blog
How to Schedule Database Backups with ClusterControl

Database backup is a critical part of database management and has to be carefully planned. Scheduling a backup is not enough; backup data also needs to be verified for consistency and integrity. There are other considerations like encryption, and archiving off-site. A good backup manager would have features that take into account all these different considerations.
In this blog post, we are going to look into how you can schedule your database backups with ClusterControl.
Database Backups using ClusterControl
ClusterControl supports a number of backup methods depending on the cluster type, as summarized in the following table:
When scheduling backup with ClusterControl, each of the backup methods is configurable with a set of options on how you want the backup to be executed. Different database workloads and backup strategies would require support for different features, for example:
- Disk IOPS throttling
- Network throttling
- Backup locks
- Encryption
- Compression
- Retention period
- Backup verification
- Cloud storage (offsite storage)
ClusterControl will automatically set a number of backup options, following the best practice from the particular database vendor. For example, if the target database node has binary log enabled, it will append an additional flag –master-data to include the binary log coordinates (file name and position) of the dumped server. If it’s a Galera node and the backup method is xtrabackup or mariabackup, ClusterControl will append an additional flag –galera-info which contains the local node state at the time of the backup.
Planning a Backup
Before we schedule any backup, we have to plan how the backup operation should be. Answering the following example questions would be helpful before you create a backup schedule:
- What backup method do you want to use? Some backup methods are non-blocking but very resource-intensive. Understand the tradeoffs, so you are not surprised about how the process behaves in production.
- How frequently do you want to backup your databases? Running a full backup might be painful if the backup interval is too short. You probably need a mix of full and incremental backups.
- How fast do you want to restore your data? Physical backup is usually way faster than a logical backup in terms of full restoration time. On the other hand, logical backup is commonly faster for partial restore.
