blog
A Guide to Database Backup Archiving in the Cloud

Having a backup plan is a must when running a database in production. Running a backup every day, however, can eventually lead to an excess of backup storage space, especially when running on premises.
One popular option is to store the backup files in the cloud. When it comes to cloud storage, we don’t need to be worried if the disk is exhausted as the cloud object storage is unlimited. Disaster recovery best practices recommend that backups should be stored offsite. While cloud storage is unlimited there are still concerns about the cost, as the pricing is based on the size of the backup file.
In this blog, we will discuss backup archiving in the cloud and how to implement a proper backup policy and ultimately save costs.
What is Object Storage in the Cloud?
Object storage is a data storage architecture that stores the data as objects. This is different when compared to other storage systems which manage the data as a file system or block storage which manages the data as evenly sized blocks of data. There are several types of storage based on how users access their data, which are…
- Hot storage, the data need to be accessible instantaneously.
- Cool storage, the data is accessed more infrequently.
- Cold storage, the data archival storage, which is rarely accessed.
AWS has an object storage service platform called the S3 (Simple Storage Service). It is a platform for storing object files in a highly scalable way. Data is durable and provides relatively fast access. You can store and retrieve any kind of data. It is used for data that requires infrequent access. Another platform offered by AWS is S3 Glacier, which offers cold storage of data. It is ideal for storing older database backups.
GCP (Google Cloud Platform) also provides an object storage service called GCS (Google Cloud Storage). There are several types of cloud storage based on how often the data is accessed, they are: Standard (used for highly frequent access), Nearline (used for data accessed less than once a month), Coldline (used for data accessed less than once a quarter), and Archive (used for data accessed less than once a year).
Azure provides three different access tiers called Azure Blob Storage. Hot Storage is always readily available and accessible. Cool Storage is for infrequently accessed data and Archive storage is used for rarely accessed data.
The colder the storage, the lower the cost.
Creating a Backup Archival Policy
ClusterControl supports backups to the cloud which currently supports three cloud providers (AWS, Google Cloud Platform, and Azure). For more cloud provider options, we also have our Backup Ninja tool.
ClusterControl also supports having a backup retention policy in the cloud. This allows you to determine how long you want to keep the backup database which is stored in the object storage. You can configure the retention policy in Backup Settings as shown below.
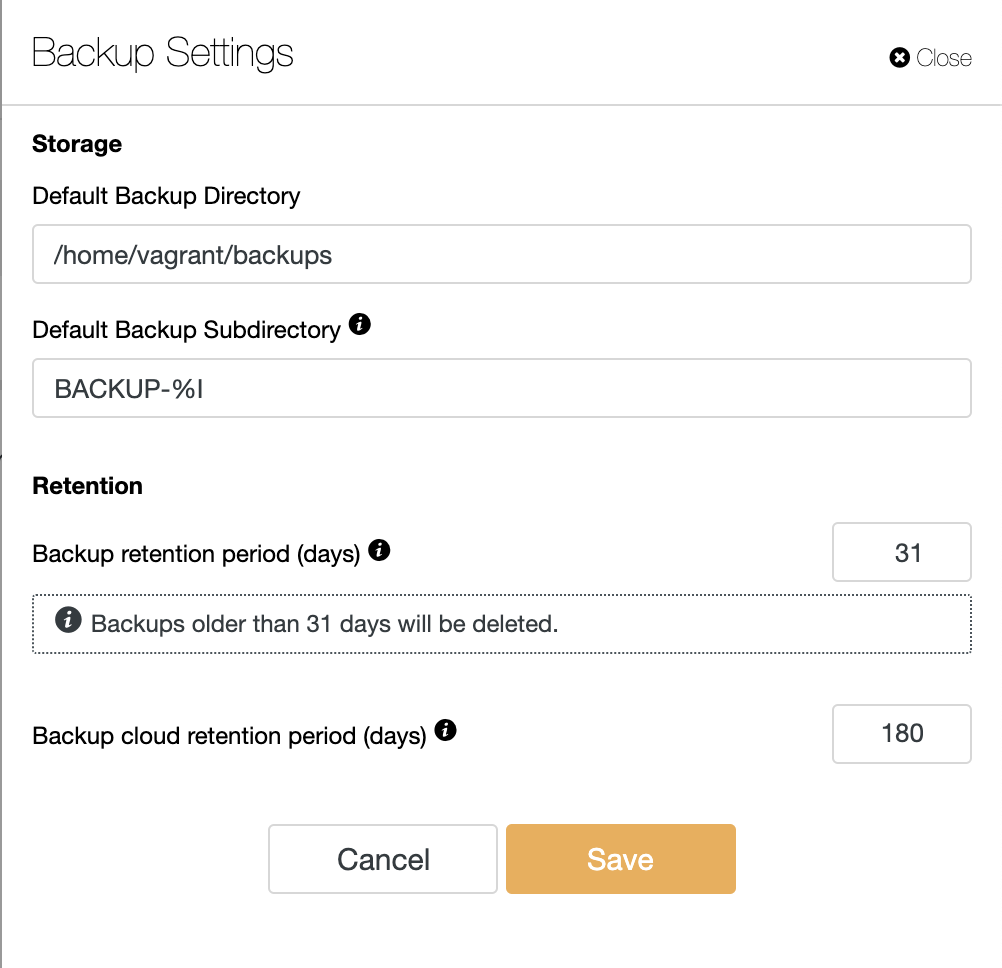
It will remove the backup that is stored in object storage. This backup retention policy can be combined with the archiving of the database backup that is stored in object storage on each cloud provider.
AWS has lifecycle management for archiving database backup from S3 to Glacier, to enable the archiving policy, you need to add lifecycle rules in Management Lifecycle for your S3 bucket.
