blog
Comparing DevOps tooling approaches: Terraform, Ansible, Chef, Puppet, and DIY scripting

In today’s DevOps landscape, Infrastructure as Code (IaC) tools like Terraform, Ansible, Chef, and Puppet have become essential for automating infrastructure provisioning and configuration, streamlining deployment processes, improving consistency, and enhancing scalability, especially in heterogenous, large-scale environments.
While DIY (homegrown) scripts provide flexibility necessary to serve specific use cases effectively, they often lack standardization, modularity, and robust state management. Consequently, scaling, onboarding, collaboration, and error prevention challenges arise. Combining both demands strict version control and auditability to maintain reliability.
Despite the appeal of cost savings and agility, both approaches introduce risks—particularly when idempotency is not maintained or when internal documentation is lacking. These risks exponentiate with scale and operational complexity. In this blog, we’ll compare popular DevOps tools—Terraform, Ansible, Chef, Puppet—alongside DIY scripting approaches to evaluate their roles in infrastructure automation, maintenance, and lifecycle management.
IaC tool use case fundamentals
IaC tools are used to gain significant advantages in terms of speed, managing complex deployments and configurations, and—on a broader scale—provisioning infrastructure. From small to large organizations, their purpose is to provide management for complex mixes of technologies and especially help with upscaling and downscaling. These tools are not designed exclusively for database environments or deployments. Rather, they serve a broader purpose: to facilitate infrastructure-related provisioning and management.
Consider the technical advantages of the following: Terraform specializes in and excels at provisioning and orchestrating cloud infrastructure, particularly in multi-cloud or large-scale environments. In DevOps pipelines, it is best suited for the initial provisioning of infrastructure. Once the infrastructure is in place, you often still need to configure the operating system, services, and applications. This is where tools like Ansible, Chef, or Puppet come into play. These tools handle post-provisioning configuration and automation tasks.
Now that we have a general idea about these tools’ utility, let’s look at how to determine which tool to use and when and the feasibility of scripting or utilizing a mixed approach.
Review of common DevOps tooling
Terraform
For DevOps, Terraform is known for allowing teams to manage complex infrastructure safely, efficiently, and reliably across various platforms using code. It’s known to excel in the following;
- Managing cloud infrastructure declaratively (e.g., AWS, Azure, GCP)
- Handling immutable infrastructure changes
- Orchestrating dependencies across multiple services (e.g., spin up a VPC → subnet → EC2 → DNS)
Terraform is not commonly considered a configuration management tool, but ideal for initial provisioning of infrastructure in DevOps pipelines. Once the infrastructure’s ready, the next step shall be to configure the OS, services, applications. This is where Ansible, Chef, or Puppet come in — some pair Terraform with Ansible for post-provisioning tasks due to its simplicity and agentless model.
Ansible
Like Terraform, it’s an agentless type of automation engine, using SSH to connect to your Linux servers or nodes. Its configurations are written in YAML, making them simple to understand. Ansible excels when you need simple, fast, agentless configuration management and deployment. It complements Terraform for provisioning, and it provides a lower-complexity alternative to Chef and Puppet.
Ansible’s key advantages revolve around configuration management, application deployment, and task automation. Since it’s agentless, there is no need to install any software on target machines. It’s a push-based automation where it executes tasks by pushing instructions to the servers.
It handles idempotent state efficiently where re-running a playbook doesn’t cause adverse effects—it brings the system to its desired state. For database environments, Ansible is not just capable but it is one of the most practical tools, especially if you want reproducibility and automation with low overhead.
Chef
For a beginner who would like to jump into Chef, I can say it’s one of the bunch, requiring great knowledge of Ruby.
Chef excels on orchestrating complex, multi-node setups, e.g. provisioning your environment from a ready-made infrastructure and setting up your application → database environment → web server stacks → load balancers.
It has strong and repeatable configuration management. However, DevOps need to understand its architecture and how it works. From Chef Infra Server to its Chef Workstation, you need to be familiar with tools such as `knife` and `chef`. DevOps also need to understand the role of Chef Infra Client; as these build up the underlying components and architecture — understanding the interaction between these components, authentication, and data flow (like search and data bags) adds further complexity.
Its extensibility enables long-term consistency enforcement and compliance, e.g. integration with CI/CD, auditing, and policy enforcement. Regardless of the added complexity that Chef poses, the great thing that I like about it is its strength in complex, ongoing configurations, while tools like Terraform are better at bootstrapping infrastructure.
