blog
Automating MySQL Replication with ClusterControl 1.4.0 – What's New

With the recent release of ClusterControl 1.4.0, we added a bunch of new features to better support MySQL replication users. In this blog post, we’ll give you a quick overview of the new features.
Enhanced Multi-Master Deployment
A simple master-slave replication setup is usually good enough in a lot of cases, but sometimes, you might need a more complex topology with multiple masters. With 1.4.0, ClusterControl can help provision such setups. You are now able to deploy a multi-master replication setup in active – standby mode. One of the masters will actively take writes, while the other one is ready to take over writes should the active master fail. You can also easily add slaves under each master, right from the UI.
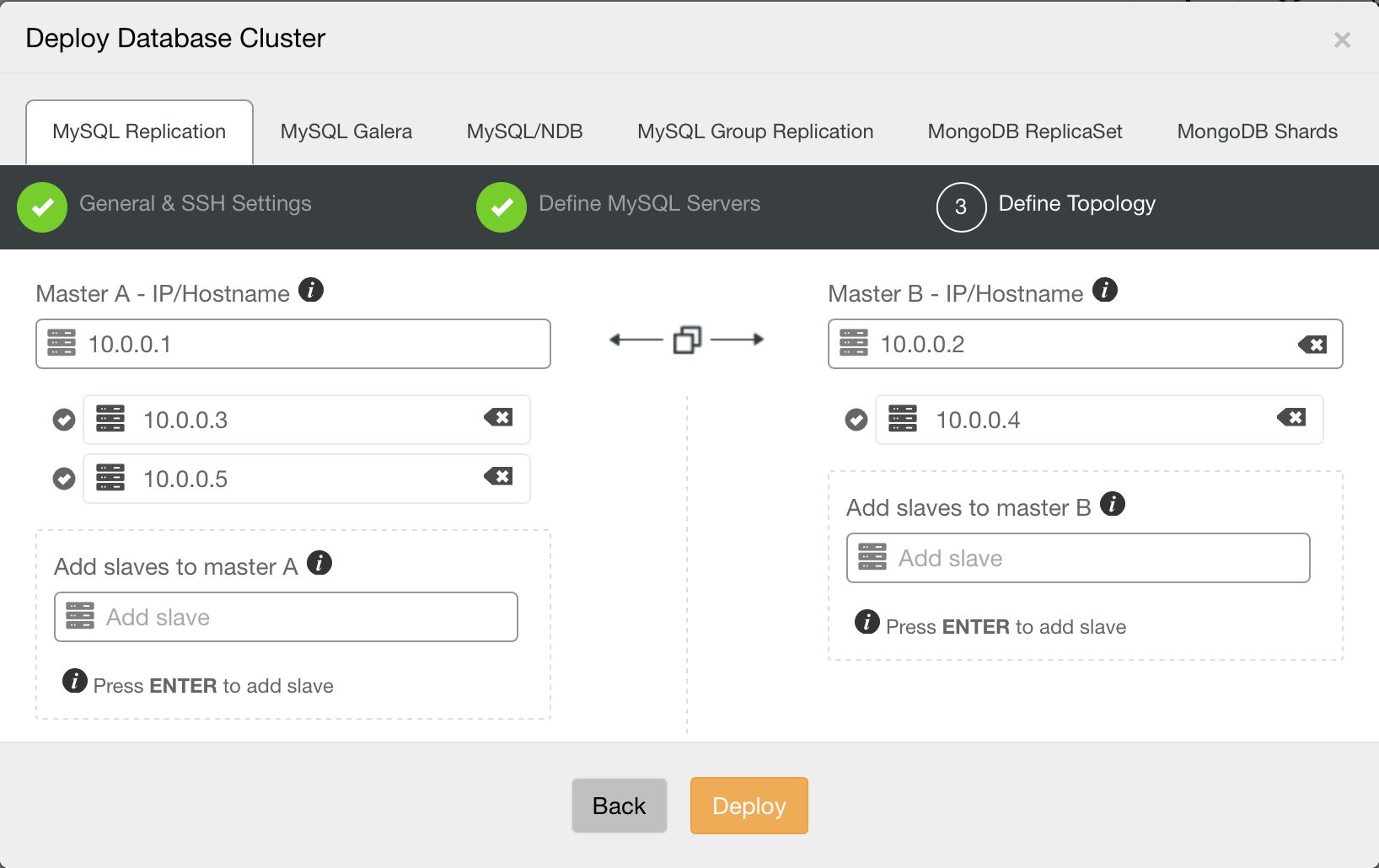
Enhanced Flexibility in Replication Topology Management
With support for multi-master setups comes improved support for managing replication topology changes. Do you want to re-slave a slave off the standby master? Do you want to create a replication chain, with an intermediate master in-between? Sure! You can use a new job for that: “Change Replication Master”. Just go to one of the nodes and pick that job (not only on the slaves, you can also change replication master for your current master, to create a multi-master setup). You’ll be presented with a dialog box in which you can pick the master from which to slave your node off. As of now, only GTID-enabled replication is supported, both Oracle and MariaDB implementations.