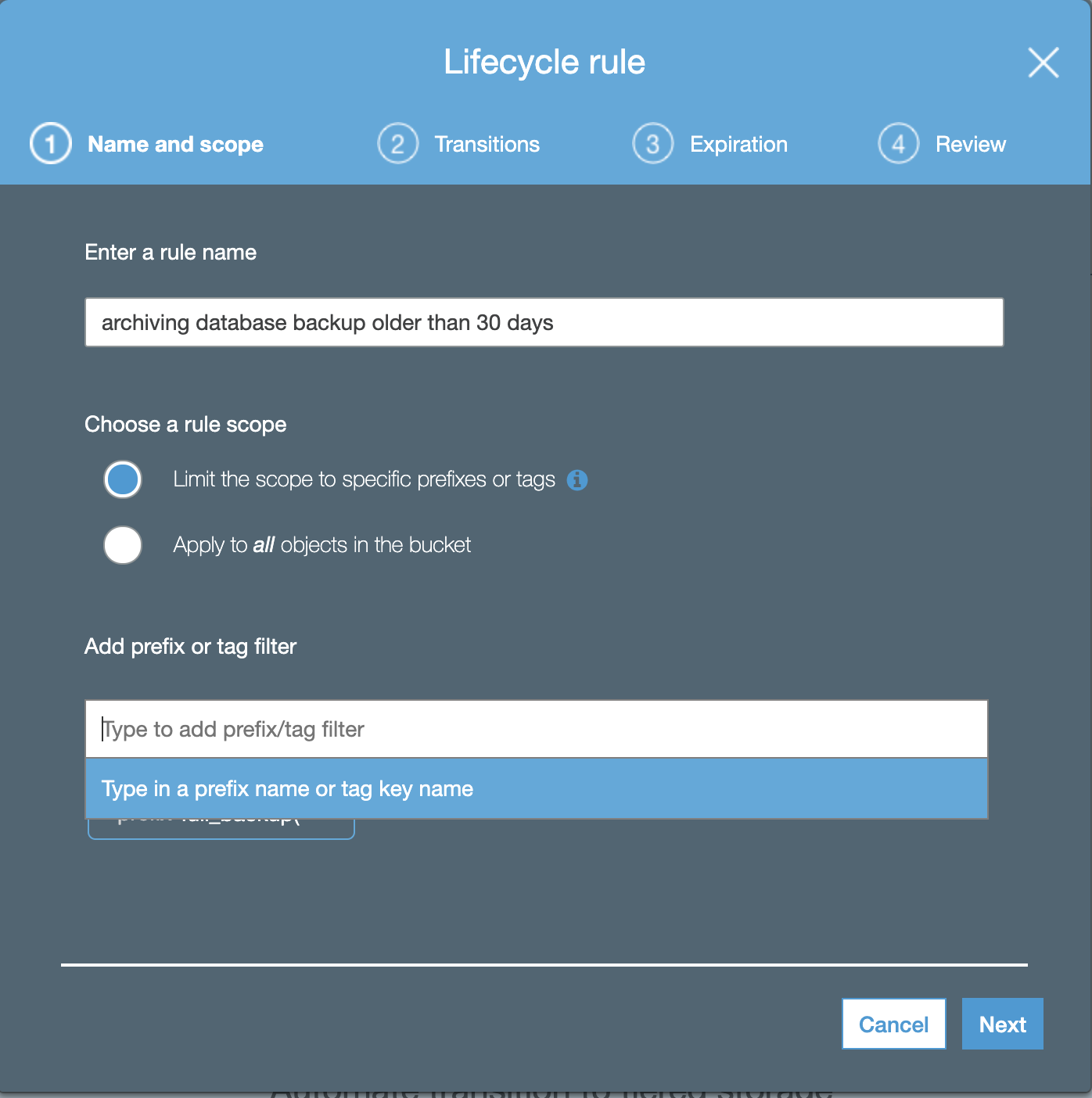
Fill the rule name and add the prefix or tag the filter, after that click Next, and you need to choose the Object creation transition and Days after creation.
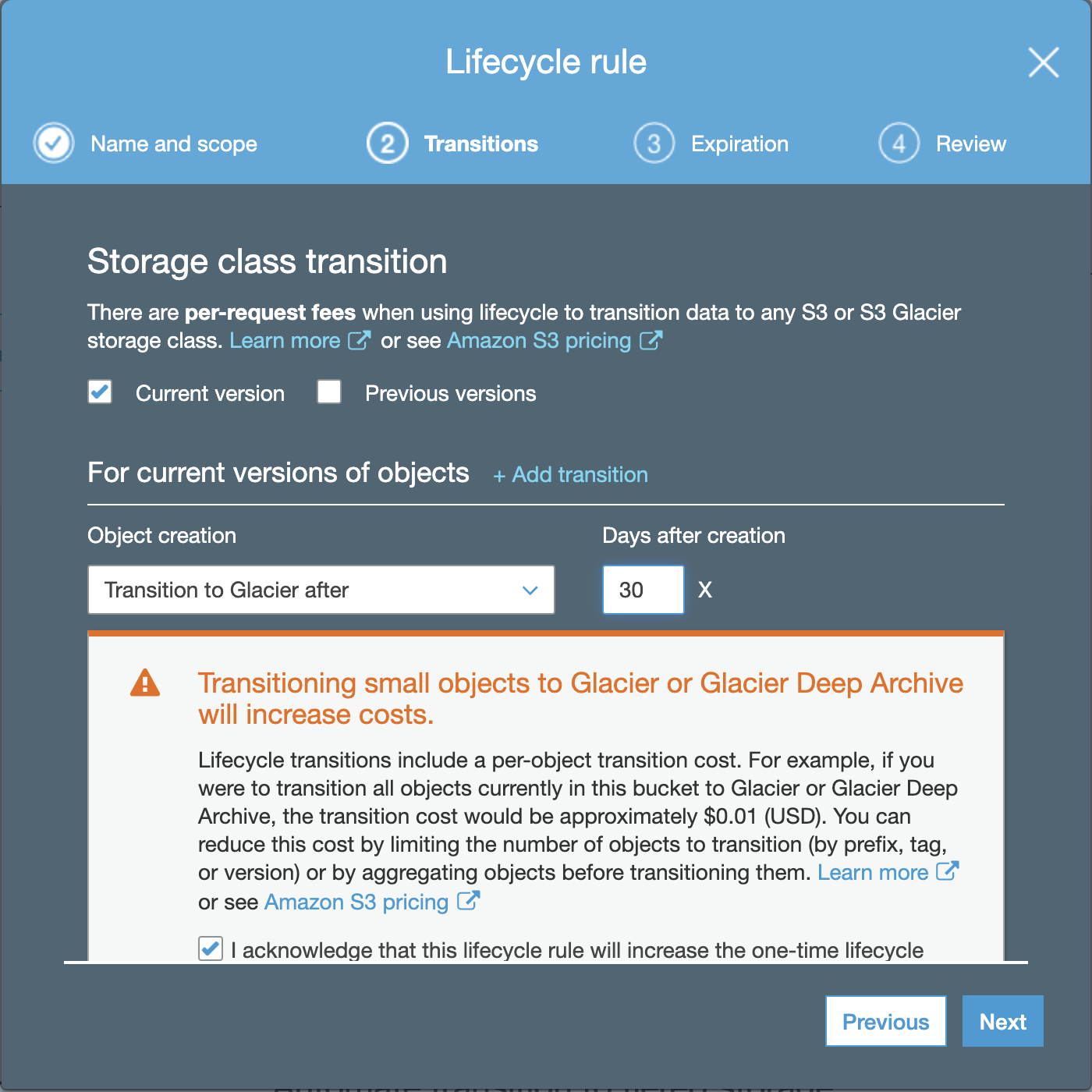
The configuration of expiration is used to expire and delete the object after N days of its creation.