Best use cases for Chef are the following;
- Managing complex and heterogeneous environments (e.g., hybrid cloud)
- Enforcing consistent configuration across a large number of servers
- Automating application deployments and middleware setup
- Infrastructure that benefits from long-term drift correction
Chef is particularly applicable in enterprise settings, where configuration drift, compliance, and scalability are critical concerns.
Puppet
Puppet is very efficient especially in ensuring that systems remain in the desired state by automatically correcting configuration drift. Its DSL is based on Ruby, and it’s fair to say that both Puppet and Chef share the same fundamental goals and concepts. Puppet and Chef both have conventions for modularity and data separation, but the specific tools (Cookbooks vs. Modules, Attributes/Data Bags vs. Hiera/Facts) and best practices differ.
As with Chef, Puppet works on a client-server model, where the Puppet master sends configurations to Puppet agents on managed nodes. Puppet specializes in powerful, declarative systems for ongoing system configuration at scale.
Puppet is a great complementary tool for other IaC automation engines or tools; together, they guarantee efficiency and productivity especially in production scale heterogeneous systems that require strict compliance and auditability (e.g., banking, healthcare). Despite its powerful automation capabilities, it’s still limited when handling databases.
For example, you’ll still end up integrating external tools and custom scripts with Puppet for performing operations such as migrations and complex full-stack setup and deployment of database clusters. There can be community modules available but they’ll require testing or some modification in order to satisfy specific requirements.
DIY Scripts
In the good old days, Perl, Awk, Tcl, Expect, and a combination of Bash or Zsh were pretty common for DIY scripts. However, they’re now considered legacy and are less popular, especially as they’re not supported by IaC. Scripting using the old technologies is strongly discouraged as it possesses many disadvantages especially if you have complex infrastructure that requires scaling or setting up a full stack infrastructure, together with preferred database clusters.
Nowadays, DevOps commonly use programming languages such as Python, Ruby, and Go to build scripts, as well as other general-purpose languages for specific tasks. Having DIY or homegrown scripts provide some advantages;
- Custom Flexibility
- You can tailor the script precisely to your infrastructure’s needs
- Great for one-off, non-repetitive tasks or unique infrastructure configurations
- Minimal Learning Curve (Initial Phase)
- For small teams or solo developers, it’s quicker to write a script than learn an IaC tool
- No need to adopt a new DSL (domain-specific language) or workflow
- Low Overhead
- No external dependencies or runtimes
- Run with existing OS utilities (e.g., ssh, scp, cron, bash)
- Rapid Prototyping
- Great for experimenting with new setups, performing quick patches, or proof-of-concept implementations
Although this approach seems appealing, homegrown scripts entail considerable disadvantages;
- A higher susceptibility for errors as complexity increases
- Greater difficulty in performing rollbacks or managing version control
- Minimal inherent integration with DevOps tooling like GitOps or CI/CD, or cloud APIs, necessitating explicit custom programming
- Maintenance efforts become more demanding as the team scales or requirements are modified
A prospective, multi-tool DevOps workflow
As you have probably surmised, it is unlikely that you would use one tool or method to implement a DevOps pipeline. Instead, you’d likely use a number of tools and scripts to build a comprehensive, bespoke pipeline like below:
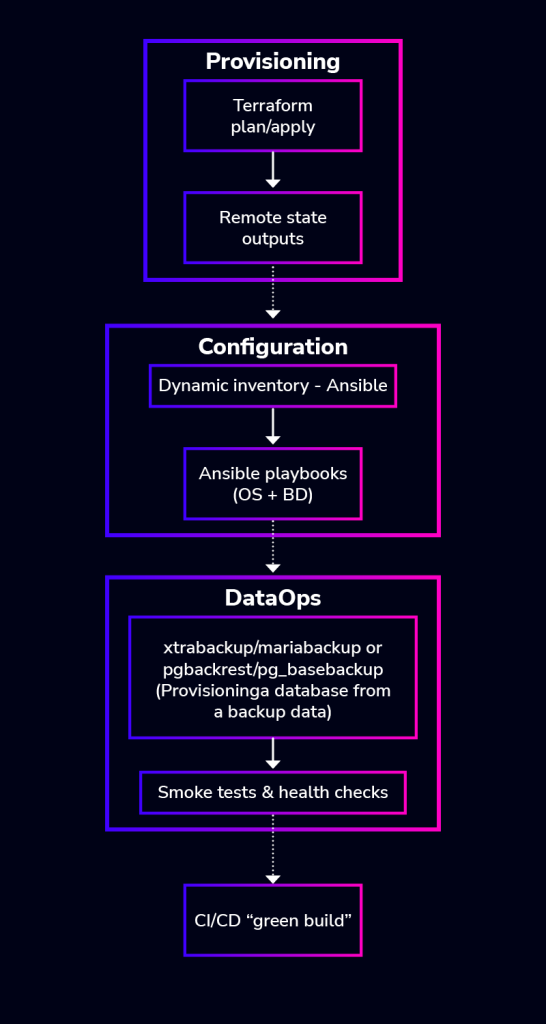
- Terraform Plan & Apply:
- Terraform reads your infrastructure-as-code definitions.
