blog
Implementing Sovereign DBaaS using ClusterControl and Conductor – Part II

In part I of this blog series, we talked about what a Sovereign DBaaS is and how you can use a software orchestrator such as Netflix Conductor to realize a Sovereign DBaaS in real life. A fundamental database lifecycle operation is to provision a virtual machine (VM) for and deploy a database cluster on that VM.
The VM can be created on any computing infrastructure platform, namely, VMWare vSphere/ESXi, Nutanix Prism, and public clouds (e.g., AWS, GCP, Microsoft Azure, Vultr, DigitalOcean). This helps companies whose IT strategy is to pursue a multi-cloud or hybrid deployment for databases and other business-critical software.
In part II of the series, we will show you how to create a database deployment workflow in three steps:
- Define a Conductor workflow with multiple tasks
- Define a task to create a VM in VMware vSphere/ESXi
- Define a second task to deploy a MySQL database on the VM using Severalnines ClusterControl
Conductor will be responsible for executing the overarching workflow and running its subtasks in the sequence the database deployment operation necessitates, e.g., procure the VM, then deploy the database using ClusterControl, handling any dependencies between the individual tasks. Conductor will also handle any errors that may result from running the individual tasks. The high-level diagram below shows the workflow and its tasks.
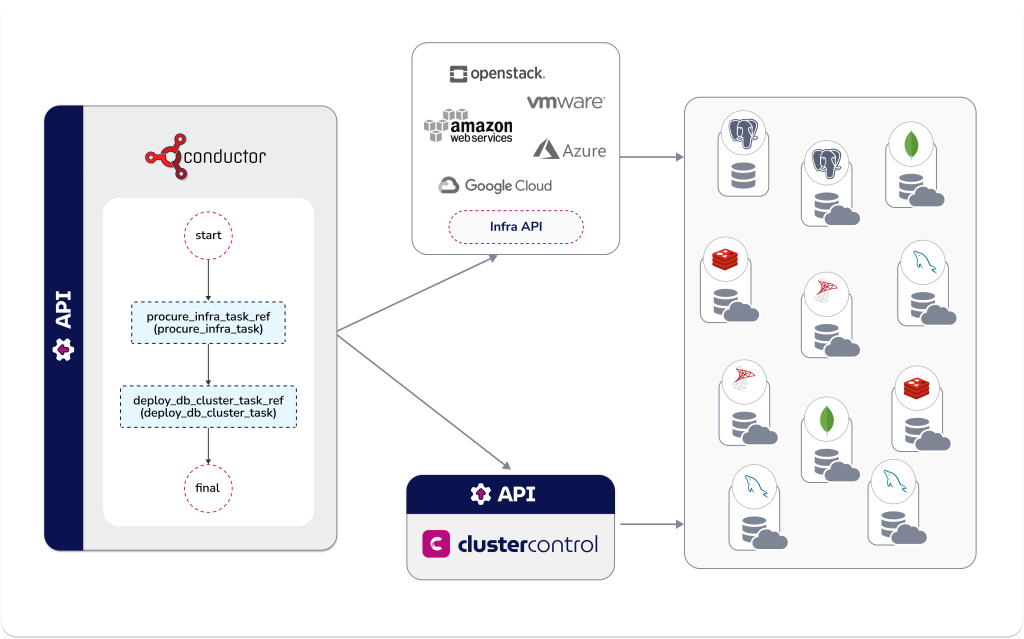
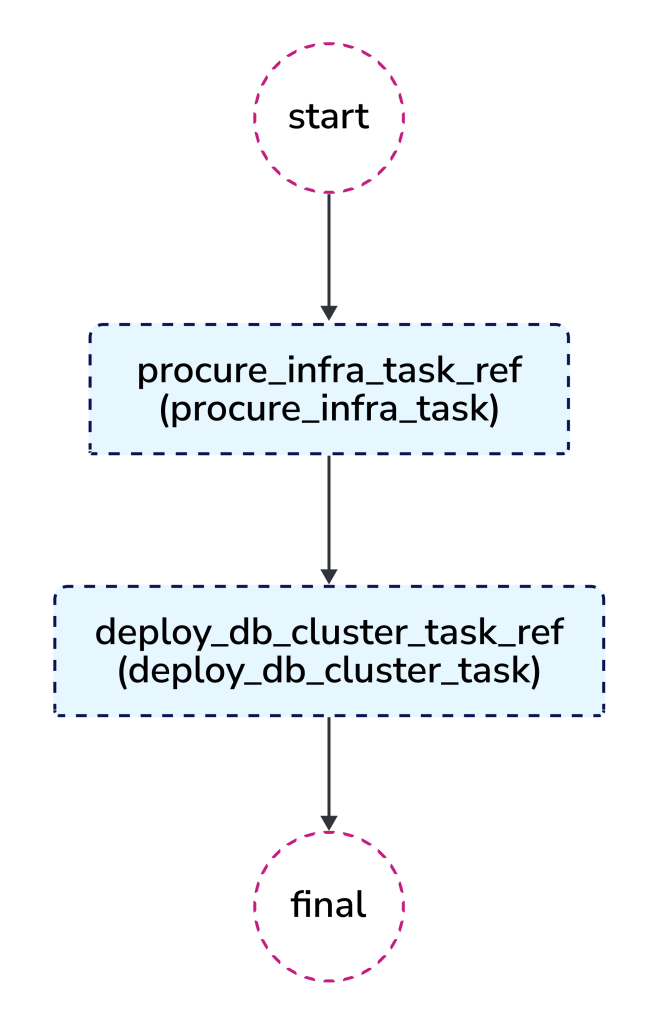
The procure_infra_task will procure a VM from VMware infrastructure and the deploy_db_cluster_task will deploy a MySQL database on the VM.