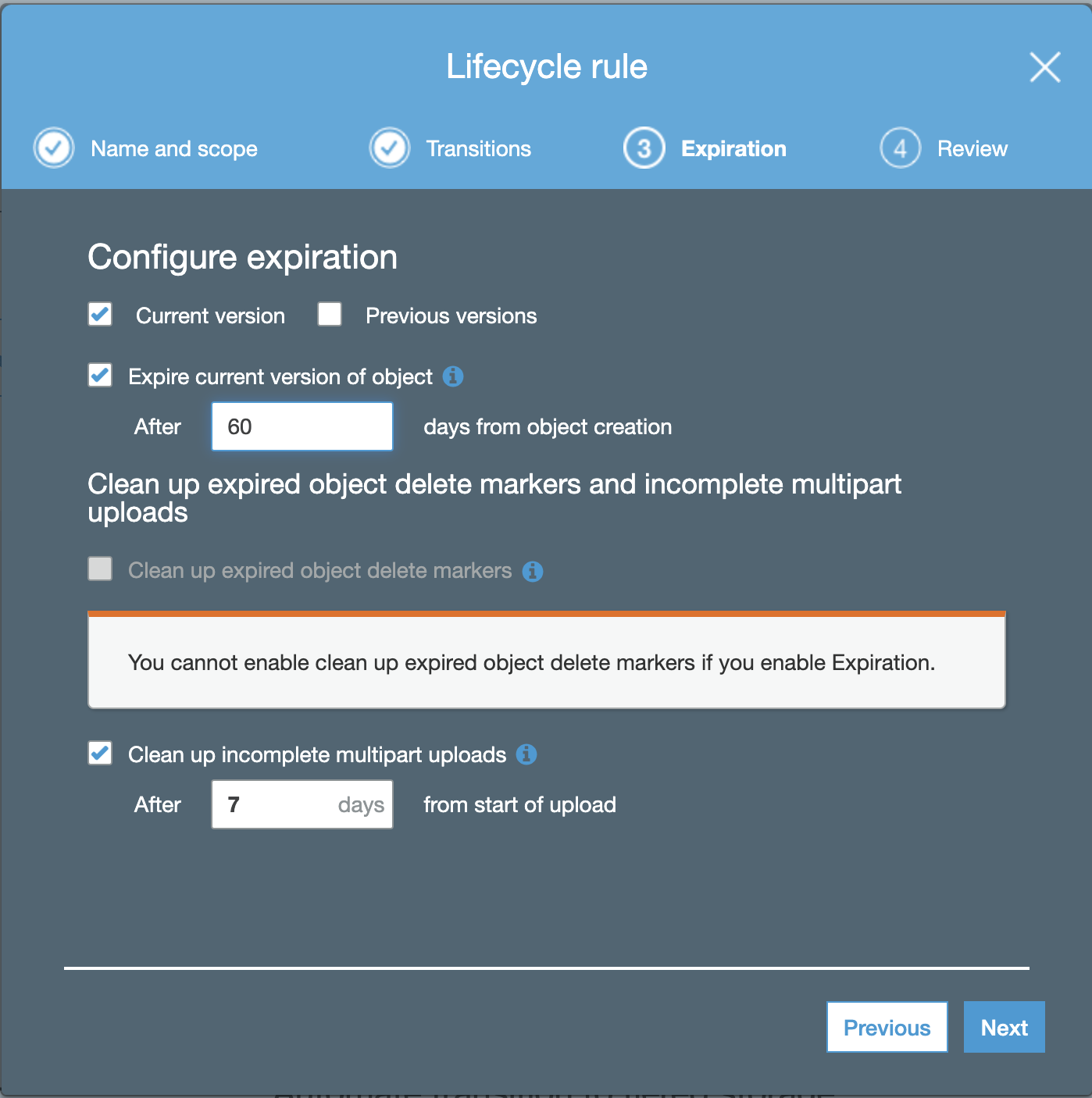
The last thing is to review your lifecycle rules, if it is already correct. After that you can save the Rules.
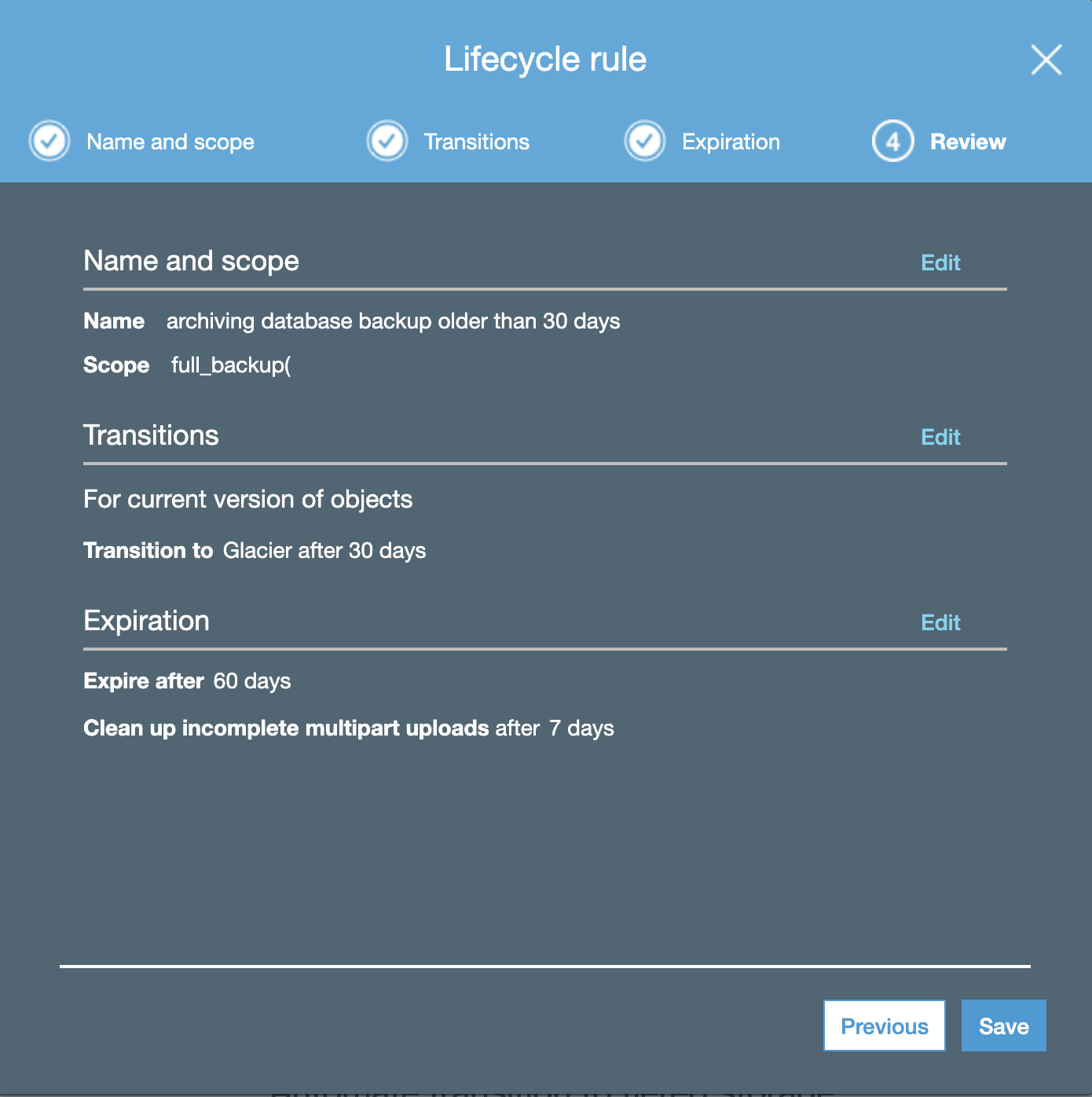
So now, you have Lifecycle Policy Rules for your AWS S3 bucket to Glacier.
Google Cloud Platform has “Object Lifecycle Management” to enable the Lifecycle rule. Go to the bucket,