- It creates a plan outlining the resources to be created, modified, or destroyed.
- Upon approval, Terraform applies the plan, provisioning the necessary infrastructure (e.g., virtual machines, networks, storage).
- Ansible Playbook Execution:
- Once the infrastructure is provisioned, Ansible connects to the newly created machines.
- Ansible executes playbooks containing tasks to configure the operating systems (e.g., installing packages, configuring services, managing users).
- Data operations executing DIY or custom scripts:
- Restoring backup data to provision a node using tools such as mariabackup/xtrabackup or pgBackRest and pg_basebackup
- Creating databases and users.
- Applying schema changes.
- Loading initial data.
- Running database-specific configuration.
- Restoring backup data to provision a node using tools such as mariabackup/xtrabackup or pgBackRest and pg_basebackup
- Environment Ready: If all steps are successful, your environment is fully provisioned and configured.
- Terraform Error / Ansible Error / DB Script Error: If any step fails, the workflow branches to an error state specific to the tool that encountered the issue.
- Troubleshooting & Fix: In case of an error, you would troubleshoot the problem, make necessary fixes to your Terraform configuration, Ansible playbooks, or custom script.
- Loop Back to Terraform: After fixing the issue, the workflow typically restarts from the Terraform step to ensure the entire environment is in the desired state.
- Green build: Successful execution would have a green state. The workflow concludes once the environment is successfully set up.
IaC tools are incomplete when it comes to database lifecycle ops
The infrastructure vs. database lifecycle
IaC tools don’t provide native support for deploying and configuring load balancers, replication setup, backup management and verification, and monitoring with management for these tools are not supported. You still have to innovate and invent using its own native language depending on what automation engine you are using.
Terraform
Terraform doesn’t have native modules for configuring HAProxy or ProxySQL for instance. It can be used to provision and manage the infrastructure where these proxies will be deployed. You’ll need to define your HAProxy or ProxySQL configuration in separate files, and then Terraform can be used to deploy these files to the appropriate servers. These actions need to be coordinated, e.g. provisioning the infrastructure, configuring the HAProxy or ProxySQL, starting HAProxy or ProxySQL. It would be challenging as well with the MaxScale load balancer especially if you are working with MariaDB clusters (MariaDB Server or Galera Cluster for async / synchronous replication respectively).
Terraform itself does have advantages over manually setting up infrastructure as it does have key considerations such as plugins like Kubernetes Provider to manage HAProxy or ProxySQL, state management, automation, and collaboration; as the latter in Terraform enables collaboration among teams by providing a shared configuration language. However, as stated, you still need to create the resources with configuration or make sure to have the available providers or Kubernetes containers for your load balancers which still poses downsides.
Ansible and Chef
The playbook will always have this “execute this recipe / playbook” and, the state logic, ordering, and safety checks have to be written and maintained. You will still need some extra help from other tools to achieve your desired database environment and cluster, e.g. extra cookbooks / roles / playbooks just to bootstrap DB clusters, manage virtual IPs, or wire up Keepalived/ProxySQL, MaxScale, pgpool, or setup monitoring and backup management.
Homegrown scripts
DIY scripts don’t account for hidden complexity. For instance, when setting up a replication and adding a replica, every addition means that it has a topology change. This leads to hand-editing the code and hoping nothing breaks. Speaking of high-availability, reliable failover is a multi-step dance (detect, fence, promote, redirect traffic, alert). Shell scripts rarely cover all steps atomically, so race conditions and split-brain risks are inevitable.