Setting up Netflix Conductor
Steps to set up and run Conductor are well-documented here. In addition to running the Conductor server, it is also important that, for the purposes of this demonstration, you run the Conductor UI component as well. We will use the UI component to define workflows (and define individual tasks), and kick off a workflow by providing it appropriate inputs.
Building ClusterControl for Conductor from source
The sources for ClusterControl integration with Conductor are available in github. Clone the repository and follow the instructions in the README to build the software from sources.
Defining Conductor workflows, workflow tasks, and inputs
We have defined a workflow that comprises two tasks.
- The first procures a VM from VMware vSphere with a predefined VM template or OVF template.
- The second deploys a MySQL database on the VM procured from the previous step.
The workflow definition is shown below (git). Copy the contents of the workflow and use it in the “Definitions” => “Workflow” to define the workflow in the Conductor UI.
{
"name": "create_database_cluster",
"description": "A workflow to procure infrastructure form vmware and then deploy a specified DB cluster on that infra.",
"version": 1,
"schemaVersion": 2,
"tasks": [
{
"name": "procure_infra_task",
"taskReferenceName": "procure_infra_task_ref",
"inputParameters": {
"cluster_name": "${workflow.input.cluster_name}",
"infra_provider": "${workflow.input.infra_provider}",
"infra_providers": "${workflow.input.infra_providers}",
"plan": "${workflow.input.plan}",
"nodes": "${workflow.input.nodes}",
"vcpus": "${workflow.input.vcpus}",
"ram": "${workflow.input.ram}",
"volume_size": "${workflow.input.volume_size}",
"tags": "${workflow.input.cluster_name}"
},
"type": "SIMPLE"
},
{
"name": "deploy_db_cluster_task",
"taskReferenceName": "deploy_db_cluster_task_ref",
"inputParameters": {
"plan": "${workflow.input.plan}",
"nodes": "${workflow.input.nodes}",
"cluster_name": "${workflow.input.cluster_name}",
"cluster_type": "${workflow.input.cluster_type}",
"vendor": "${workflow.input.vendor}",
"version": "${workflow.input.version}",
"port": "${workflow.input.port}",
"admin_user": "${workflow.input.admin_user}",
"admin_pw": "${workflow.input.admin_pw}",
"hosts": "${procure_infra_task_ref.output.hosts}"
},
"type": "SIMPLE"
}
],
"inputParameters": [],
"outputParameters": {
"cluster_id": "${deploy_db_cluster_task_ref.output.cluster_id}",
"controller_id": "${deploy_db_cluster_task_ref.output.controller_id}"
},
"failureWorkflow": "deploy_database_issues",
"restartable": true,
"workflowStatusListenerEnabled": true,
"ownerEmail": "[email protected]",
"timeoutPolicy": "ALERT_ONLY",
"timeoutSeconds": 0,
"variables": {},
"inputTemplate": {
"plan": "Startup_1c_2gb",
"nodes": 1,
"vcpus": 1,
"ram": 2,
"volume_size": 40,
"infra_provider": "vmware",
"infra_providers": [
{
"provider": "vmware"
}
],
"cluster_name": "conductor-cluster",
"cluster_type": "replication",
"vendor": "Percona",
"version": "8.0",
"port": 3306,
"admin_user": "root",
"admin_pw": "u5iw9sTv$qU2$"
}
}First, the VM procurement task from VMWare (git). Copy the contents of the below task and use it in the “Definitions” => “Tasks” to define the (workflow) task in the Conductor UI. Repeat for the second task as well.
