blog
ClusterControl – Advanced Backup Management – mariabackup Part III

So far in the previous two parts of this short blog series we have discussed several options that may impact the time and size of the backup. We have discussed different compression options and a setting related to throttling the network transfer should you stream the data from the node to the controller host. This time we would like to highlight something else – ability to take partial backups using MariaBackup. First, let’s talk what are the partial backups and what are the challenges related to them.
Partial backups
MariaBackup is a backup tool that creates physical backups. What it means is that it will copy the data stored in files on the database node to the target location. It will create a consistent backup of the database, something that allows you to restore your data to a precise point of time – the time when the backup completed. All data in all tables and schemas will be consistent. This is quite important to keep in mind. Consistent backups can be used to provision replicas, running Point-in-Time Restore and so on.
Partial backups on the other hand are, well, partial. Only a subset of the tables is backed up. Obviously, this makes the backup inconsistent. It cannot be used to create a replica or to restore the data to the same point of time. Partial backups still have their own use. They can be used to restore a subset of the data – instead of restoring whole backup you can restore just a single table and then extract the data you need. Sure, you can do the same with logical backups but those are quite slow and not really suitable for any kind of larger deployments.
The downside is that partial backup is not consistent in time. This should be quite obvious as we are collecting just a subset of the data. Another challenge is restore – you cannot restore partial backups directly on the production systems easily. First, because it is not straightforward, second, because it is not consistent. The safest way to restore partial backup would be to restore it on a separate node and then use mysqldump or SELECT INTO OUTFILE to extract required data.
Let’s take a look at the options that ClusterControl provides us with regarding the partial backups.
Partial backups in ClusterControl
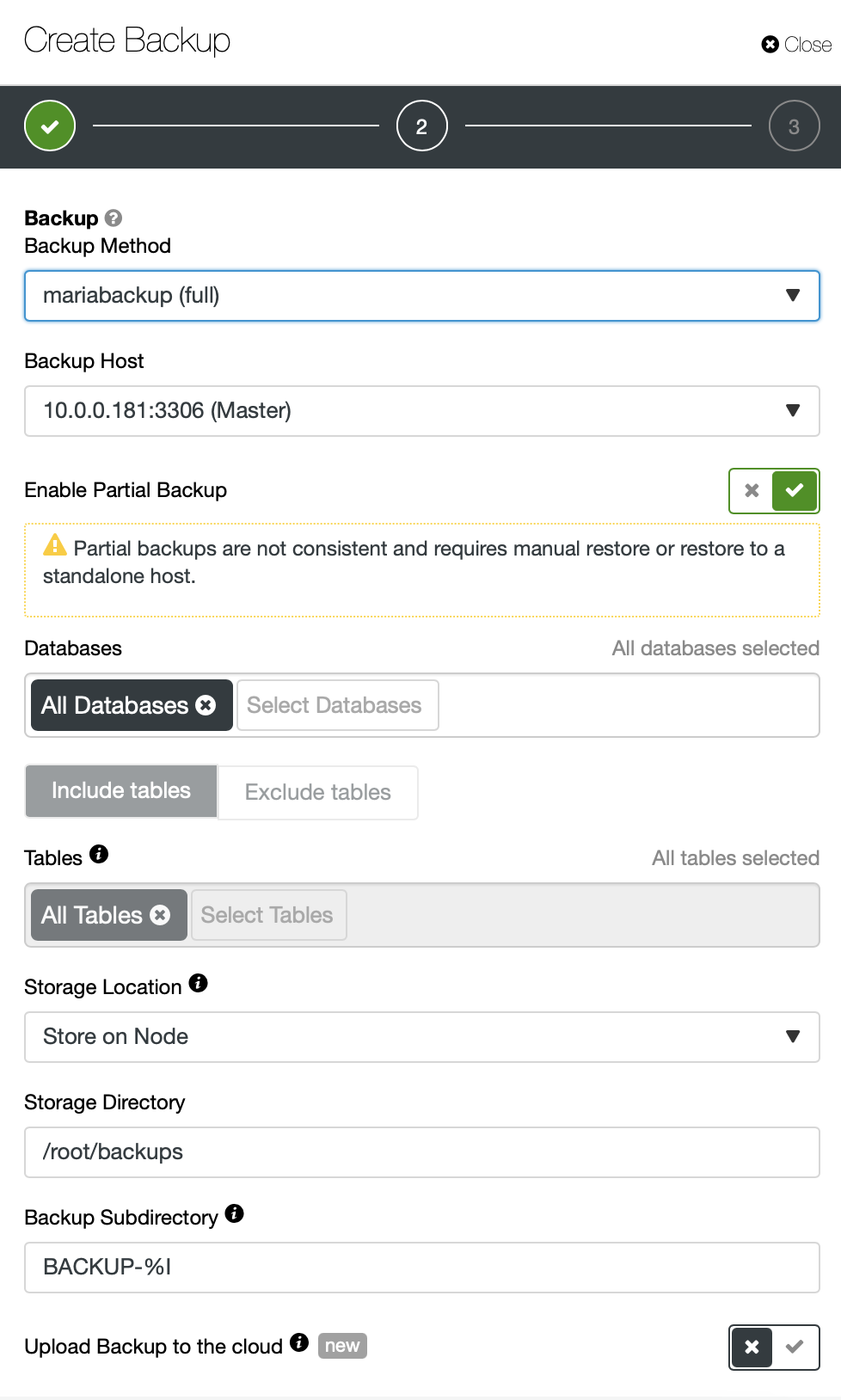
First of all, partial backups are not used by default, you have to explicitly enable them. Then a set of options shows up which allows us to pick what we want to backup. We can pick a particular schema or a set of tables. We can take a backup of all tables except some or we can just tell that we want to take a backup of tables A, B and C.
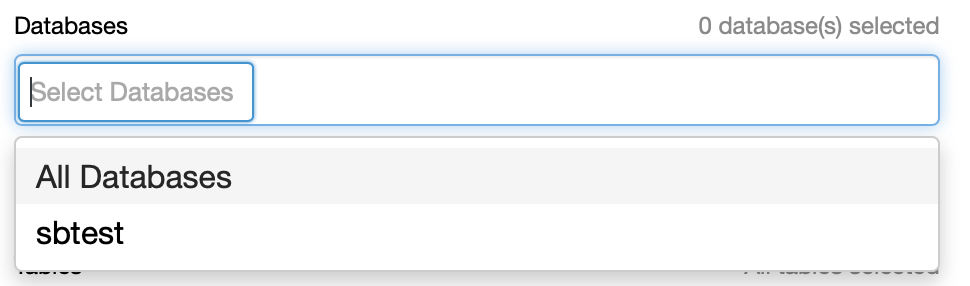
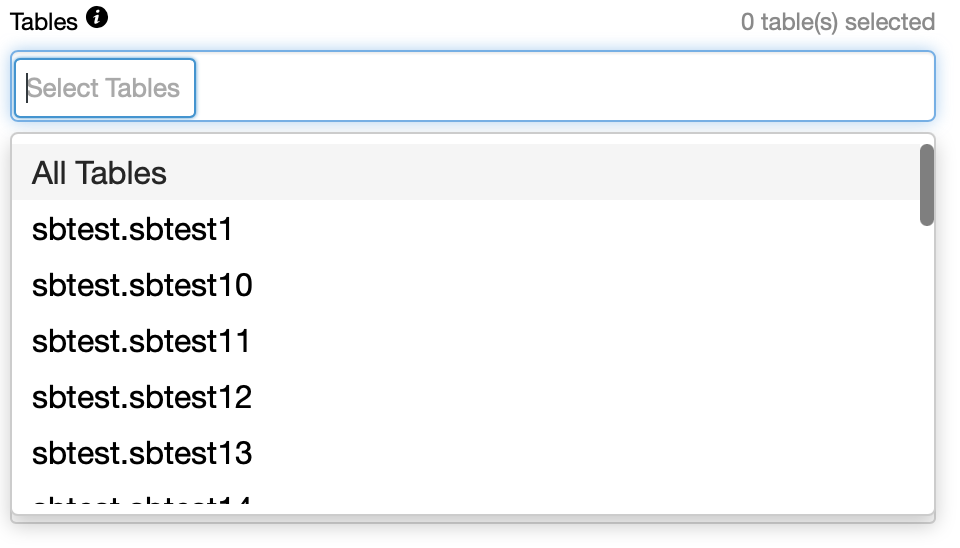
Of course, when you go to the drop-down, you’ll see all databases and all tables listed to pick from.
