blog
MySQL Database Management Common Operations – Replication Topology Changes

MySQL replication has been available for years, and even though a number of new clustering technologies showed up recently, replication is still very common among MySQL users. It is understandable as replication is a reliable way of moving your data between MySQL instances. Even if you use Galera or NDB cluster, you still may have to rely on MySQL replication to distribute your databases across WAN.
In this blog post we’d like to discuss one of the most common operations DBA has to handle – replication topology changes and planned failover.
This is the fifth installment in the ‘Become a MySQL DBA’ blog series, and discusses one of the most common operations a DBA has to handle – replication topology changes and planned failover. Our previous posts in the DBA series include Schema Changes, High Availability, Backup & Restore, Monitoring & Trending.
Replication Topology Changes
In a previous blog post, we discussed the schema upgrade process and one of the ways to execute it is to perform a rolling upgrade – an operation that requires changes in replication topology. We’ll now see how this process is actually performed, and what you should keep an eye on. The whole thing is really not complex – what you need to do is to pick a slave that will become a master later on, reslave the remaining slaves off it, and then failover. Let’s get into the details.
Topology Changes Using GTID
First things first, the whole process depends on whether you use Global Transaction ID or regular replication. If you use GTID, you are in much better position as GTID allows you to move a host into any position in the replication chain. There’s no need for preparations, you just move the slaves around using:
STOP SLAVE;
CHANGE MASTER TO master_host='host', master_user='user', master_password='password', master_auto_position=1;
START SLAVE;We’ll describe the failover process later in more detail, but what needs to be said now is that, once you make a failover, you’ll end up with a master host that is out of sync. There are ways to avoid that (and we’ll cover them), but if you use GTID, the problem can be easily fixed – all you need to do is to slave the old master off any other host using the command above. The old master will connect, retrieve any missing transactions, and get back in sync.
Topology Changes Using Standard Replication
Without GTID, things are definitely more complex as you can’t rely on a slave being aware of the transactions that are missing. The most important rule to keep in mind is that you have to ensure your slaves are in a known position to each other before any topology change is performed. Consider the following example.
Let’s assume the following, rather typical, replication topology: one master and three slaves.
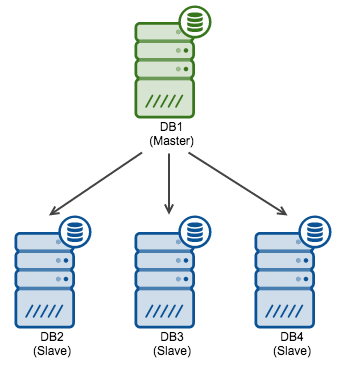
Let’s also assume that you are executing a rolling schema change and you’d like to promote “DB2” to become the new master. At the end you’d like the replication topology to look like this:
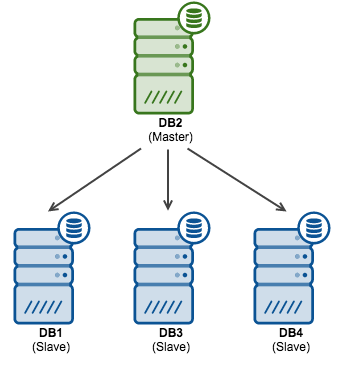
What needs to be accomplished is to slave DB3 and DB4 off DB2 and then finally, after the failover, to slave DB1 off DB2. Let’s start with DB3 and DB4.
If you plan to slave DB3 and DB4 off DB2, you need to enable binlogs on that host and enable log-slave-updates option. Otherwise it won’t record events from DB1 in it’s binary logs.
What’s required in the reslaving process is to have all of the involved nodes stopped at the same transaction in relation to the master. There are couple of ways to achieve that. One of them is to use START SLAVE UNTIL … to stop them in a known position. Here is how you do that. We need to check the SHOW MASTER STATUS on the master host (DB1 in our case):
mysql> show master statusG
*************************** 1. row ***************************
File: mysql-bin.000119
Position: 448148420
Binlog_Do_DB:
Binlog_Ignore_DB:Then, on all involved hosts (DB2, DB3 and DB4), we need to stop replication and then start it again, this time using START SLAVE UNTIL and setting it to stop at the first event, two binary logs later.
You can find a position of the first event by running mysqlbinlog on one of the binary logs:
mysqlbinlog /mysqldata/mysql-bin.000112 | head -n 10
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!40019 SET @@session.max_insert_delayed_threads=0*/;
/*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#150705 23:45:22 server id 153011 end_log_pos 120 CRC32 0xcc4ee3be Start: binlog v 4, server v 5.6.24-72.2-log created 150705 23:45:22
BINLOG '
ksGZVQ+zVQIAdAAAAHgAAAAAAAQANS42LjI0LTcyLjItbG9nAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXAAEGggAAAAICAgCAAAACgoKGRkAAb7j
Tsw=In our case, the first event is at the position of 4 therefore we want to start the slaves in the following manner:
START SLAVE UNTIL master_log_file='mysql-bin.000121', master_log_pos=4;All slaves should catch up and proceed with the replication. Next step is to stop them – you can do it by issuing FLUSH LOGS on the master two times. This will rotate binlogs and eventually open a mysql-bin.000121 file. All slaves should stop at the same position (4) of this file. In this way we managed to bring all of them to the same position.