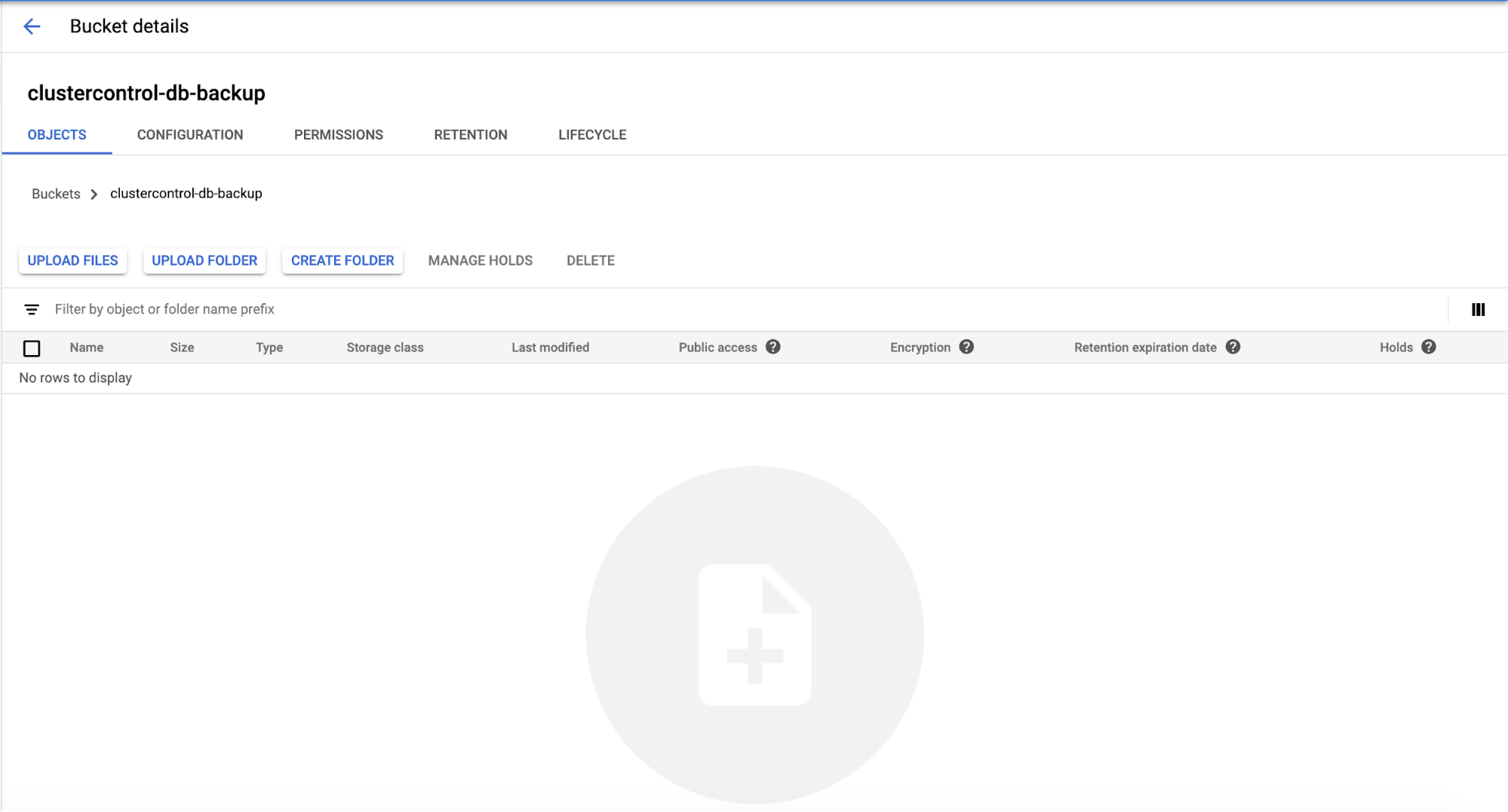
Choose the Lifecycle tab, then the lifecycle rules page will appear as shown below…
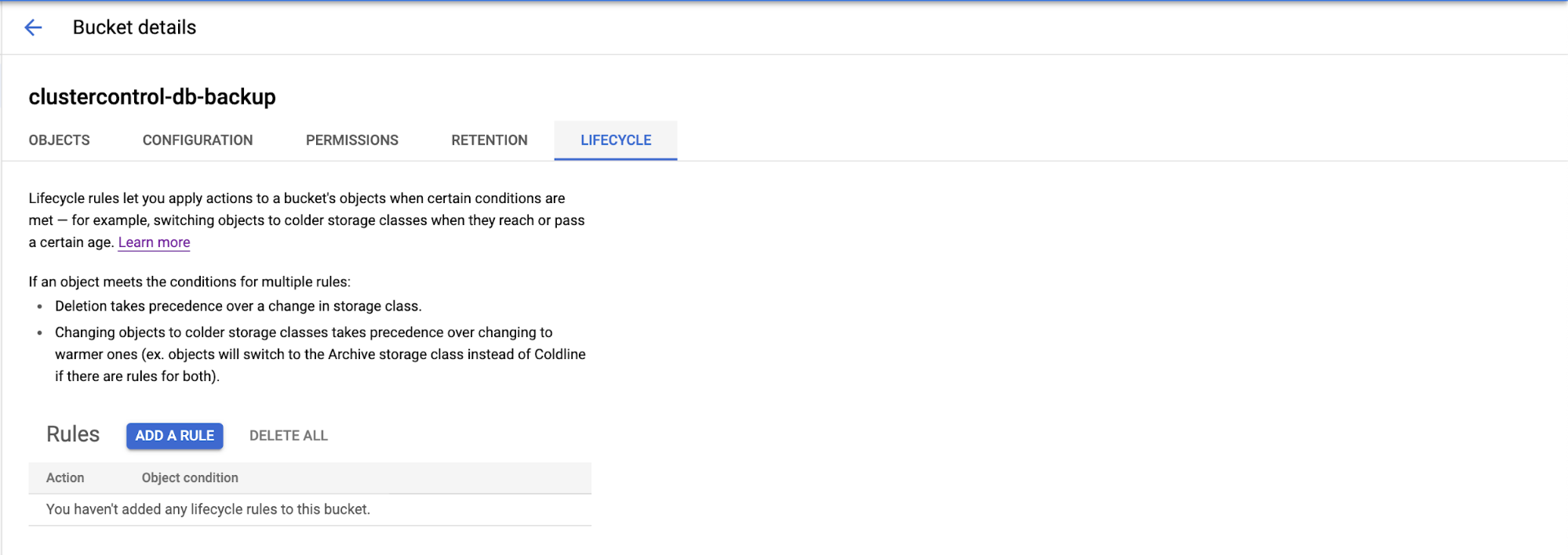
You can click the “Add A Rule” on the page and it will display the configuration page for the Action and Object Condition to be archived. There are four actions (as we already mentioned) are Nearline, Coldline, Archive, or Delete the object.
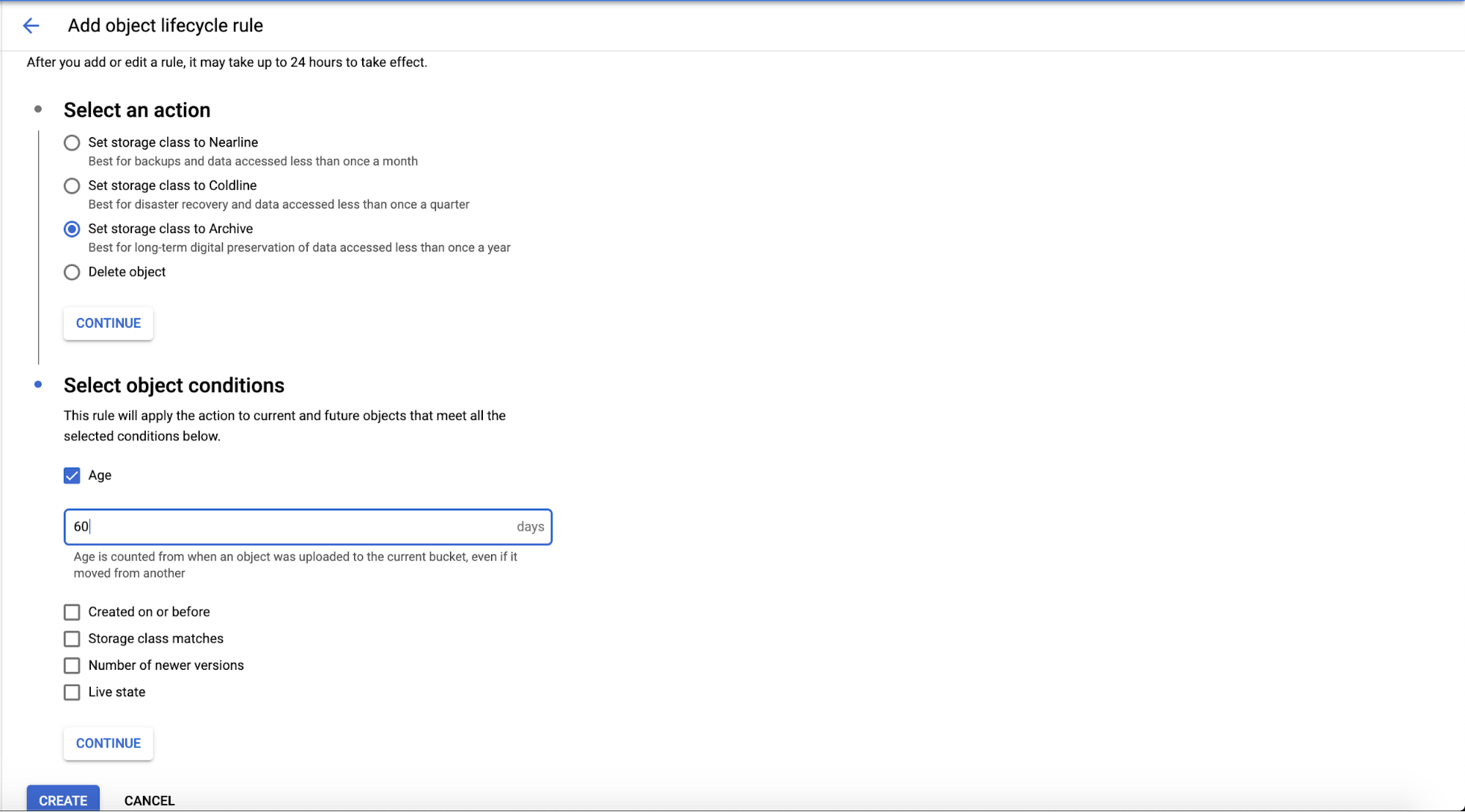
Choose the object conditions you want to configure based on your requirement to meet the selected conditions. You can choose based on Age, Created on or before, Storage class matches, Number of newer version, or Live state.