{
"name": "procure_infra_task",
"description": "The task to procure infrastructure",
"retryCount": 0,
"inputKeys": [
"cluster_name",
"infra_provider",
"infra_providers",
"plan",
"nodes",
"vcpus",
"ram",
"volume_size",
"tags"
],
"outputKeys": [
"hosts"
],
"timeoutSeconds": 0,
"timeoutPolicy": "TIME_OUT_WF",
"retryLogic": "FIXED",
"retryDelaySeconds": 60,
"responseTimeoutSeconds": 3600,
"inputTemplate": {
"cluster_name": "mysql-replication",
"infra_provider": "vmware",
"infra_providers": [
{
"provider": "vmware"
}
],
"plan": "Startup_1c_2gb",
"nodes": 1,
"vcpu": 1,
"ram": 2,
"volume_size": 40,
"tags": "mysql-replication"
},
"rateLimitPerFrequency": 0,
"rateLimitFrequencyInSeconds": 1,
"ownerEmail": "[email protected]",
"backoffScaleFactor": 1
}Second, the task for deploying a MySQL database on the VM (git).
{
"name": "deploy_db_cluster_task",
"description": "The task to deploy database cluster on infrastructure",
"retryCount": 0,
"inputKeys": [
"plan",
"nodes",
"cluster_name",
"cluster_type",
"vendor",
"version",
"port",
"admin_user",
"admin_pw",
"hosts"
],
"outputKeys": [
"cluster_id",
"controller_id"
],
"timeoutSeconds": 0,
"timeoutPolicy": "TIME_OUT_WF",
"retryLogic": "FIXED",
"retryDelaySeconds": 60,
"responseTimeoutSeconds": 3600,
"inputTemplate": {
"plan": "startup_1c_2gb_40gb",
"nodes": 1,
"cluster_name": "mysql-replication-percona-8-conductor-test",
"cluster_type": "replicaiton",
"vendor": "Percona",
"version": "8.0",
"port": 3306,
"admin_user": "root",
"admin_pw": "u5iw9sTv$qU2$",
"hosts": [
{
"hostname": "10.0.0.4"
}
]
},
"rateLimitPerFrequency": 0,
"rateLimitFrequencyInSeconds": 1,
"ownerEmail": "[email protected]",
"backoffScaleFactor": 1
}Below is a sample input to the Conductor workflow (git).
{
"infra_provider": "vmware",
"plan": "startup_1c_2gb_40gb",
"nodes": 1,
"vcpus": 1,
"ram": 2,
"volume_size": 40,
"cluster_name": "mysql-replication",
"cluster_type": "replication",
"vendor": "percona",
"version": "8.0",
"port": 3306,
"admin_user": "root",
"admin_pw": "u5iw9sTv$qU2$",
"infra_providers": [
{
"provider": "vmware"
}
]
}Breaking it down…
You may be wondering about the code that handles calling VMWare vSphere/vCenter API to create the VM — it can be found in the VmWareVm Java class, which is instantiated if vmware is specified as the infra provider in the input to the workflow (see above). Note that there are certain assumptions made with deploying a VM.
We have assumed that a virtual machine template (or OVF template) has been pre-created and is available in VMware vCenter library with a specific library and template name and that the template contains the appropriate public SSH key in order for ClusterControl to SSH and install the database software.
Similarly, the deploy_db_cluster_task task will deploy a MySQL cluster on the VM. The deploy DB task will make use of the ClusterControl Java SDK to accomplish this. In future posts as part of this blog series, we will show you how to deploy PostgreSQL, MongoDB, Redis, MSSQL Server, Elasticsearch, and other clusters.
The Main Java class is used to start the application, i.e., Java Virtual Machine. The main class subsequently instantiates the task Java classes, namely ProcureInfraTask and DeployDClusterTask . How to set up credentials for VMware vCenter/vSphere and ClusterControl are specified in the top-level README of the git repository.
Wrapping up
In part II of this series, we have demonstrated how to automate a database deployment workflow consisting of setting up a VM and subsequently deploying a database cluster using Conductor as the workflow manager (or orchestrator). These concepts can be extended to other automation and workflow management software such as ServiceNow, VMware vRealize, Nutanix Calm, Uber Cadence, Orca, Dagster, Apache Airflow, etc.
In future posts of this series on implementing Sovereign DBaaS using ClusterControl and Conductor, we will show updated software to deploy multi-node HA database clusters of various types, namely Galera, MySQL replication, PostgreSQL HA, MongoDB sharded and replica set, Redis, MS SQL, and Elasticsearch clusters on the infrastructure of Amazon web services, Google cloud, Azure, Vultr cloud, DigitalOcean, etc.
In the meantime, read our Sovereign DBaaS whitepaper for more details on its features and characteristics. Follow us on LinkedIn and Twitter for future Sovereign DBaaS updates.



