blog
Controlling Replication Failover for MySQL and MariaDB With Pre- or Post-Failover Scripts

In a previous post, we discussed how you can take control of the failover process in ClusterControl by utilizing whitelists and blacklists. In this post, we are going to discuss a similar concept. But this time we will focus on integrations with external scripts and applications through numerous hooks made available by ClusterControl.
Infrastructure environments can be built in different ways, as oftentimes there are many options to choose from for a given piece of the puzzle. How do we define which database node to write to? Do you use virtual IP? Do you use some sort of service discovery? Maybe you go with DNS entries and change the A records when needed? What about the proxy layer? Do you rely on ‘read_only’ value for your proxies to decide on the writer, or maybe you make the required changes directly in the configuration of the proxy? How does your environment handle switchovers? Can you just go ahead and execute it, or maybe you have to take some preliminary actions beforehand? For instance, halting some other processes before you can actually do the switch?
It is not possible for a failover software to be preconfigured to cover all of the different setups that people can create. This is main reason to provide different ways of hooking into the failover process. This way you can customize it and make it possible to handle all of the subtleties of your setup. In this blog post, we will look into how ClusterControl’s failover process can be customized using different pre- and post-failover scripts. We will also discuss some examples of what can be accomplished with such customization.
Integrating ClusterControl
ClusterControl provides several hooks that can be used to plug in external scripts. Below you will find a list of those with some explanation.
- Replication_onfail_failover_script – this script executes as soon as it has been discovered that a failover is needed. If the script returns non-zero, it will force the failover to abort. If the script is defined but not found, the failover will be aborted. Four arguments are supplied to the script: arg1=’all servers’ arg2=’oldmaster’ arg3=’candidate’, arg4=’slaves of oldmaster’ and passed like this: ‘scripname arg1 arg2 arg3 arg4’. The script must be accessible on the controller and be executable.
- Replication_pre_failover_script – this script executes before the failover happens, but after a candidate has been elected and it is possible to continue the failover process. If the script returns non-zero it will force the failover to abort. If the script is defined but not found, the failover will be aborted. The script must be accessible on the controller and be executable.
- Replication_post_failover_script – this script executes after the failover happened. If the script returns non-zero, a Warning will be written in the job log. The script must be accessible on the controller and be executable.
- Replication_post_unsuccessful_failover_script – This script is executed after the failover attempt failed. If the script returns non-zero, a Warning will be written in the job log. The script must be accessible on the controller and be executable.
- Replication_failed_reslave_failover_script – this script is executed after that a new master has been promoted and if the reslaving of the slaves to the new master fails. If the script returns non-zero, a Warning will be written in the job log. The script must be accessible on the controller and be executable.
- Replication_pre_switchover_script – this script executes before the switchover happens. If the script returns non-zero, it will force the switchover to fail. If the script is defined but not found, the switchover will be aborted. The script must be accessible on the controller and be executable.
- Replication_post_switchover_script – this script executes after the switchover happened. If the script returns non-zero, a Warning will be written in the job log. The script must be accessible on the controller and be executable.
As you can see, the hooks cover most of the cases where you may want to take some actions – before and after a switchover, before and after a failover, when the reslave has failed or when the failover has failed. All of the scripts are invoked with four arguments (which may or may not be handled in the script, it is not required for the script to utilize all of them): all servers, hostname (or IP – as it is defined in ClusterControl) of the old master, hostname (or IP – as it is defined in ClusterControl) of the master candidate and the fourth one, all replicas of the old master. Those options should make it possible to handle the majority of the cases.
All of those hooks should be defined in a configuration file for a given cluster (/etc/cmon.d/cmon_X.cnf where X is the id of the cluster). An example may look like this:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shOf course, invoked scripts have to be executable, otherwise cmon won’t be able to execute them. Let’s now take a moment and go through the failover process in ClusterControl and see when the external scripts are executed.