- How big is your data size? In some cases, logical backup is not a good choice for huge databases, and binary backup is the only way to go.
- How much free space do you have to store your backup? Backups tend to eat a lot of space. Decide whether compression is needed and the compression level you can afford. Better compression requires higher CPU usage.
- What if the backup server is down during the backup time? Should it failover the backup to another available host? Skipping a backup due to a maintenance window is usually not a good idea.
- How to ensure the integrity of the created backup? Remember, a backup is not a backup if it’s not restorable.
- Do you trust backup storage? Encryption might be a good idea to protect your data.
Generally, by answering those questions, we can come up with an appropriate backup strategy. The list of questions could be longer depending on your backup and restoration policy.
We have covered this chapter in detail in our whitepaper, The DevOps Guide to Database Backups for MySQL and MariaDB.
Scheduling a Backup
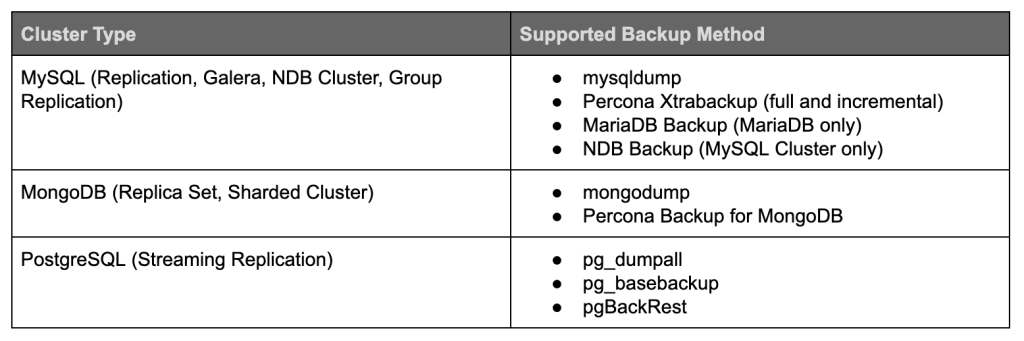
With ClusterControl, scheduling is pretty straightforward. Go straight to Backup → Create Backup → Schedule Backup, and you will be presented with the following dialog:
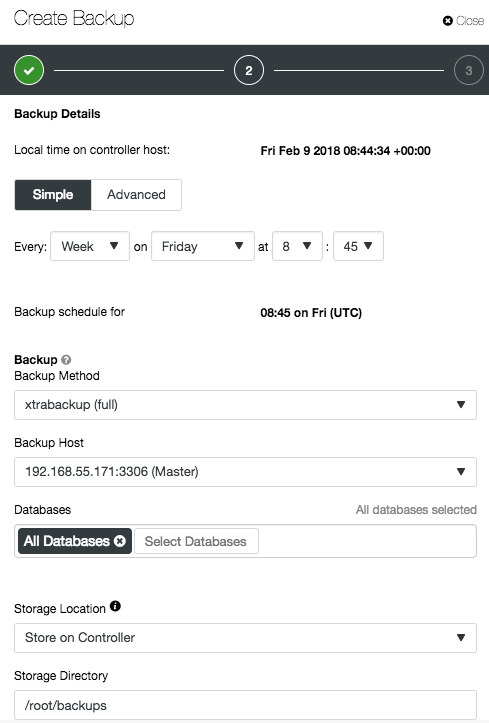
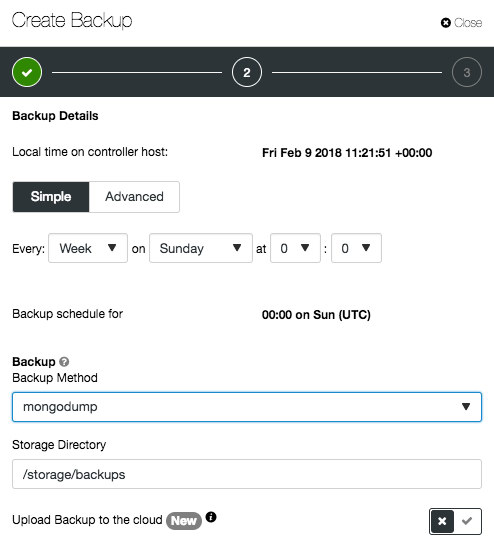
Depending on the cluster type, the options might be different, as shown in the following screenshots for PostgreSQL and MongoDB:
PostgreSQL:
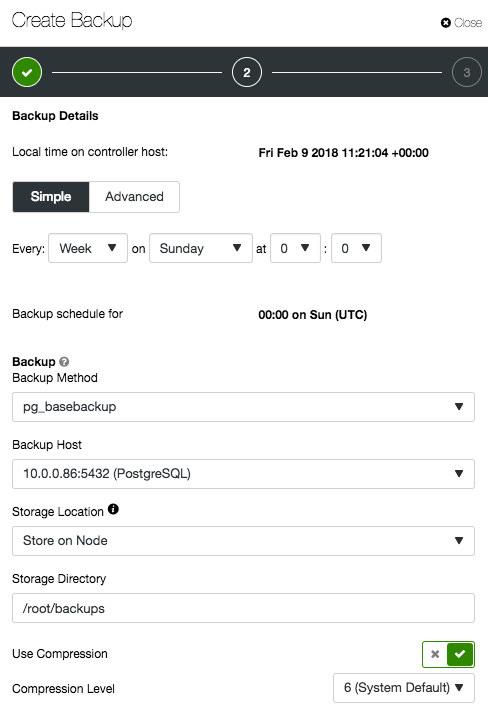
MongoDB:
Most of the options are self-explanatory and are covered in detail in the User Guide. Once the schedule is created, you can edit the configuration backups, enable/disable the backup or delete the schedule under the “Scheduled Backups” tab:

Take note when scheduling backups with ClusterControl, all time must be scheduled in the UTC timezone of the ClusterControl server. The reason behind this is to cut off the confusion of the backup execution time. When working with a cluster, the database servers could be spread out across different time zones and different geographical areas. Using one reference timezone to manage them all will ensure the backups are always executed at the correct time.