When it comes to disaster recovery, you need your backup run by your script but it can be ineffective or non-functional if it hasn’t been verified. Backup verification covers the whole backup functionality and this is always part of your daily job and should be covered by DIY scripts. DIY jobs often stop at “backup finished,” skipping integrity checks, restore tests, or off-site encryption, so you don’t really know if you can recover, unless verified.
Another significant drawback that I’ll argue is highly inescapable is the practice of “tribal-knowledge”. Extra-features are always welcome as part of your development scheme for your infrastructure and database systems, these cover chores such as adding or improving dashboards, alerting, secrets management, CI/CD tests, and audit logs.
This lands on your team’s plate and often produces so-called “quick scripts” from one engineer that soon morph into a brittle system only a few people truly understand. A newcomer might find it difficult to comprehend these, ultimately leading to wasted effort and restarting the work from the ground up.
Integrated platforms help solve these pain points with declarative topology, automated consensus-based failover, continuous backup/restore testing, unified metrics, and role-based audit logs. But, the bottom line remains, home-grown tooling looks cheap, but the hidden engineering time and operational risk usually eclipse the cost; and on this topic, we’re speaking of a purpose-built replication/HA/backup solution that is really time-consuming and can become troublesome and complicated as the infrastructure grows.
Database ops require purpose-built platforms like ClusterControl
As I have demonstrated, attempting to morph your IaC tooling into an end-to-end solution by hammering components together and weaving in homegrown scripts is a suboptimal solution, even when only accounting for seemingly straightforward database ops. Starting from deployment, using ClusterControl would make the job easier, quicker and more reliable, leveraging GUI or even `s9s CLI` tooling. Let’s look at a standard high availability PXC 8.4 topology:
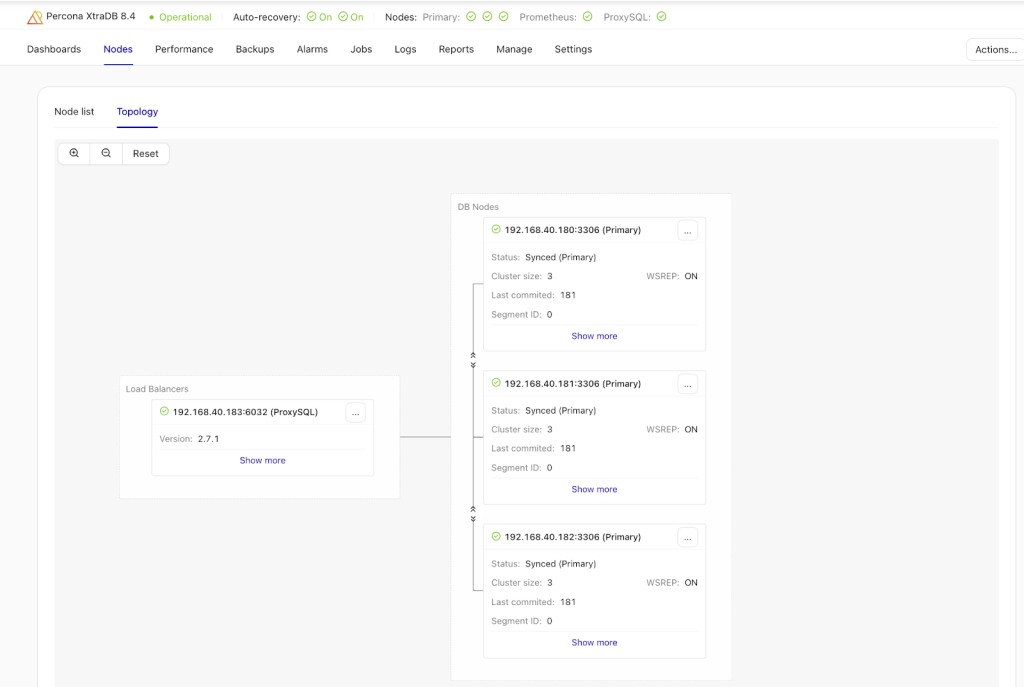
Deploying this with ClusterControl can be done in 5 core and 3 auxiliary steps. Let’s go through these steps:
- Click Deploy a cluster button. This is found in the upper right corner
- Choose Create a database cluster and then hit the Continue button. On this step, choose a database technology, configure and create an open source database service within a few minutes.