Failover Process in ClusterControl
We defined all of the hooks that are available:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shAfter this, you have to restart the cmon process. Once it’s done, we are ready to test the failover. The original topology looks like this:
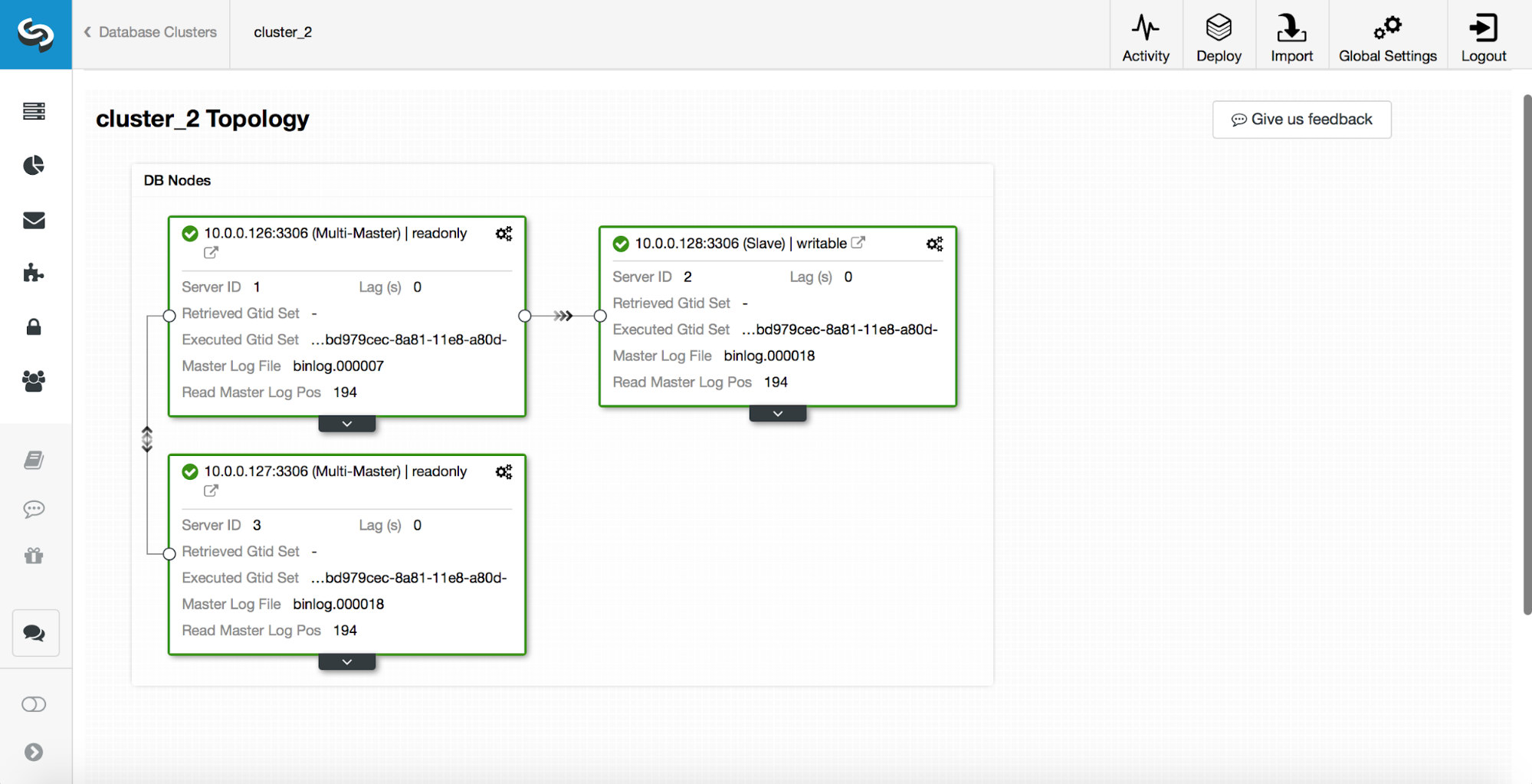
A master has been killed and the failover process started. Please note, the more recent log entries are at the top so you want to follow the failover from bottom to the top.