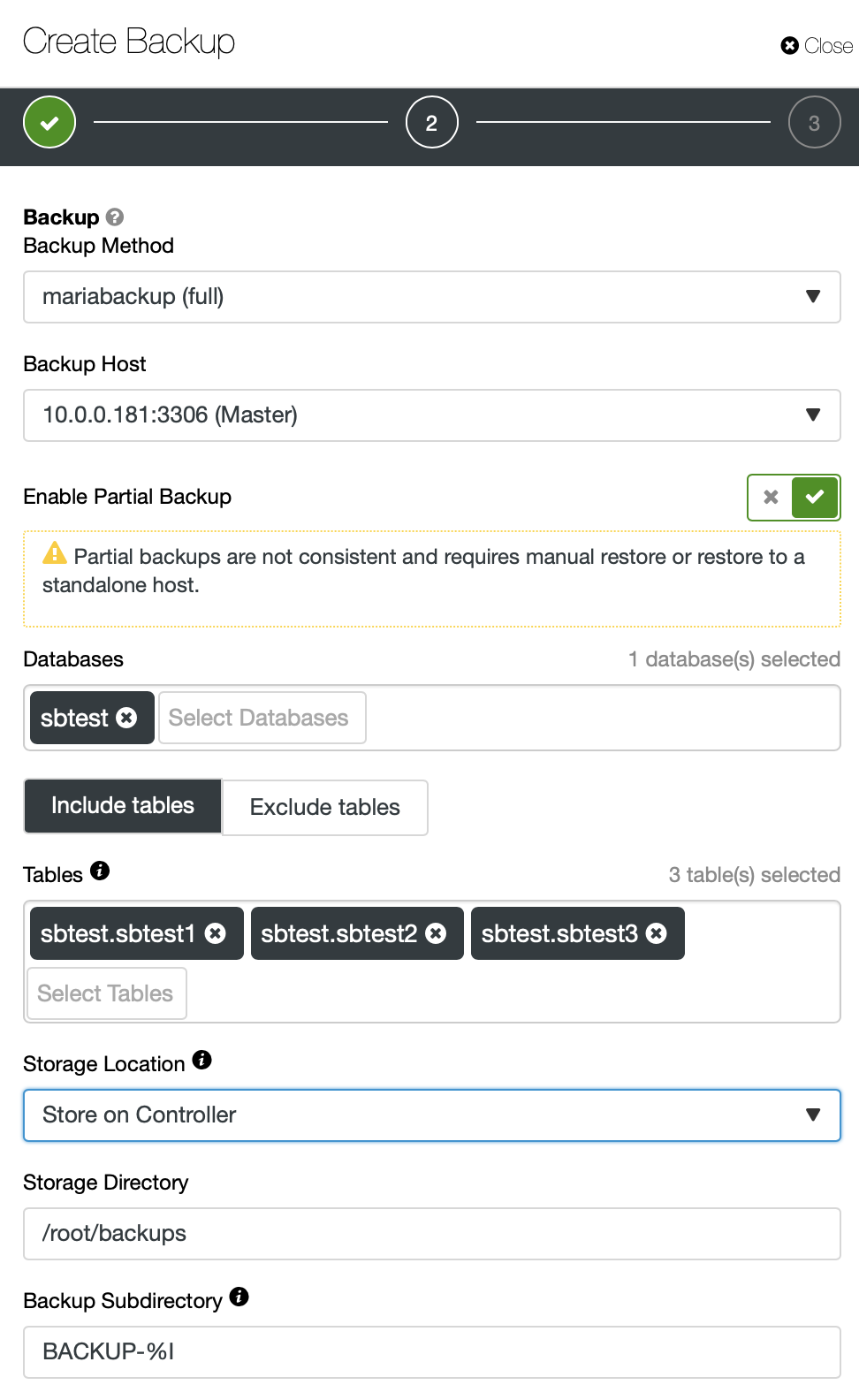
We have picked some of the tables and schemas and we are going to run this backup now. Of course, if you want that, you can schedule partial backups in exactly the same way as normal ones.