Once that’s done, the rest is simple – you need to ensure that the binlog position (checked using SHOW MASTER STATUS) doesn’t change on any of the nodes. It shouldn’t as the replication is stopped. If it does change, something is issuing writes to the slaves which is very bad position to be in – you need to investigate before you can perform any further changes. If everything is ok, then all you need is to grab the current stable binary log coordinates of DB2 (future master) and then execute CHANGE MASTER TO … on DB3 and DB4 using those positions and slaving those hosts off DB2. Once it’s done, you can commence replication on the DB2. At this point you should have following replication topology:
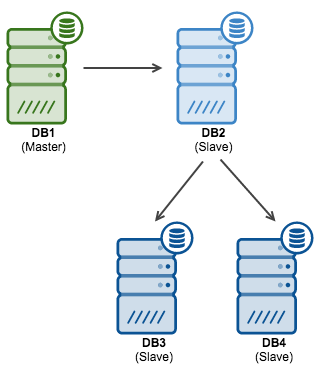
As we are talking about planned failover, we want to ensure that after it’s done, we can slave DB1 off DB2. For that, we need to confirm that the writes from DB2 (which will happen after the failover), will end up in DB1 as well. We can do it by setting up master – master replication between those two nodes. It’s a very simple process, as long as DB2 is not yet written to. If it is, then you might be in trouble – you’ll need to identify the source of these writes and remove it. One of the ways to check it is to convert binary logs to the plain text format using the mysqlbinlog utility and then look for the server id’s. You should not see any id’s other than that of the master.
If there are no writes hitting DB2, then you can go ahead and execute CHANGE MASTER TO … on DB1 pointing it to the DB2 and using any recent coordinates – no need to stop the replication as it is expected that no writes will be executed on DB1 while we fail over. Once you slave DB1 off DB2, you can monitor replication for any unexpected writes coming from DB2 by watching Exec_Master_Log_Pos in the SHOW SLAVE STATUS. On DB1 it should be constant as there should be nothing to execute. At this time, we have the following replication topology ready for the failover:
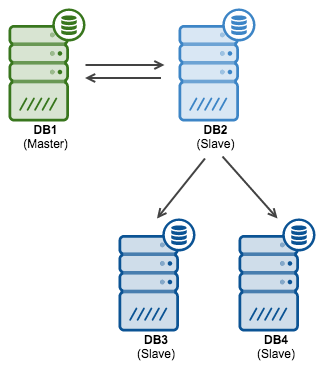
Failover process
Failover process is tricky to describe as it is strongly tied to the application – your requirements and procedures may vary from what we’ll describe here. Still, we think it’s a good idea to go over this process and point to some important bits that should be common for many applications.
Assuming that you have your environment in the state we described above (all slaves slaved off the master candidate and master in master-master replication with the master candidate), there’s not much else to do on the database side – you are well prepared. The rest of the process is all about ensuring that there are no violations of consistency during the failover. For that, the best way is to stop the application. Unfortunately, it is also the most expensive way.
When your application is down, you want to ensure that the database does not handle any writes and there are no new connections getting through. Writes can be verified by checking the SHOW MASTER STATUS output. Connections – by checking either processlist or Com-* counters. In general, as long as there are no writes, you should be just fine – it is not that big of a problem if there is a forgotten connection that is executing SELECTs. It would be a problem if it executes DML from time to time.
Once you verified that no DML hits the database, you need to repoint your application to the new master. In our example, that would be DB2. Again, all depends on how exactly you have your environment set up. If you have a proxy layer, you may need to implement some changes there. You should strive to automate this process, though, using scripts that’d detect whether a node is a master or a slave. This speeds things up and results in less mistakes. A common practice is to use read_only setting to differentiate master from slaves. Proxies can then detect if the node is a master or not, and route traffic accordingly. If you use this method, you can, as soon as you confirm no writes are coming, just set the read_only=1 on DB1 and then set read_only=0 on DB2 – it should be enough to repoint the proxy to a correct host.
No matter how you repoint the app (by changing read_only setting, proxy or app configuration or a DNS entry), once you’re done with it, you should test if the application works correctly after the change. In general, it’s great to have a “test-only” mode of an app – an option to keep it offline from public access but allow you to do some testing and QA before going live after such significant change. During those tests you may want to keep an eye on the old master (DB1 in our case). It should not take any writes, yet it is not uncommon to see that some forgotten piece of code is hardcoded to connect directly to a given database and that will cause problems. If you have DB1 and DB2 in master – master replication, you should be good in terms of the data consistency. If not, this is something you need to fix before going live again.
Finally, once you verified you are all good, you can go back live and monitor the system for a while. Again, you want to keep an eye on the old master to ensure there are no writes hitting it.
As you can imagine, replication topology changes and failover processes are common operations, albeit complex. In future posts, we will discuss rolling MySQL upgrades and migrations between different environments. As we mentioned earlier, even if you use Galera or NDB Cluster you may need to use replication to connect different datacenters or providers over a WAN, and eventually perform the standard planned failover process that we described above.