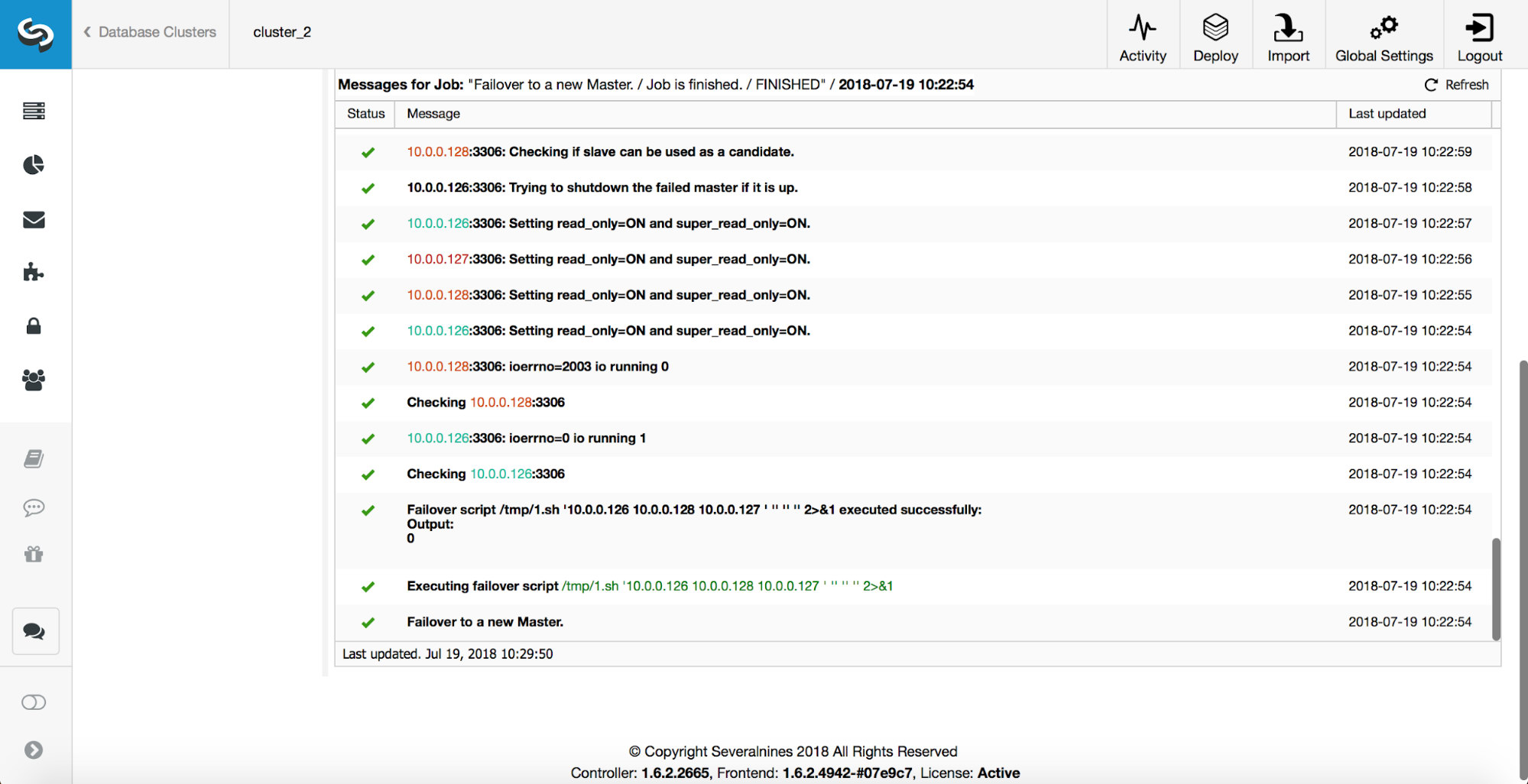
As you can see, immediately after the failover job started, it triggers the ‘replication_onfail_failover_script’ hook. Then, all reachable hosts are marked as read_only and ClusterControl attempts to prevent the old master from running.