You can monitor the progress of a backup by looking at Activity → Jobs once the time has come. If the backup job failed, you would see the error right away:
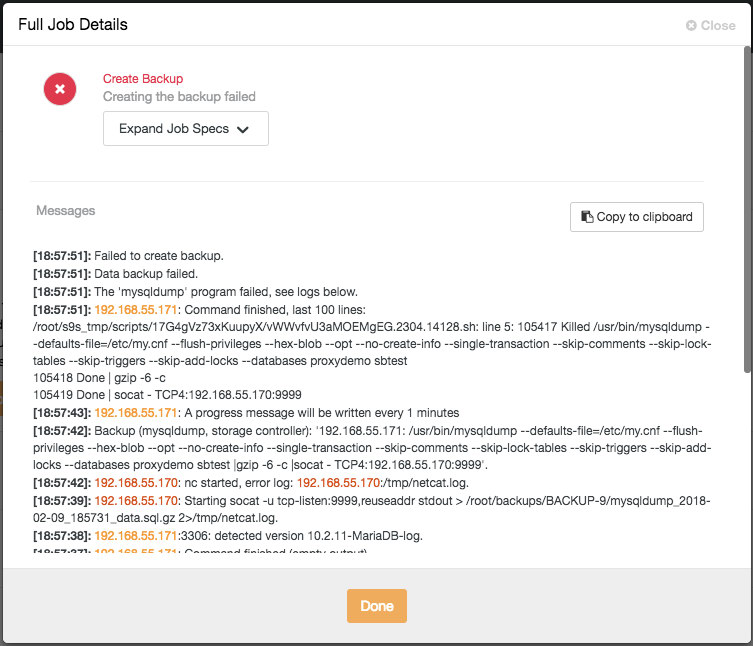
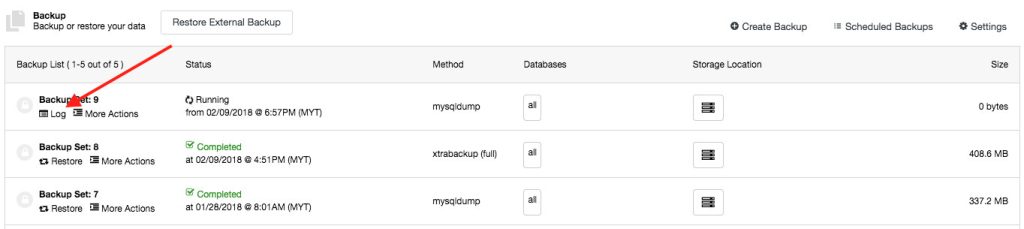
The above log is also accessible under the Backup tab on each of the backup entries:
Post-Backup Checks and Verification
Once the backup job is finished, it doesn’t mean data recovery responsibility is over. There are a couple of things that need to be followed up upon. The most important one is the state of the created backup. ClusterControl provides email notifications and will notify you about the status. This notification service is of course configurable based on the severity under Side Menu → Email Notifications → Backup Logs:
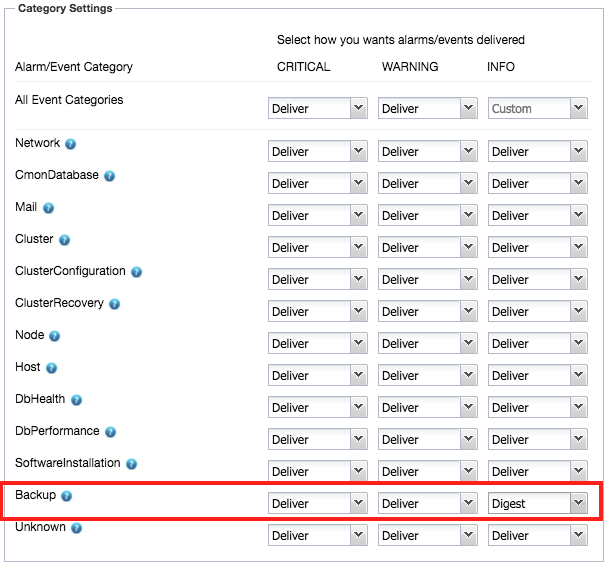
Deliver means ClusterControl will send an email notification immediately after an alarm for this component is raised. You could also configure it as “Ignore”, or “Digest”, where ClusterControl sends a daily summary of alarms raised.
