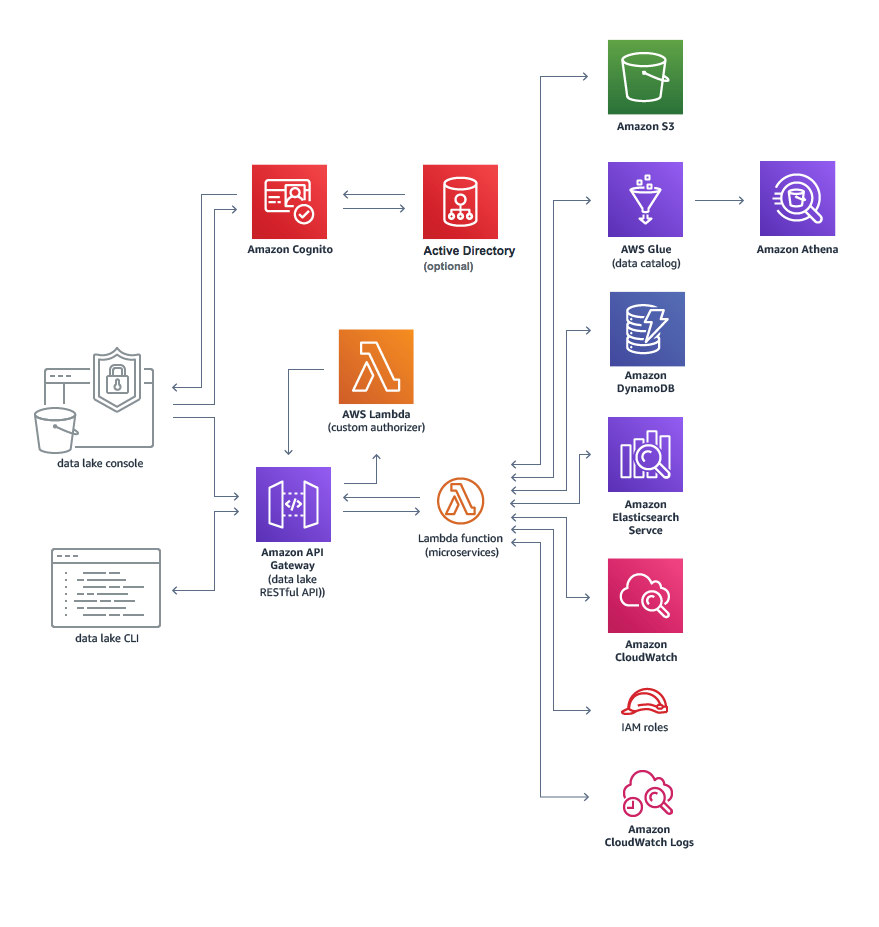
As mentioned, AWS S3 is the main component of AWS data lake. It provides unlimited storage and archival storage, respectively, including the functionality to replicate data to more than one geographic region.
With advanced S3 functionality such as “lifecycle management,” data can be archived for lower cost long-term storage and can be expired after a user-defined length of time, to manage your use of the service and associated costs automatically.
Massive-scale object stores such as AWS S3 (Simple Storage Service) provide effectively infinite storage capacity for your data, including backups, which simply could be another type of data that you may want to store in your data lake.
Google Cloud
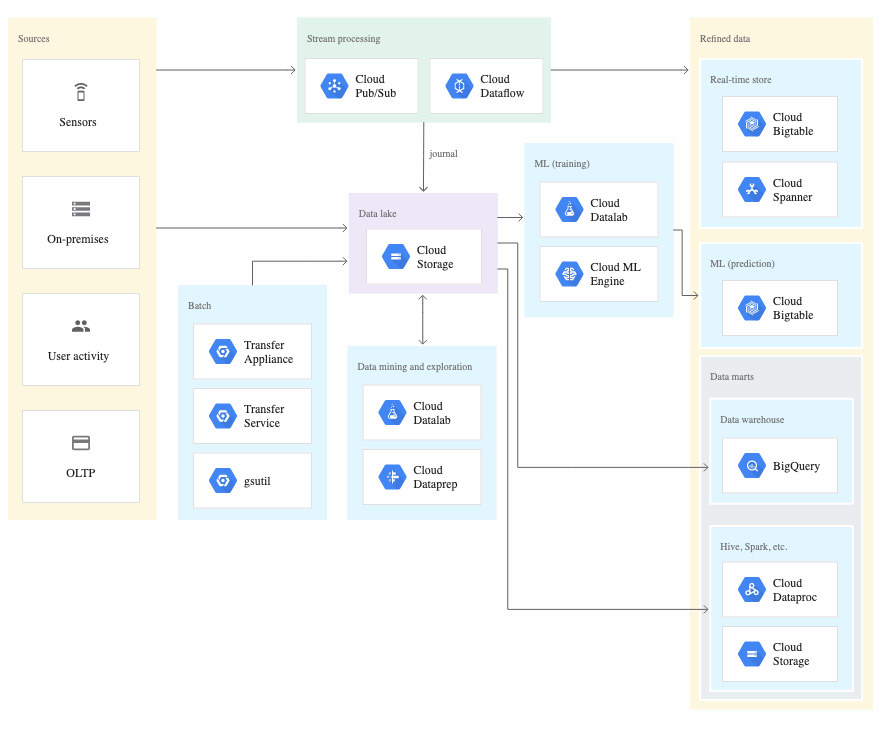
The equivalent of Amazon S3 in GCP is Google Cloud storage. Similar to S3, it offers unlimited capacity and severalnines annual durability (99.999999999%). Google highly promotes it’s Machine Learning capabilities. While it has the less build in services than Microsoft and AWS it still may be a good option, especially if you already have data processing pipelines in place.