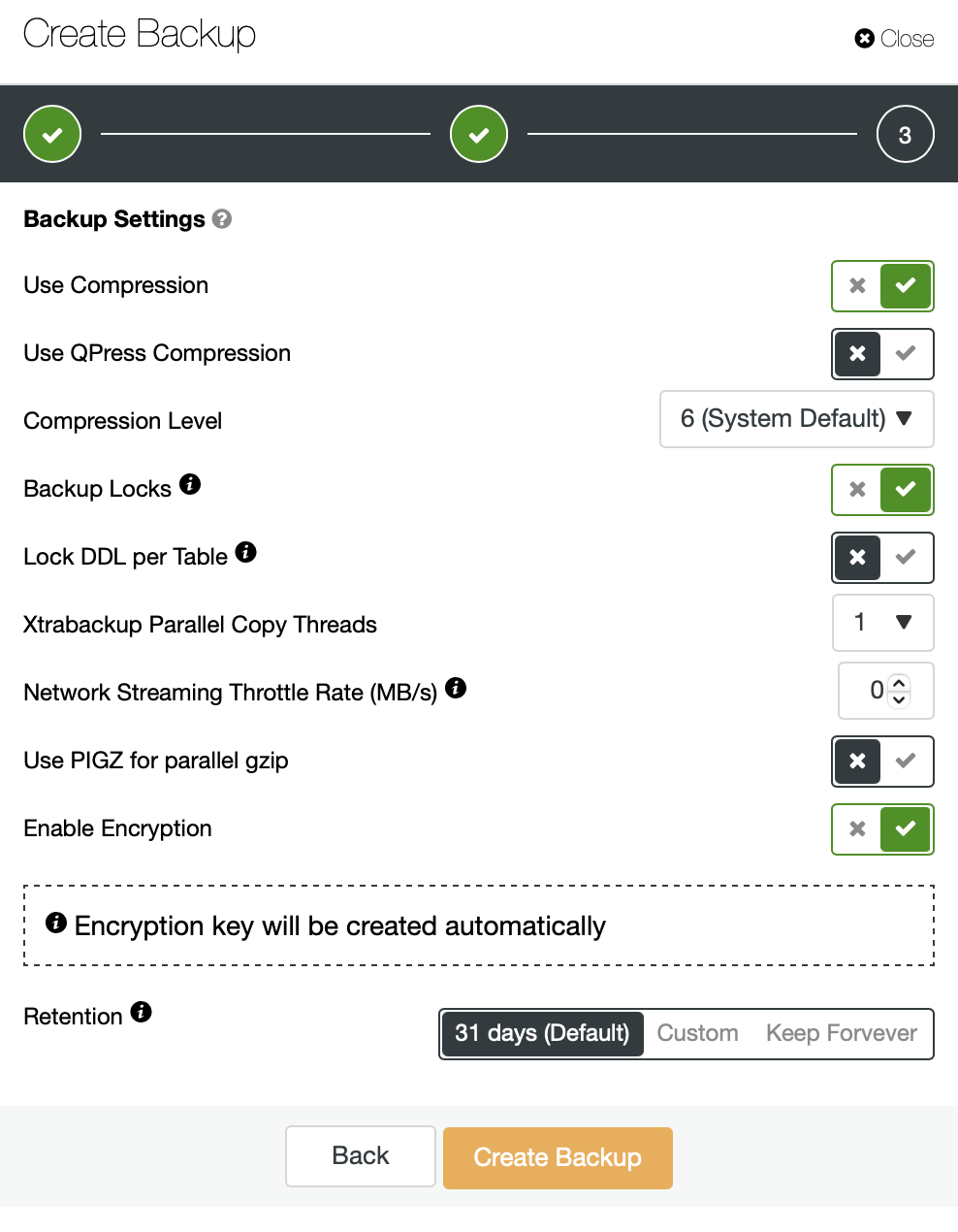
On the second screen we can configure mariabackup to our liking, just like we explained in our previous blog posts. That’s it, click on the Create Backup button and the process will start.
Restoring partial backup in ClusterControl
Once the backup is ready, it will become visible on the backup list.