If the backup is successfully created, it’s highly recommended to verify if the backup is restorable. You can use the Backup Verification feature by clicking on the “Restore” button of the chosen backup ID, and you will be presented with two restoration options:
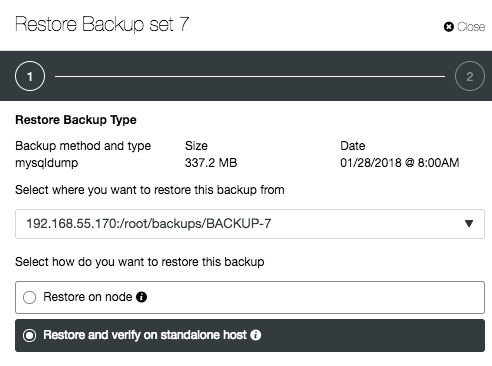
“Restore and verify on standalone host” requires a separate host, which is not part of the database setup. ClusterControl will first install the database service on the target host, start the service, copy the backup from the backup repository and start the restoration process. Once completed, you can have an option to either shut down the backup verification server after it is restored or let it run so you can conduct further investigation on the server.
Housekeeping is also important in order to keep only the useful backups in your storage. Thus, configure the backup retention as necessary. By default ClusterControl purges backups that are older than 30 days. You can also customize each of the backup schedules with different retention periods.
If the backup storage is approaching any space limits, or you want to archive your backup offsite, you can choose to manually delete the file by clicking on the trash bin icon or upload it to the cloud, as highlighted below:
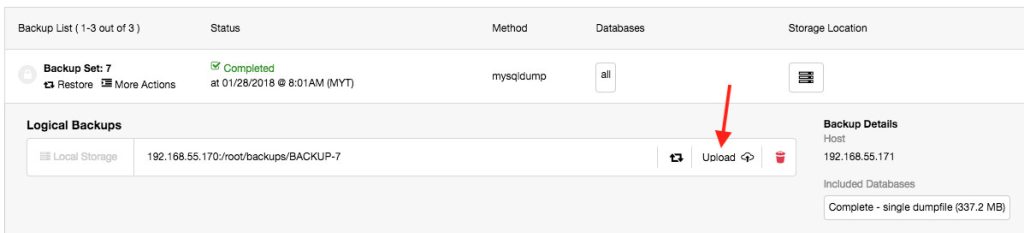
At the time of writing, AWS S3 and GCP Cloud Storage are supported. The cloud credentials must be pre-configured under Side Menu → Integrations → Cloud Providers.
Final Thoughts
The ClusterControl backup feature is considered one of the most sophisticated database backup management systems for your open-source databases. ClusterControl supports multiple database backup methods and destinations, backup encryption, compression, notifications, restoration, throttling, retention management, and off-site backups, and it is built and tested for production system use-cases.
Scheduling your database backups with ClusterControl is straightforward and gives you peace of mind knowing that data recovery is possible if needed. A comprehensive database backup strategy is not only smart from a data management point of view; it’s business critical. Try ClusterControl for free for 30 days and see for yourself!
Read more about how backup ClusterControl retention management allows you to manage your backup storage space efficiently without compromising your database recovery policy.
To keep up to date with all ClusterControl news, follow us on Twitter and LinkedIn and subscribe to our newsletter.