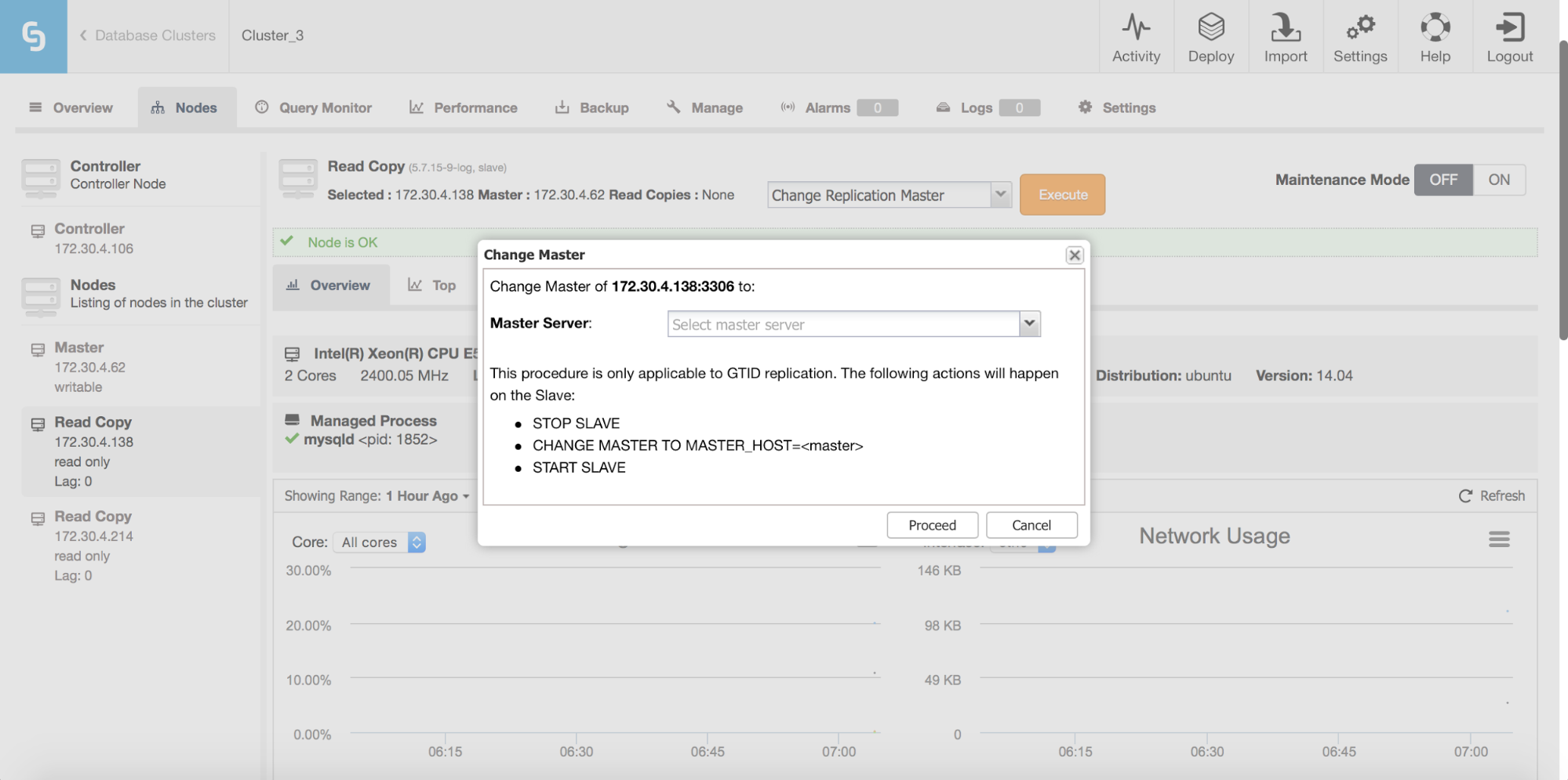
Replication Error Handling
You may ask – what about issues like errant transactions which can be a serious problem for MySQL replication? Well, for starters, ClusterControl always set slaves in read_only mode so only a superuser can create an errant transaction. It still may happen, though. That’s why we added replication error handling in ClusterControl.