Microsoft Azure ADLS Gen 2
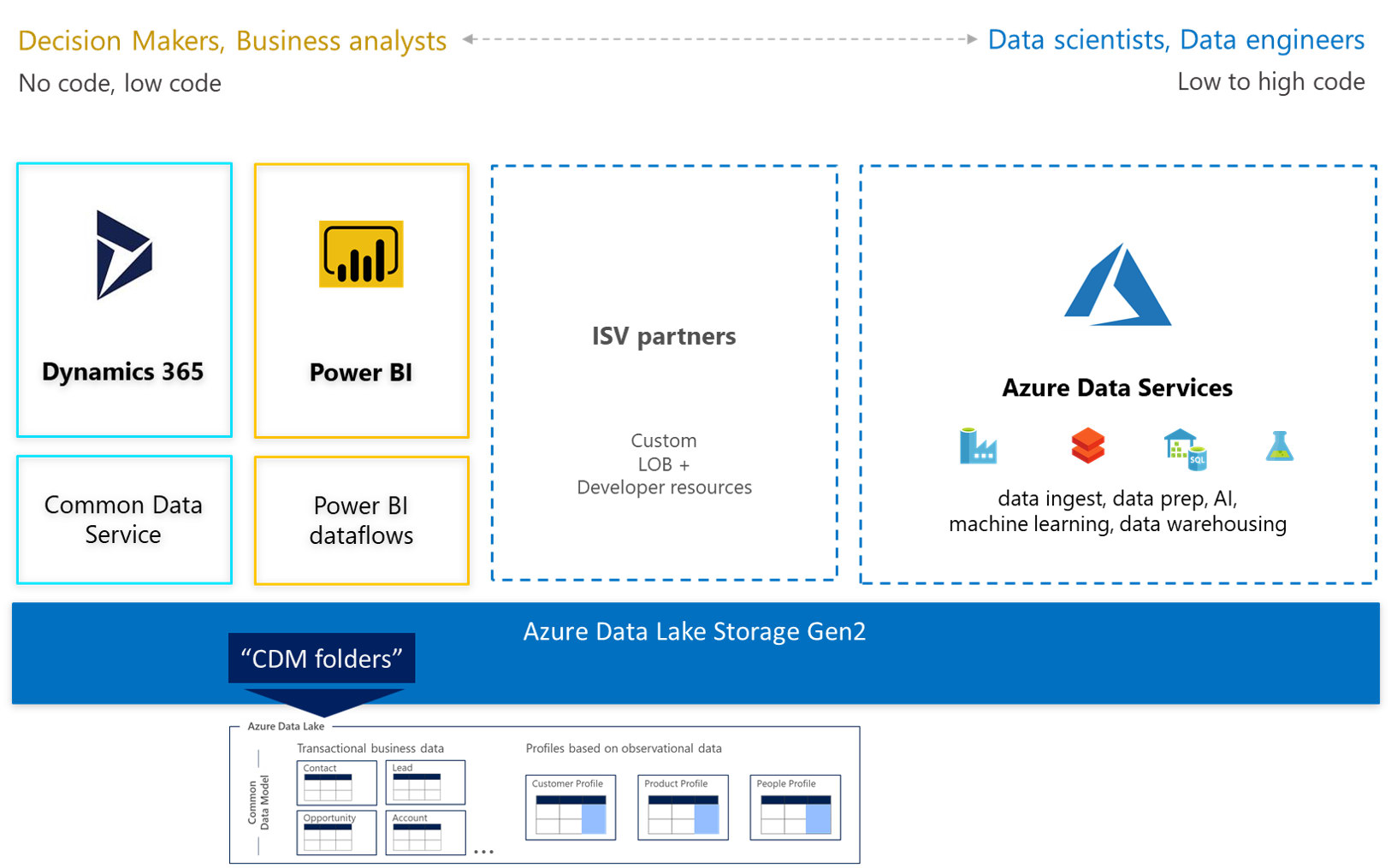
Microsoft offers dedicated objective storage for Data Lakes. It seems to be a mature solution with the support of various components either created by Microsoft or of well know services (HDInsight, Spark, U-SQL, WebHDFS).
In 2018 Microsoft introduced it’s the second generation of data lake implementation called ADLS Gen2. ADLS Gen2 is the combination of the Microsoft Data Lake solutions and Blob storage. ADLS Gen2 has all the features of both, which means it will have features such as limitless storage capacity, support all Blob tiers, Azure Active Directory integration, hierarchical file system, and read-access geo-redundant storage.
That’s all for part one. In the next section, we will show you how you can build your data lake using existing open source databases and SQL.