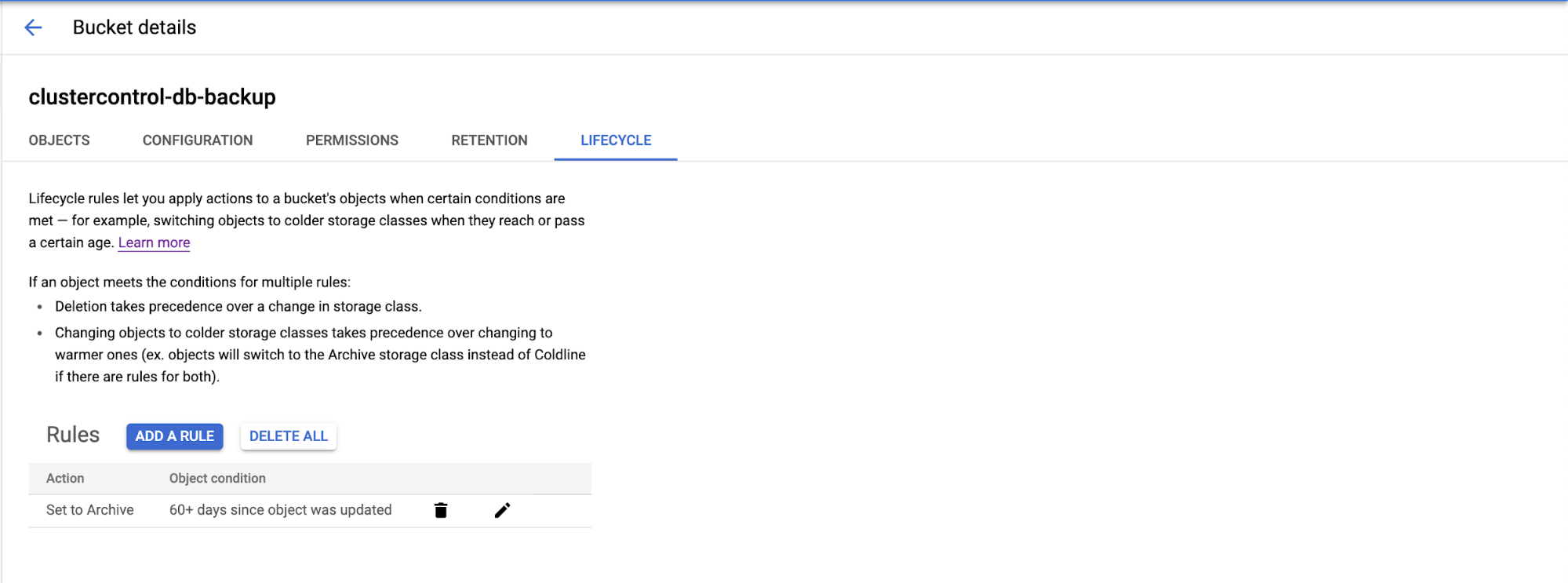
Then the new rule will be created in Lifecycle object management. This rule may take up for 24 hours to take effect.
Azure Cloud has features for managing Azure Blob Storage lifecycle. You can go through Storage Account, choose your bucket as shown below…
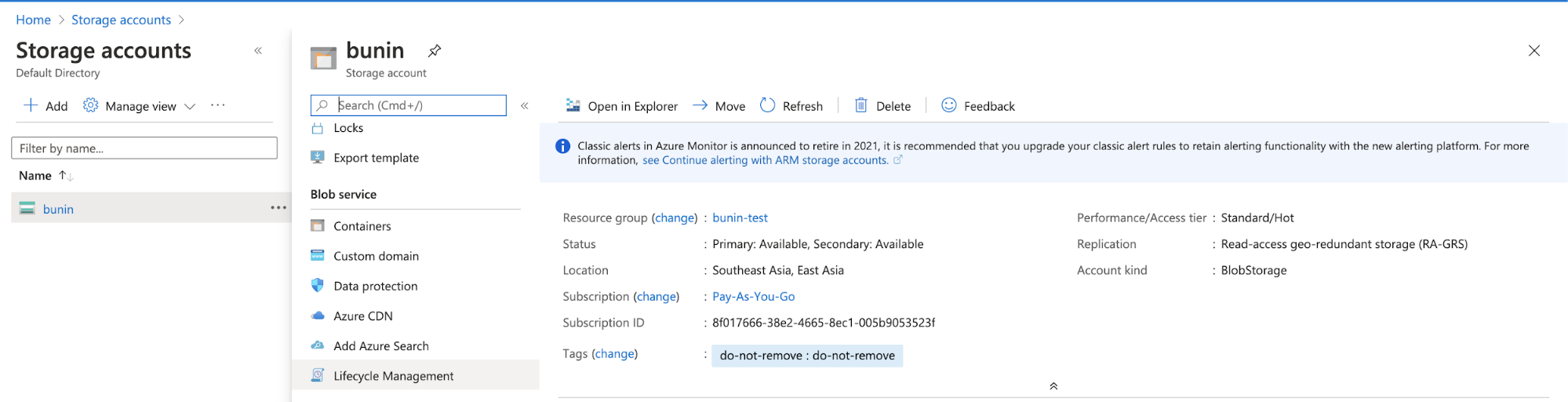
Then click Lifecycle Management, after that you will be prompted to a page for Lifecycle Management.
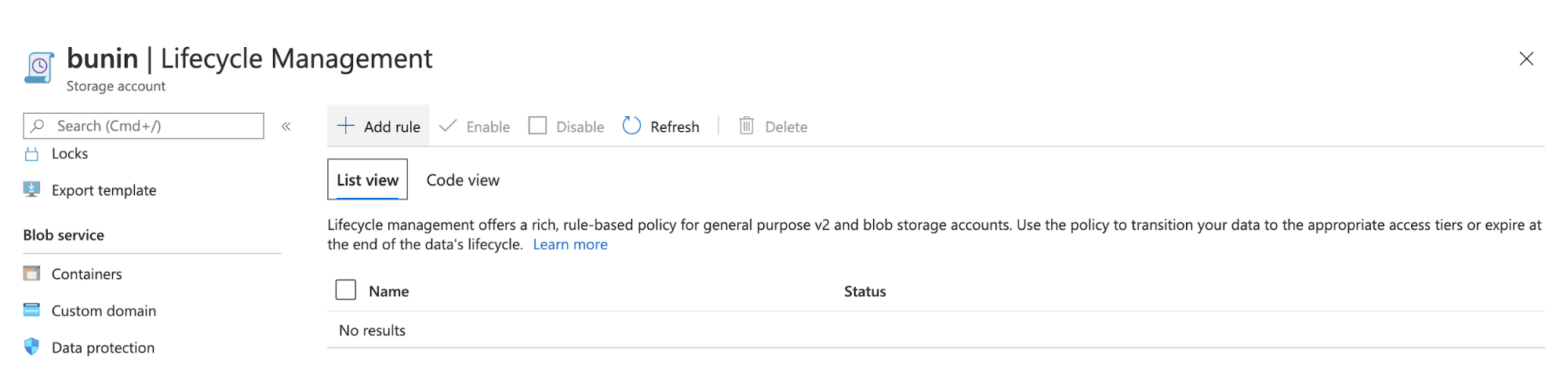
Add a new rule, to define your archiving rule in the Storage Account.