Errant transactions are common and they are handled separately – errant transactions are checked for before any failover or switchover happens. The user can then fix the problem before triggering a topology change once more. If, for some reason (like high availability, for example), a user wants to perform a failover anyway, no matter if it is safe or not, it can also be done by setting:
replication_stop_on_error=0This is set in the cmon configuration file of the replication setup ( /etc/cmon.d/cmon_X.cnf, where X is the cluster ID of the replication setup). In such cases, failover will be performed even if there’s a possibility that replication will break.
To handle such cases, we added experimental support for slave rebuilding. If you enable replication_auto_rebuild_slave in the cmon configuration and if your slave is marked as down with the following error in MySQL:
Got fatal error 1236 from master when reading data from binary log: ‘The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.’
ClusterControl will attempt to rebuild the slave using data from the master. Such a setting may be dangerous as the rebuilding process will induce an increased load on the master, it may also be that your dataset is very large and a regular rebuild is not an option – that’s why this behavior is disabled by default. Feel free to try it out, though and let us know what you think about it.
Automated Failover
Handling replication errors is not enough to maintain high availability with MySQL replication – you need also to handle crashes of MySQL instances. Until now, ClusterControl alerted the user and let her perform a manual failover. With ClusterControl version 1.4.0 comes support for automated failover handling. It is enough to have cluster recovery enabled for your replication cluster and ClusterControl will try to recover your replication cluster in the best way possible. You must explicitly enable “Cluster Auto Recovery” in the UI in order for automatic failover to be activated.
Once a master failure is detected, ClusterControl starts to look for the most up-to-date slave available. Once it’s been found, ClusterControl checks the remaining slaves and looks for additional, missing transactions. If such transactions are found on some of the slaves, the master candidate is configured to replicate from each of those slaves and apply any missing transactions.
If, for any reason, you’d rather not wait for a master candidate to get all missing transactions (maybe because you are 100% sure there won’t be any), you can disable this step by enabling the replication_skip_apply_missing_txs setting in cmon configuration.
For MariaDB setups, the behavior is different – ClusterControl picks the most advanced slave and promotes it to become master.
Getting missing transactions is one thing. Applying them is another. ClusterControl, by default, does not fail over to a slave if the slave has not applied all missing transactions. You could lose data. Instead, it will wait indefinitely to allow slaves to catch up. Of course, if the master candidate becomes up to date, ClusterControl will failover immediately after. This behavior can be configured using replication_failover_wait_to_apply_timeout setting in the cmon configuration file. Default value (-1) prevents any failover if master candidate is lagging behind. If you’d like to execute failover anyway, you can set it to 0. You can also set a timeout in seconds, this is the amount of time that ClusterControl will wait for a master candidate to catch up before performing a failover.
Once a master candidate is brought up to date, it is promoted to master and the remaining slaves are slaved off it. The exact process differs depending on which host failed (the active or standby master in a multi-master setup) but the final outcome is that all slaves are again replicating from the working master. Combined with proxies such as HAProxy, ProxySQL or MaxScale, this lets you build an environment where a master failure is handled in an automated and transparent way.
Additional control over failover behavior is granted through replicaton_failover_whitelist and replicaton_failover_blacklist lists in the cmon configuration file. These let you configure a list of slaves which should be treated as a candidate list to become master, and a list of slaves which should not be promoted to master by ClusterControl. There are numerous reasons you may want to use those variables. Maybe you have some backup or OLAP/reporting slaves which are not suitable to become a master? Maybe some of your slaves use weaker hardware or maybe they are located in a different datacenter? In this case, you can avoid them from being promoted by adding those slaves to the replicaton_failover_blacklist variable.
Likewise, maybe you want to limit the number of slaves that are promotable to a particular set of hosts which are the closest to the current master? Or maybe you use master – master, active – passive setup and you want only your standby master to be considered for promotion? Then specify the IP’s of master candidates in the replicaton_failover_whitelist variable. Please keep in mind that a restart of cmon process will be required to reload such configuration. By executing cmon –help-config on the controller, you will get more detailed information about these (and other) parameters.
Finally, you might want to manually restore replication.If you do not want ClusterControl to perform any automated failover in your replication topology, you can disable cluster recovery from the ClusterControl UI.
So, there are lots of good stuff to try out here for MySQL replication users. Do give it a try, and let us know how we’re doing.




