blog
Comparing SQL Server HA Solutions: Always On Availability Groups vs. Log Shipping

Information Technology is the cornerstone of all our businesses in the modern, technology-driven world we live in today. For databases that need to be continuously available to applications, it all comes down to Recovery Time Objective (RTO) and Recovery Point Objective (RPO). Before we go ahead, let’s revisit the terminology High Availability (HA) and Disaster Recovery (DR).
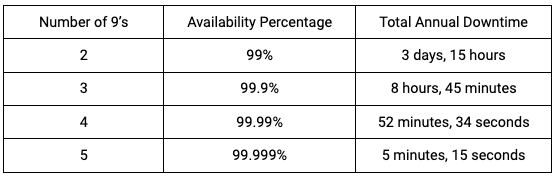
High availability refers to the least possible downtime in case of any server crash or failure. The number of 9’s defines the availability percentage.
Disaster Recovery refers to the process of recovering from a major failure of, for instance, a primary data center due to power failure, hardware issues, or catastrophic events, such as an earthquake, flood, or war.
Recovery Time Objective (RTO) is the outage duration or the time it takes to get the system back online. The database and application must minimize the RTO to get the database back to restore full service so that new transactions can occur.
Recovery Point Objective (RPO) refers to the time gap where data is lost, starting with the time of failure and going back to the most recent data that could be recovered. The actual data loss can vary upon the workload, type of failure, and high availability solution.
SQL Server provides you with different options for configuring high availability and disaster recovery solutions. For this blog, we will compare the following solutions:
-
Log shipping
-
Always On availability groups
SQL Server Log Shipping
SQL Server log shipping provides a high availability and disaster recovery solution, and it works on existing transaction log backups. The process involves a primary and one or more secondary database servers. The high-level steps of log shipping are as follows:
-
Backup: Take regular transaction log (t-log) backups from the primary server.
-
Copy: Copy the t-log backup file to secondary servers.
-
Restore: Restore the transaction log backups on secondary servers without recovering the database.
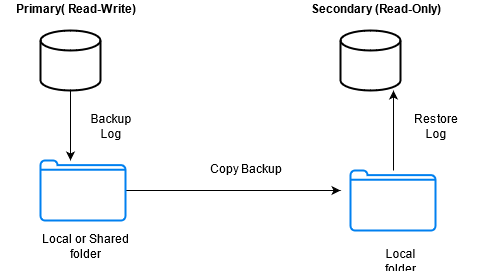
Log shipping implements backup, copy, and restore processes using the SQL Server agent jobs. The first job (backup) takes a t-log backup from the primary database, the second job (copy) copies that t-log backup to the secondary servers, and the third job (restore) restores these t-log backups to the secondary databases. The secondary database remains in restore or standby mode and waits for the next t-log backup from the primary server. It does not recover the secondary databases.
The Secondary database does not synchronize with the primary database in real-time. Instead, there is always a sync lag, and that lag depends on the transaction log backup intervals at the primary database, copy duration, and restoration time.
Consider the following log-shipping configurations for a SQL database:
-
T-log backup occurs every 30 minutes on the primary SQL instance and takes 5 minutes.
-
T-log backup copy from primary to a secondary instance takes around 10 minutes
-
The restore job starts every 45 minutes and takes approximately 5 minutes for restoration.
From the above, your secondary database always lags behind the primary database based on backup, copy, and restore frequency. Log shipping does not provide automatic failover capabilities. A DBA needs to bring the secondary database online to serve the applications if your primary database is unavailable.
Therefore, SQL Server Log Shipping is suitable for the comparatively less mission-critical database. It can be helpful for reporting purposes where you do not need the latest data on a secondary database.
The high-level advantages and disadvantages of log shipping are as below.
Advantages
-
Log shipping works on existing t-log backups.
-
Log shipping is supported on both SQL Server on Windows and Linux.
-
You can have multiple secondary databases.
-
Implementation is straightforward.
-
You can configure log shipping for multiple databases from a source instance.
-
You do not need to configure clustered instances.
Disadvantages
-
Manual failover
-
The secondary database always lags from the primary database.
-
After manual failover, the application needs to change the connection string to point to the secondary server.
-
If you read data from a secondary database, it won’t be available while the t-log backup restoration is in process.
SQL Server Always On Availability Groups
SQL Server Always On is a flexible, cost-efficient high availability, and disaster recovery solution available since SQL Server 2012. It provides availability at both instances and databases. It supports manual & automatic failover, redundancy within and across data centers, real-time data sync, and reading capabilities from secondary databases.
Let’s look at features of the SQL Server Always On Availability Group (AG):
-
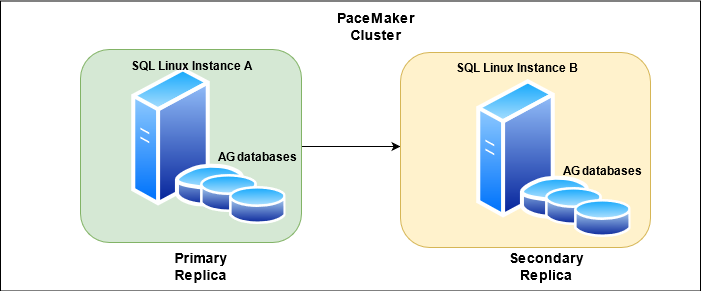
Infrastructure: Availability groups use failover clustering for server-level fault tolerance and intra-node network communication.