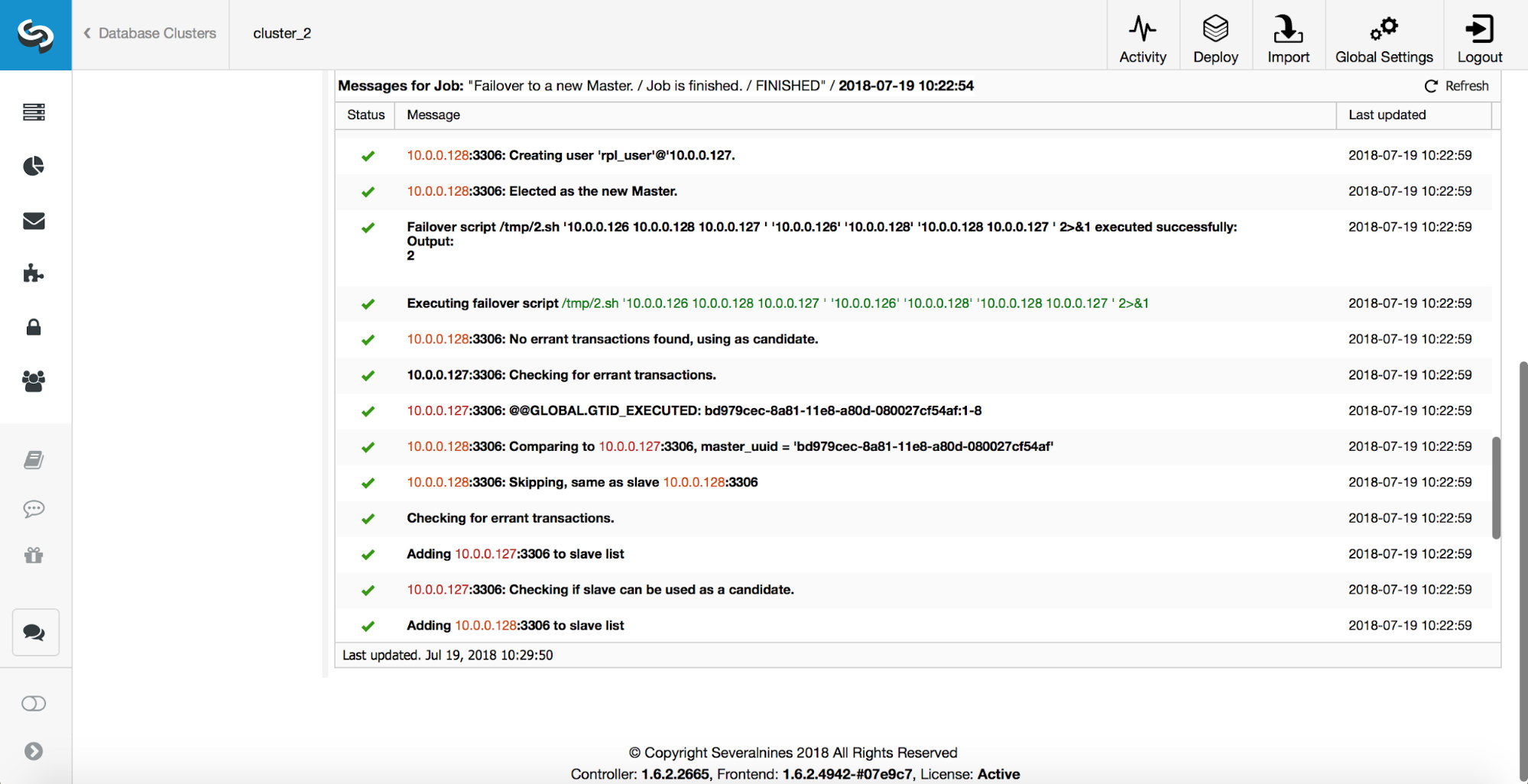
Next, the master candidate is picked, sanity checks are executed. Once it is confirmed the master candidate can be used as a new master, the ‘replication_pre_failover_script’ is executed.
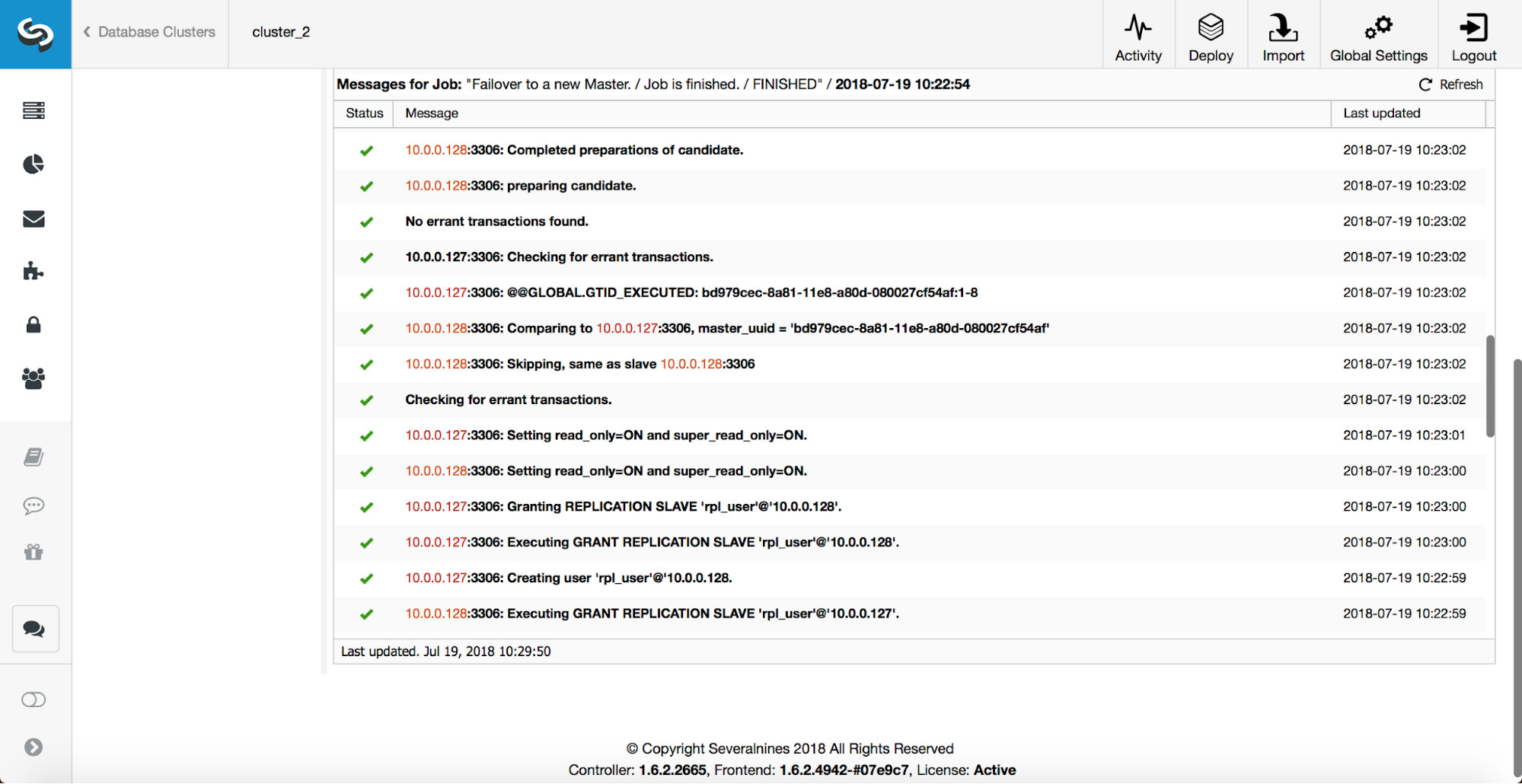
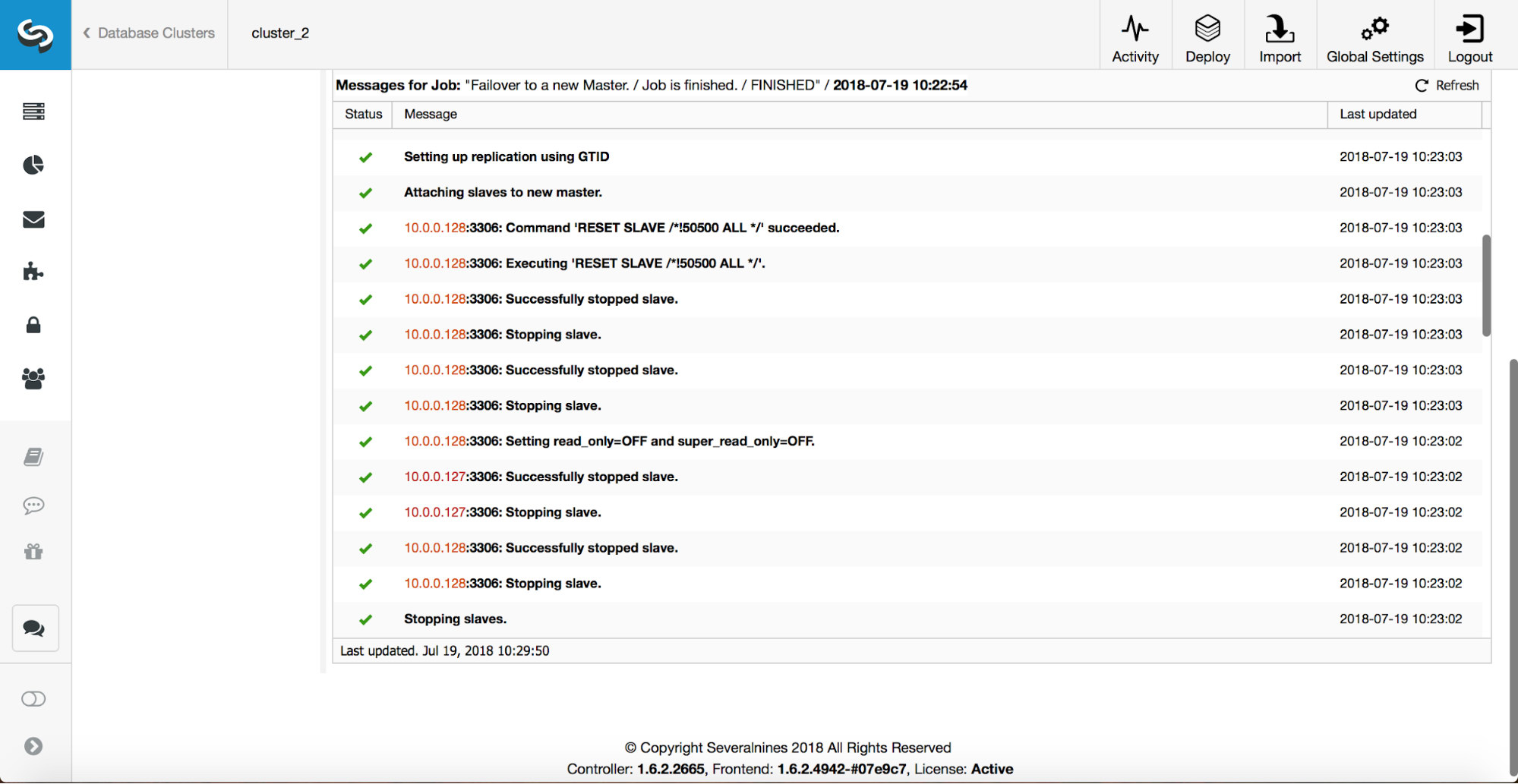
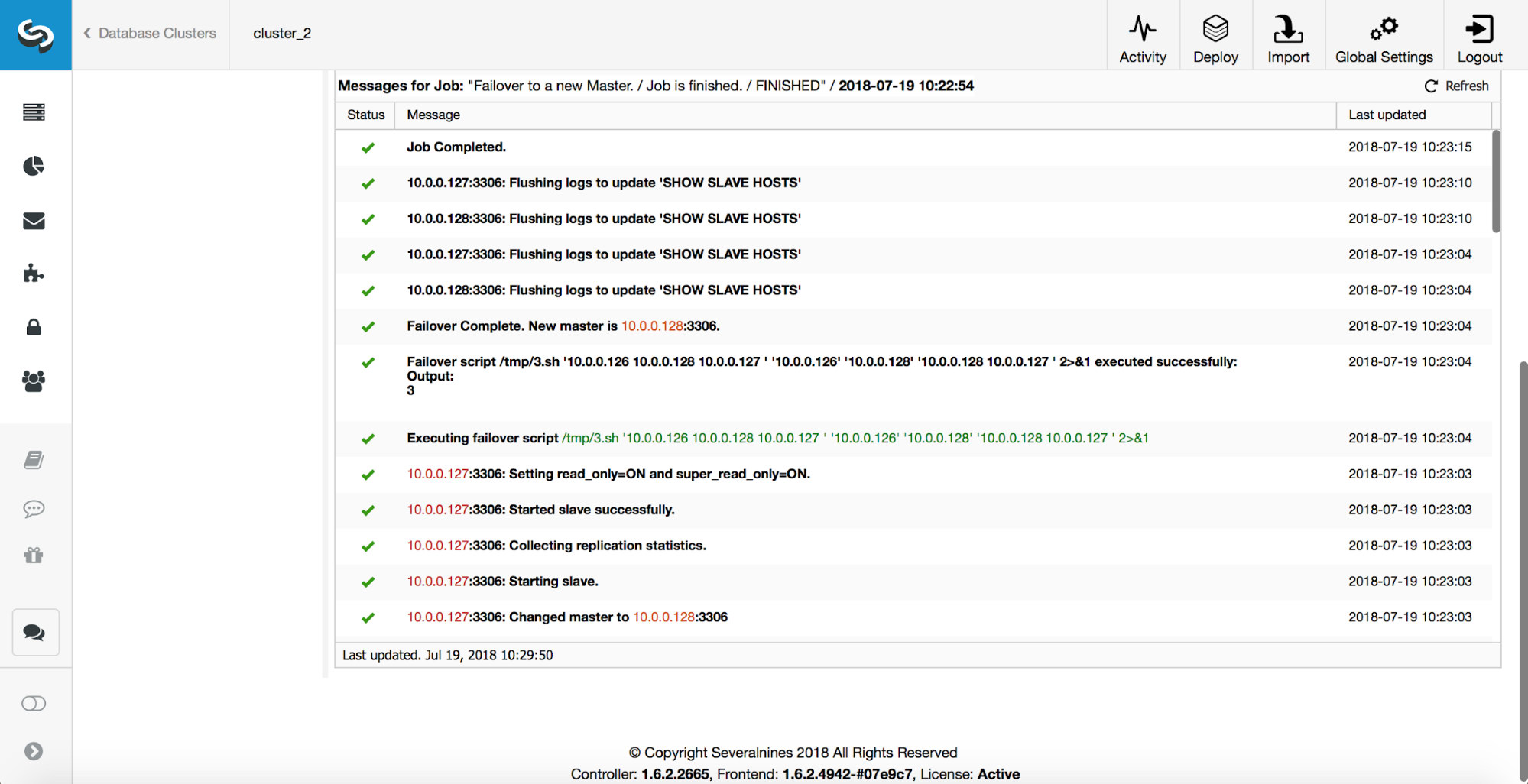
More checks are performed, replicas are stopped and slaved off the new master. Finally, after the failover completed, a final hook, ‘replication_post_failover_script’, is triggered.
When Hooks can be Useful?
In this section, we’ll go through a couple of examples cases where it might be a good idea to implement external scripts. We will not get into any details as those are too closely related to a particular environment. It will be more of a list of suggestions that might be useful to implement.
STONITH script
Shoot The Other Node In The Head (STONITH) is a process of making sure that the old master, which is dead, will stay dead (and yes.. we don’t like zombies roaming about in our infrastructure). The last thing you probably want is to have an unresponsive