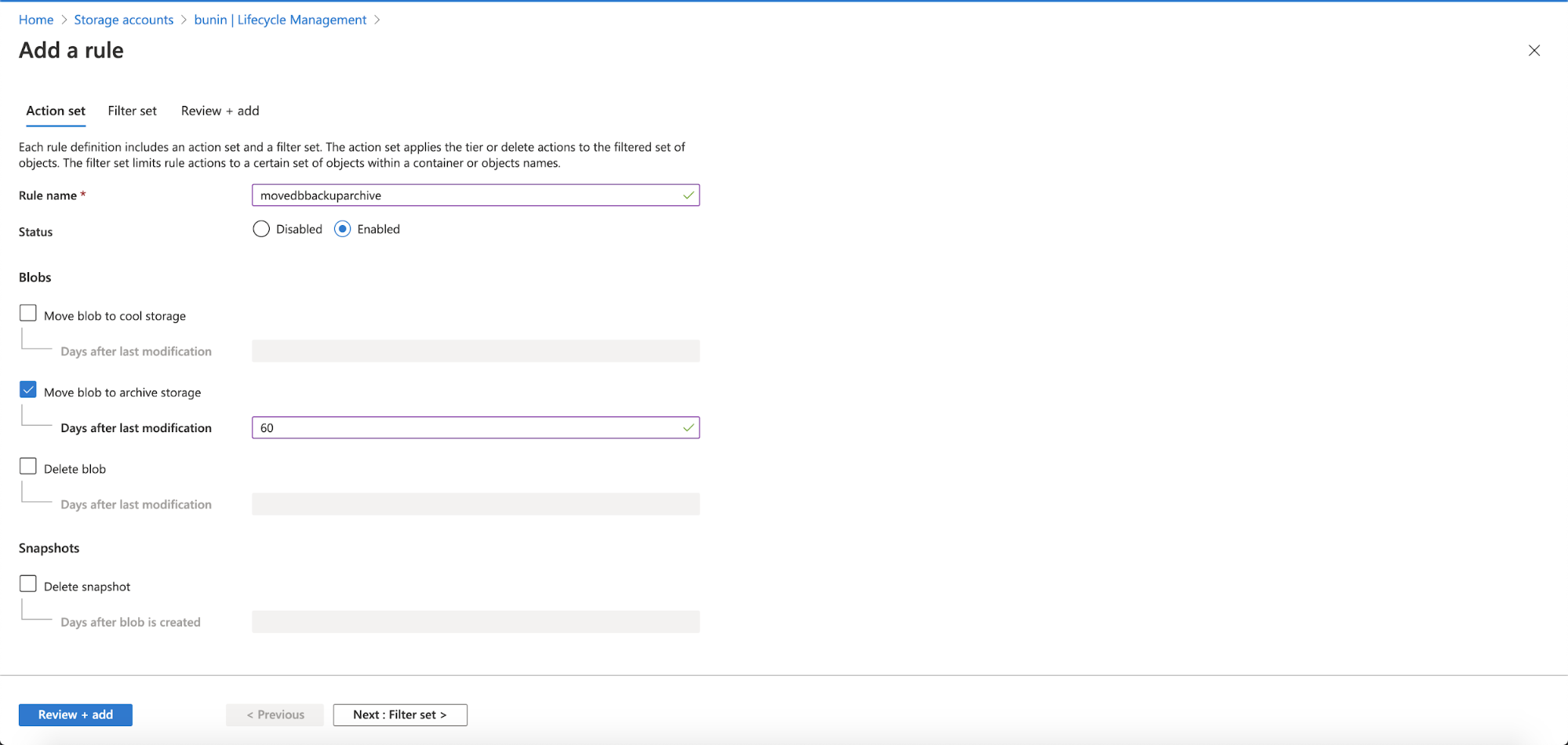
Fill in your rule name, must be letter and numeric. Enabled the status, and chose the action needed to take and fill the Days after last modification. There are 3 options; move the blob data to cool storage, move blob data to archive storage and delete the blob data. After that, click Next: Filter Set.