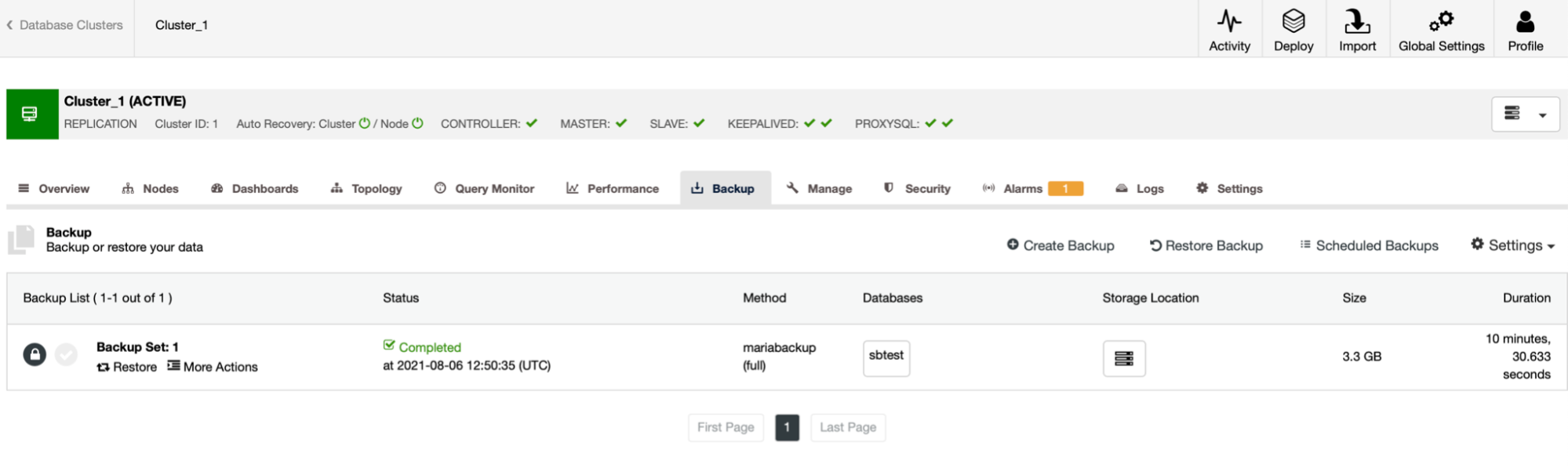
We can see it is a partial backup because there is a list of schemas that are included in it.
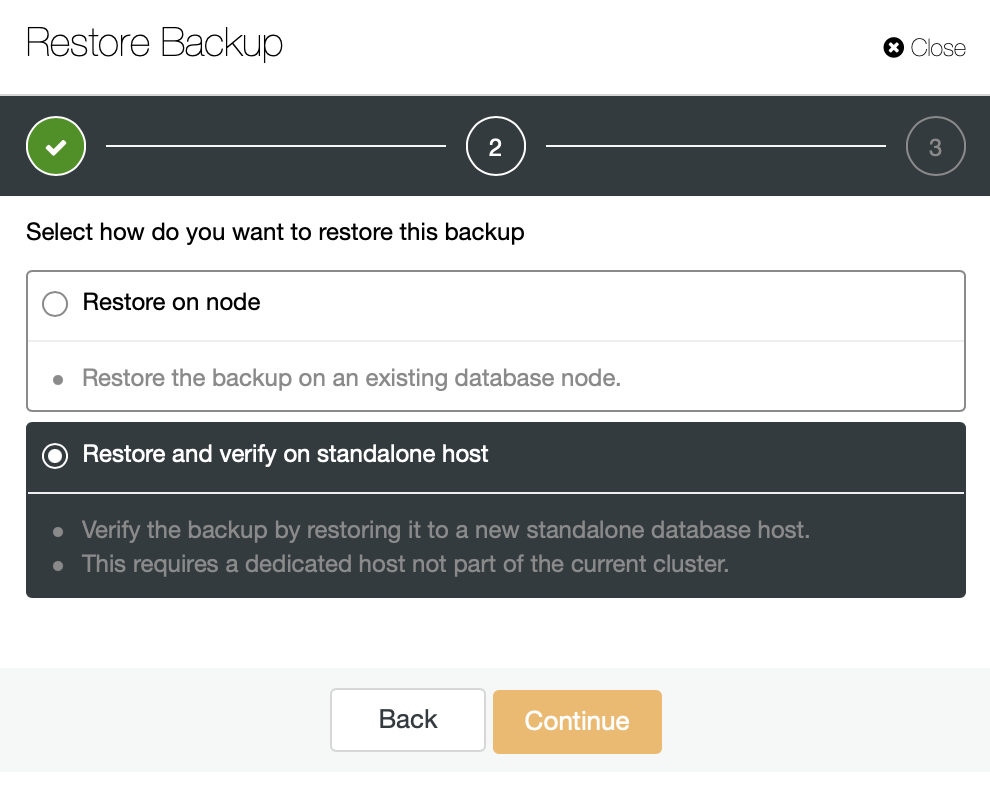
When we attempt to restore a partial backup in an asynchronous replication cluster we are presented with two options. Restore on node and restore and verify on standalone host. The former is definitely not something we want to do as it would wipe out some of the data we do not have in the backup. The latter option, on the other hand, allows you to deploy a separate node and restore the backup on it.