-
Windows Server: Windows Server Failover Clustering (WSFC)
-
Linux: Pacemaker
-
-
Safeguard from SQL Server instance failure: Always On uses multiple servers, and each server has its SQL instance and storage. Therefore, applications can connect to the secondary SQL instance after a failover if the primary SQL Server instance fails.
-
Database failures: An availability group is a set of user databases that must failover together.
-
Client connectivity: Always On uses a listener that refers to the primary AG instance. If a failover occurs (manual or automatic), the listener automatically points to the new primary replica. Therefore, you do not need to change the connection string to make it suitable for planned and unplanned failovers.
-
Flexible Failover Policy: SQL Server Always On uses robust failure detection using stored procedure sp_server_diagnostics to determine the failure severity that can affect SQL Server instances.
See a high-level diagram of Windows Server Failover clustering below:
SQL Server Always On supports the following modes:
-
Synchronous commit mode: SQL Server commits a transaction on the primary replica only after it receives acknowledgment that the secondary replica has committed the transaction. It is suitable for mission-critical databases that cannot afford data loss and require a fully synchronized secondary database.
-
Asynchronous commit mode: The asynchronous mode AG primary replica does not wait for an acknowledgment from the secondary database. It minimizes transaction latency on the primary replica. Therefore, it is suitable for databases that can afford some replication lag on the secondary replica. You can use asynchronous commit mode for reporting or disaster recovery purposes.
Always On supports the following failover modes:
-
Automatic failover (without data loss): For automatic failover, the primary and secondary replicas must be in synchronous-commit availability mode with automatic failover configuration.
-
Manual failover: Manual failover can be done in two ways:
-
Planned manual failover (without data loss): You can perform a manual failover in case of any activity such as OS patches on the primary replica. AG mode should be the synchronous commit for the planned manual failover without data loss.
-
Forced manual failover (allowing potential data loss): If the AG is in asynchronous mode, the availability group supports forced manual failover, which might have possible data loss.
-
The high-level advantages and disadvantages of the Always On Availability Group include:
Advantages
-
SQL Server Always On can be used for high availability and disaster recovery solutions.
-
It supports a fully synchronized copy of the primary database without any data loss.
-
You can offload the primary database by moving read-only requests to the secondary AG replica. This way, you can leverage the standby hardware infrastructure for purposes other than disaster recovery. However, note that this requires you to have an Enterprise Edition license of SQL Server.
-
Availability Groups support SQL Server listeners to avoid connection string modification after failure to the secondary replica. So SQL Server provides a single database endpoint to applications.
-
Availability groups support taking transaction log backups and copy-only backups from the secondary databases.
-
It supports automatic page repair from the secondary database that safeguards from storage subsystem errors that can corrupt a data page.
-
Availability groups support automatic and manual failovers.
Disadvantages
-
You cannot safeguard system databases (Master, Model, and MSDB) from instance or database level failure. Always On does not support adding them to the availability groups.
-
Always On does not synchronize SQL Server logins, linked servers, and Agent jobs to the secondary databases.
-
You cannot offload full backup to secondary databases as it supports only COPY_ONLY backup from the secondary database.
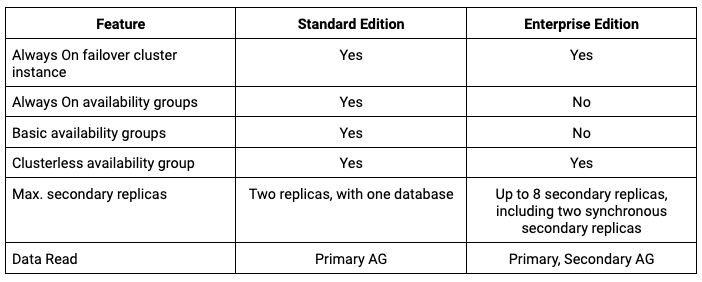
SQL Server Always On Licensing
Always On is a feature that is available on SQL Server Enterprise and Standard editions. The following table covers the difference between Always On for Standard and Enterprise editions.
Wrapping Up
Depending on your high availability and disaster recovery requirements, complexity, real-time, or delayed data sync of your databases, you can choose between log shipping or SQL Server Always On. This article presented an overview and comparison of both technologies to help you make a better decision for your particular use case.
If you’re looking for a quick and easy way to play with the technology, you can deploy SQL Server Always On for Linux from the ClusterControl GUI. For a comprehensive look at other HA options, check out this overview of high availability options for SQL Server on Linux.
For more updates and information on how to best manage your SQL Server databases, be sure to follow us on Twitter and LinkedIn and subscribe to our newsletter.