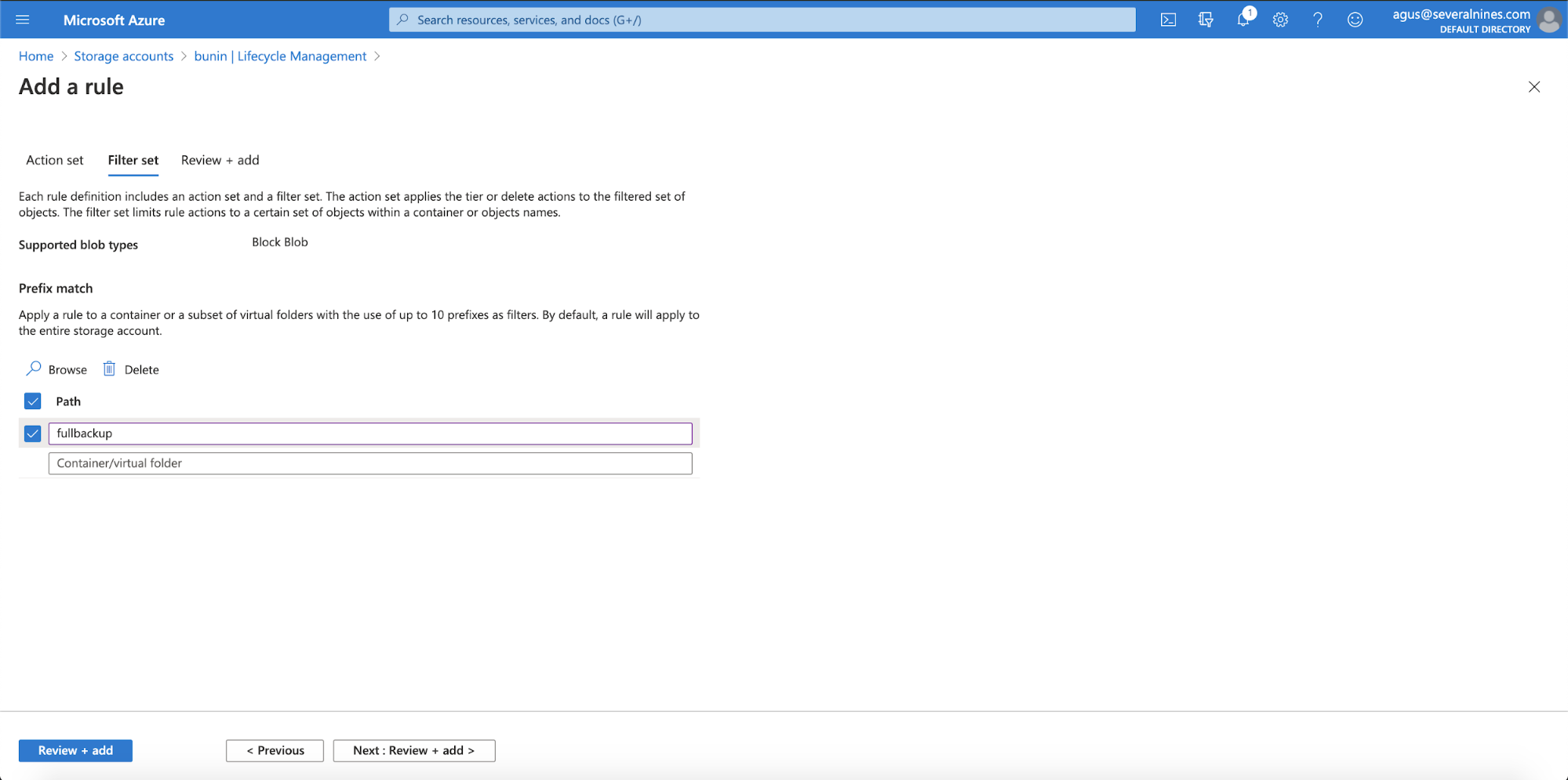
In the Filter Set, you can define the path for your virtual folder prefix. And then click Next: Review + Add
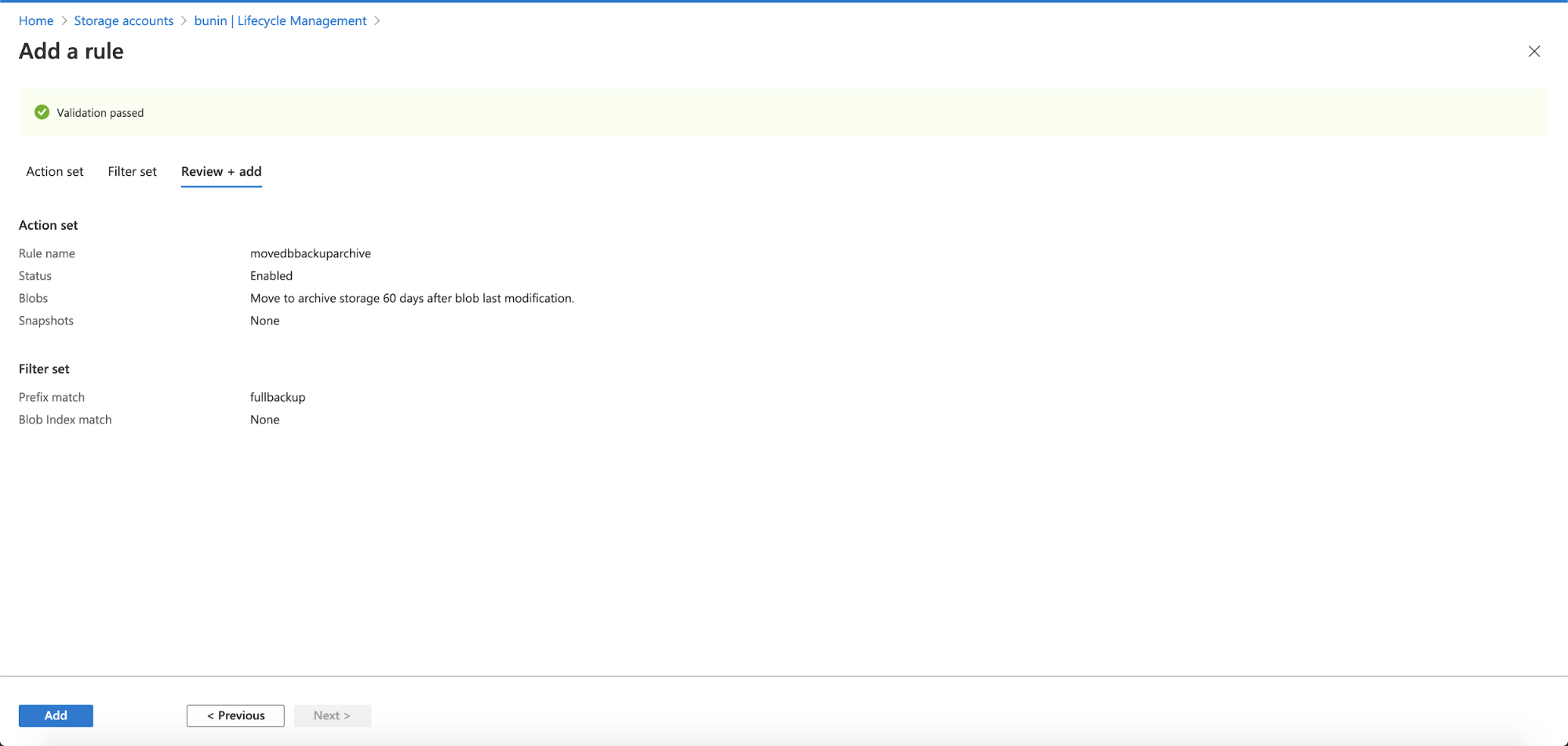
This page contains information that you had defined previously, the Action Set and Filter Set. You just need to click the Add button at the bottom and it will add a new rule in your Lifecycle Management.
The lifecycle management policy in your cloud will let you transition your database backup into a cooler storage tier, and delete your backup object storage at the end of the life cycle.
Conclusion
Combining retention policy and archiving rules in S3/object storage is essential for your backup strategies. It reduces your cloud storage costs, while allowing you to store your historical backups.