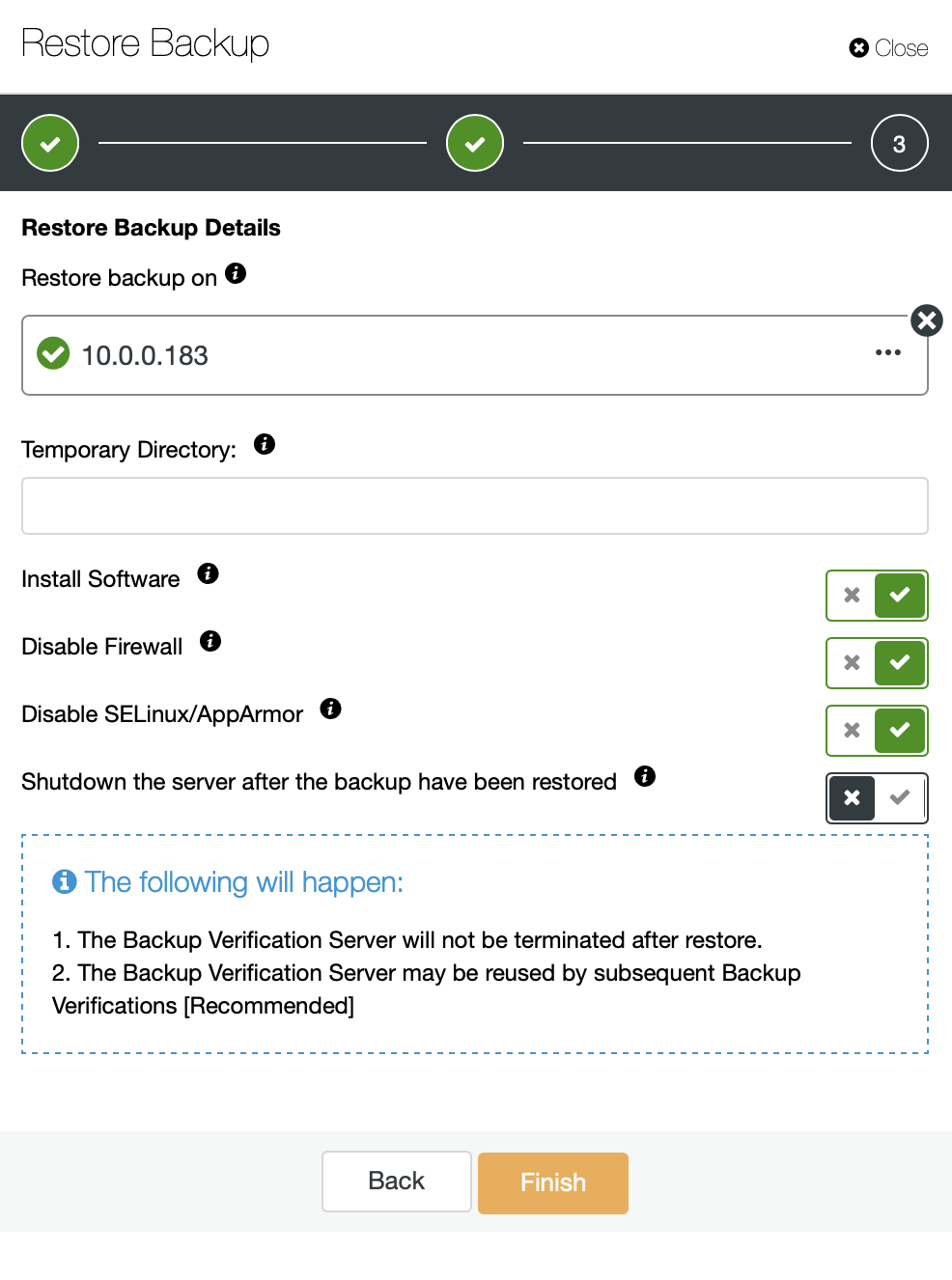
All that we need to do is to pick a hostname that is reachable by SSH from ClusterControl and ensure that it won’t be stopped after the backup is restored. This will let us restore the partial backup and then access it to extract any kind of data we may want.
We hope that this short blog gives you some insight into how ClusterControl allows you to perform partial backups, what are the use cases and how can you restore them in a safe way.