- Select a Database, Vendor, and Version of the database cluster you would want to deploy. In our example, choose Percona XtraDB Cluster and choose version 8.4 then hit the button Continue
- Set the Cluster Details. You set here the name of the cluster or assign some tags
- Set the SSH Configuration. You set the SSH configuration and credentials in order to access your target db nodes.
- Set the Node configuration. Set your database configuration such as username and password
- Set the Add nodes. Add the IP/hostname or FQDN (Fully Qualified Domain Name) of the node.
- Checkout and review the settings you set in the Preview and hit the Finish button.
Once these steps are completed and fulfilled, you will be able to enjoy monitoring, creating backups, or setting up alerts so you will be notified what is the current state of your database health and what are the things that you might need to do in case you get noise due to unstable conditions.
Integrating ClusterControl with your DevOps tooling and into infrastructure workflow
ClusterControl comes with s9s CLI tools and REST API if you also need to achieve some advanced actions that are not currently found in the s9s CLI tools. Here are some examples of integration for your CI/CD pipelines that you can leverage using our s9s CLI tools.
Integrating ClusterControl with Terraform
Terraform can call any binary with the local-exec provisioner, so you can keep all infra in HCL yet let s9s do the heavy DB lifting. Example script integration:
## main.tf
terraform {
required_version = ">= 1.1"
}
variable "galera_nodes" { type = list(string) }
variable "db_root_pwd" { type = string }
variable "cluster_name" { type = string }
# Optional: if you also want the official CC provider, leave it in.
provider "clustercontrol" {
cc_api_url = "https://127.0.0.1:9501/v2"
cc_api_user = "admin"
cc_api_user_password = var.db_root_pwd
}
resource "null_resource" "galera_with_s9s" {
provisioner "local-exec" {
command = <<EOT
s9s cluster --create \
--cluster-type=galera \
--nodes="${join(",", var.galera_nodes)}" \
--vendor=percona \
--provider-version=5.7 \
--db-admin-passwd='${var.db_root_pwd}' \
--cluster-name='${var.cluster_name}' \
--wait --log
EOT
}
}
You can execute this by running the following example command,
terraform init
terraform apply -var='galera_nodes=["10.0.0.11","10.0.0.12","10.0.0.13"]' \
-var='db_root_pwd=R00tP@55' \
-var='cluster_name=PXC57'Severalnines also offers a pure Terraform approach that uses Terraform Provider for ClusterControl. Check it out here in our github page.
Integrating ClusterControl with Ansible
Severalnines also offers s9s-ansible that allows you to use Ansible to take actions for the ClusterControl using a mix of s9s CLI tools and RPC API. Below is an example of deploying a Galera cluster:
- name: Create Cluster | Deploy Percona/MariaDB Galera Cluster
hosts: "{{ environ }}"
connection: local
gather_facts: false
vars_files:
- ../inventory/group_vars/{{ environ }}/{{ environ }}_common
- ../inventory/group_vars/{{ environ }}/deploy/{{ deploy_id|d('') }}
tasks:
- set_fact:
deploy_type_title: "{% if vendor=='percona' %}Percona{% else %}MariaDB{% endif %}"
- name: Check if {{ deploy_type_title }} Galera cluster exists
command:
cmd: s9s cluster --list --long
register: cluster_list
- name: Find clusters of a correct type
set_fact:
lines: "{{ lines|default([]) + [item] }}"
when: item|trim is search(cluster_type)
with_items:
- "{{ cluster_list.stdout_lines }}"
- name: Find if cluster with a proper name exists
set_fact:
cluster_exists: 1
when: lines is defined and item|trim is search(cluster_name)
with_items:
- "{{ lines }}"
- name: Verify if mysql cluster db nodes should fail as cluster name exist already
ansible.builtin.debug:
msg: "The cluster name you have set already exist"
when: cluster_exists is defined
any_errors_fatal: true
- name: Separate the hosts via comma delimiter to allow multiple host deployments
set_fact:
fixed_nodes: "{{fixed_nodes | default('')}}{{ prefix }}{{ item.host }}:{{ item.port }}?{{ item.node_type }};"
loop: "{{ db_nodes }}"
- debug: >-
msg='s9s cluster --create --cluster-type={{ cluster_type }} --nodes="{{ fixed_nodes }}"
--db-admin={{ db_admin_user }} --db-admin-passwd={{ db_admin_password }}
--vendor={{ vendor }} --cluster-name={{ cluster_name }}
--provider-version={{ version }} --os-user={{ os_user }} --os-key-file={{ os_key_file }}
{{ wait_log|d('') }} --with-tags={{ cluster_tags }}'
when: cluster_exists is undefined
- name: Execute s9s CLI to create a cluster
command: >-
s9s cluster --create --cluster-type={{ cluster_type }} --nodes="{{ fixed_nodes }}"
--db-admin={{ db_admin_user }} --db-admin-passwd={{ db_admin_password }}
--vendor={{ vendor }} --cluster-name={{ cluster_name }}
--provider-version={{ version }} --os-user={{ os_user }} --os-key-file={{ os_key_file }}
{{ wait_log|d('') }} --with-tags={{ cluster_tags }}
when: cluster_exists is undefinedYou can run this with
$ ansible-playbook playbooks/deploy-galera-cluster.yml -e "environ=staging deploy_id=percona_galera_pp1" -vAs shown in the script, it invokes s9s cluster which then integrates and delegates the job to create a cluster using s9s CLI tools.