old master which then gets back online and, as a result, you end up with two writable masters. There are precautions you can take to make sure the old master will not be used even if shows up again, and it is safer for it to stay offline. Ways on how to ensure it will differ from environment to environment. Therefore, most likely, there will be no built-in support for STONITH in the failover tool. Depending on the environment, you may want to execute CLI command which will stop (and even remove) a VM on which the old master is running. If you have an on-prem setup, you may have more control over the hardware. It might be possible to utilize some sort of remote management (integrated Lights-out or some other remote access to the server). You may have also access to manageable power sockets and turn off the power in one of them to make sure server will never start again without human intervention.
Service Discovery
We already mentioned a bit about service discovery. There are numerous ways one can store information about a replication topology and detect which host is a master. Definitely, one of the more popular options is to use etc.d or Consul to store data about current topology. With it, an application or proxy can rely in this data to send the traffic to the correct node. ClusterControl (just like most of the tools which do support failover handling) does not have a direct integration with either etc.d or Consul. The task to update the topology data is on the user. She can use hooks like replication_post_failover_script or replication_post_switchover_script to invoke some of the scripts and do the required changes. Another pretty common solution is to use DNS to direct traffic to correct instances. If you will keep the Time-To-Live of a DNS record low, you should be able to define a domain, which will point to your master (i.e. writes.cluster1.example.com). This requires a change to the DNS records and, again, hooks like replication_post_failover_script or replication_post_switchover_script can be really helpful to make required modifications after a failover happened.
Proxy Reconfiguration
Each proxy server that is used has to send traffic to correct instances. Depending on the proxy itself, how a master detection is performed can be either (partially) hardcoded or can be up to the user to define whatever she likes. ClusterControl failover mechanism is designed in a way it integrates well with proxies that it deployed and configured. It still may happen that there are proxies in place, which were not installed by ClusterControl and they require some manual actions to take place while failover is being executed. Such proxies can also be integrated with the ClusterControl failover process through external scripts and hooks like replication_post_failover_script or replication_post_switchover_script.
Additional Logging
It may happen that you’d like to collect data of the failover process for debugging purposes. ClusterControl has extensive printouts to make sure it is possible to follow the process and figure out what happened and why. It still may happen that you would like to collect some additional, custom information. Basically all of the hooks can be utilized here – you can collect the initial state, before the failover, you can track the state of the environment at all stages of the failover.