Integrating ClusterControl with Chef and Puppet
ClusterControl has S9s_cookbooks for Chef and Puppet for ClusterControl. While it is not made to allow you to manage actions instead of ClusterControl, executing with Chef or Puppet and integrating s9s CLI tools can be simple. For Chef, you can for example execute by using the resource bash.
bash "install-galera-nodes" do
user "root"
code <<-EOH
#{s9s_bin} cluster --create --cluster-type=galera \
--nodes="192.168.70.70,192.168.70.80,192.168.70.100" \
--vendor=percona \
--provider-version=5.7 \
--db-admin-passwd='#{db_pass}' \
--os-user=vagrant \
--cluster-name='#{galera_cluster_name}' \
--wait --log
EOH
not_if "#{s9s_bin} cluster --list --cluster-name '#{galera_cluster_name}' --cluster-format='%I'"
end
exec { "create_ccrpc_set_firstname":
path => ['/usr/sbin','/sbin', '/bin', '/usr/bin', '/usr/local/bin'],
user => "root",
command => "sudo S9S_USER_CONFIG=${user_path} s9s user --set --first-name=RPC --last-name=API",
# require => [File["${home_path}/.s9s/"],Service['cmon']]
require => Exec["create_ccrpc_user"]
}and for Puppet,
exec { 'create_galera_cluster':
command => "${s9s_bin} cluster --create \
--cluster-type=galera \
--nodes='${join($galera_nodes, ",")}' \
--vendor=percona \
--provider-version=5.7 \
--db-admin-passwd='${db_root_pwd}' \
--cluster-name='${cluster_name}' \
--wait --log",
# idempotency guard – run only if the cluster does **not** exist
unless => "${s9s_bin} cluster --list \
--cluster-name '${cluster_name}' \
--cluster-format '%I' | grep -q '.'",
path => [ '/usr/bin', '/usr/local/bin' ],
timeout => 0, # let --wait run as long as needed
require => Class['clustercontrol'],
}
Wrapping up
Integrating CI/CD pipelines, incorporating such tools like Terraform, Ansible, Chef, and Puppet, significantly enhances operational efficiency and organizational agility. This integration enables true push-button deployments across even the most complex database and infrastructure landscapes. Managing intricate, multi-environment setups manually introduces considerable overhead and cost.
From that aspect, relying solely on DIY and homegrown scripts will become unsustainable. The inherent complexity and time investment required for teams to adapt to increasing demands, especially in hybrid environments, necessitates a robust and automated solution like ClusterControl integrated with CI/CD.
A well-architected CI/CD workflow streamlines complexity, reduces operational overhead, and empowers your team to meet accelerating delivery demands with confidence. ClusterControl provides an end-to-end platform for deploying and managing database clusters as well as load balancers.
Environments that span multiple cloud or on-prem providers, or that depend on deeply customized architectures to meet rigorous security and compliance mandates, still require complementary tooling and integration work. Integrating ClusterControl with CI/CD pipelines becomes essential to manage the broader infrastructure landscape, automate provisioning, and consistently enforce configurations across heterogeneous environments.
But don’t take our word for it, test ClusterControl free for 30 days as part of your DevOps workflow. In the meantime, follow us on LinkedIn or X to stay up-to-date with the latest tips, tricks, and news in the database ops space, or register for our monthly newsletter.