blog
Leveraging AWS Tools to Speed up the Management of Galera Cluster on Amazon Cloud

We previously covered basic tuning and configuration best practices for MyQL Galera Cluster on AWS. In this blog post, we’ll go over some AWS features/tools that you may find useful when managing Galera on Amazon Cloud. This won’t be a detailed how-to guide as each tool described below would warrant its own blog post. But this should be a good overview of how you can use the AWS tools at your disposal.
EBS Backups
If you have chosen EBS volumes as storage for your database (you could have chosen ephemeral volumes too), you can benefit greatly from their ability of taking snapshots of the data.
In general, there are two ways of running backups:
- Logical backup executed in the form of mysqldump, mydumper or similar tools. The result of it is a set of SQL commands which should recreate your database;
- Physical backup created, very often, using xtrabackup.
Xtrabackup is a great tool but it is limited by network performance. If you create a streaming backup, you need to push data over the network. If you have local backups but you want to provision a new host, you have to push the data over the network.
EBS volumes, on the other hand, allow you to take snapshots. Such snapshot can be then used to create a new EBS volume, which can be mounted to an existing instance or a new one. It limits the overhead of managing backups – no need to move them from one place to another, the snapshots are just there, when you need them.
There are couple of things you’d want to consider before relying on EBS snapshots as a backup solution. First – it is a snapshot. The snapshot is taken at a given time for a given volume. If MySQL is up, when it comes to data integrity, the snapshot data is somewhat equivalent to that of a forced power-off. If you’d like to restore a database from the snapshot, you should expect to perform InnoDB recovery – a process which may take a while to complete. You may minimize this impact by either running ‘FLUSH TABLES WITH READ LOCK’ as a part of the snapshotting process or, even better for the data consistency, you may stop the MySQL process and take a cold backup. As you can see, it’s up to you what kind of consistency you want to achieve, keeping in mind that consistency comes with the price of downtime (longer or shorter) of that instance.
If you are using multiple EBS volumes and created a RAID using mdadm, then you need to take a snapshot of all the EBS volumes at the same time. This is a tricky process and there are tools which can help you here. The most popular one is ec2-consistent-snapshot. This tool gives you plenty of options to choose from. You can lock MySQL with ‘FLUSH TABLE WITH READ LOCK’, you can stop MySQL, you can freeze the filesystem. Please keep in mind that you need to perform a significant amount of testing to ensure the backup process works smoothly and does not cause issues. Luckily, with the recent introduction of large EBS volumes, the need for RAIDed setups in EC2 decreases – more workloads can now fit in a single EBS volume.
Please keep in mind that there are plenty of use cases where using xtrabackup instead of (or along with, why not?) EBS snapshots makes much more sense. For example, it’s really hard to take a snapshot every 5 minutes – xtrabackup’s incremental backup will work just fine. Additionally (and it’s true for all physical backups) you want to make a copy of binary logs, to have the ability to restore data to a certain point in time. You can use snapshots as well for that.
Provisioning New Nodes Using EBS Snapshot
If we use EBS snapshots as backup method, we can use them to provision new nodes. It is very easy to provision a node in Galera cluster – just create an empty one, start MySQL and watch the full state transfer (SST). The main downside of SST is the time needed for it. It’s most probably using xtrabackup so, again, network throughput is crucial in overall performance. Even with fast networks, if we are talking about large data sets of hundreds of gigabytes or more, the syncing process will take hours to complete. It is independent of the actual number of write operations – e.g., even if we have a very small number of DML’s on a terabyte database, we still have to copy 1TB of data.
Luckily, Galera provides an option to make an incremental state transfer (IST). If all of the missing data is available in the gcache on the donor node, only that will be transferred, without the need of moving all of the data.
We can leverage this process by using a recent EBS snapshot to create a new node – if the snapshot is recent enough, other members of the cluster may still have the required data in their gcache.
By default, the gcache is set to 128M, which is fairly small buffer. It can be increased though. To determine how long the gcache can store data, knowing its size is not enough – it depends on the writeset sizes and number of writesets per second. You can monitor ‘wsrep_local_cached_downto’ variable to know the last writeset that is still cached. Below is a simple bash script which shows you for how long your gcache can store data.
#!/bin/bash
wsrep_last_committed=$(mysql -e "show global status like 'wsrep_last_committed'" | grep wsrep_last_committed | awk '{print $2}')
wsrep_local_cached_downto=$(mysql -e "show global status like 'wsrep_local_cached_downto'" | grep wsrep_local_cached_downto | awk '{print $2}')
date
echo ${wsrep_last_committed}
while [ ${wsrep_local_cached_downto} -lt ${wsrep_last_committed} ]
do
wsrep_local_cached_downto=$(mysql -e "show global status like 'wsrep_local_cached_downto'" | grep wsrep_local_cached_downto | awk '{print $2}')
sleep 1s
done
date
echo ${wsrep_local_cached_downto}Once we size the gcache according to our workload, we can start to benefit from it.
We would start by creating a node and then attach to it an existing EBS volume created from a snapshot of our data. Once the node is up, it’s time to check the grastate.dat file to make sure the proper uuid and sequence number are there. If you used a cold backup, most likely that data is already in place. If MySQL was online when the snapshot was taken, then you’ll probably see something like:
# GALERA saved state
version: 2.1
uuid: dbf2c394-fe2a-11e4-8622-36e83c1c99d0
seqno: -1
cert_index:In this is the case, we need to get a correct sequence number by running:
$ mysqld_safe --wsrep-recoverIn the result we should get (among other messages) something similar to:
150519 13:53:10 mysqld_safe Assigning dbf2c394-fe2a-11e4-8622-36e83c1c99d0:14 to wsrep_start_positionWe are interested in:
dbf2c394-fe2a-11e4-8622-36e83c1c99d0:14 That’s our uuid and sequence number – now we have to edit the grastate.dat file and set the uuid and seqno in the same way.
This should be enough (as long as the needed data is still cached on the donor node) to bring the node into the cluster without full state transfer (SST). Don’t be surprised – IST may take a while too. It really depends on the particular workload and network speed – you’d have to test in your particular environment to tell which way of provisioning is more efficient.
As always, when working with EBS snapshots, you need to remember the warmup process. Amazon suggests that the performance may be up to 50% lower if the volume is not warmed up. It is up to you if you’d like to perform the warmup or not but you need to remember that this process may takes several hours.If this is a planned scale-up, probably it is a good idea to set the wsrep_desync to ‘ON’ and perform the warmup process.
Using Amazon Machine Images to Speed up Provisioning
As you may know, an EC2 instance is created from an AMI – image of the instance. It is possible to create your own AMI using either CLI or just clicking in the web console. Why are we talking about it? Well, AMIs may come in handy when you customized your nodes heavily. Let’s say you installed a bunch of additional software or tools that you use in your day-to-day operations. Yes, those missing bits can be installed manually when provisioning a new node. Or, those missing bits can be installed via Chef/Puppet/Ansible/you_name_it in the provisioning process. But both manual installation or an automated provisioning process can take some time. Why not rely on an AMI to deliver us the exact environment we want? You can setup your node the way you like, pick it in the web console and then choose “Image” -> “Create Image” option. An AMI will be created based on the EBS snapshot and you can use it later to provision new nodes.
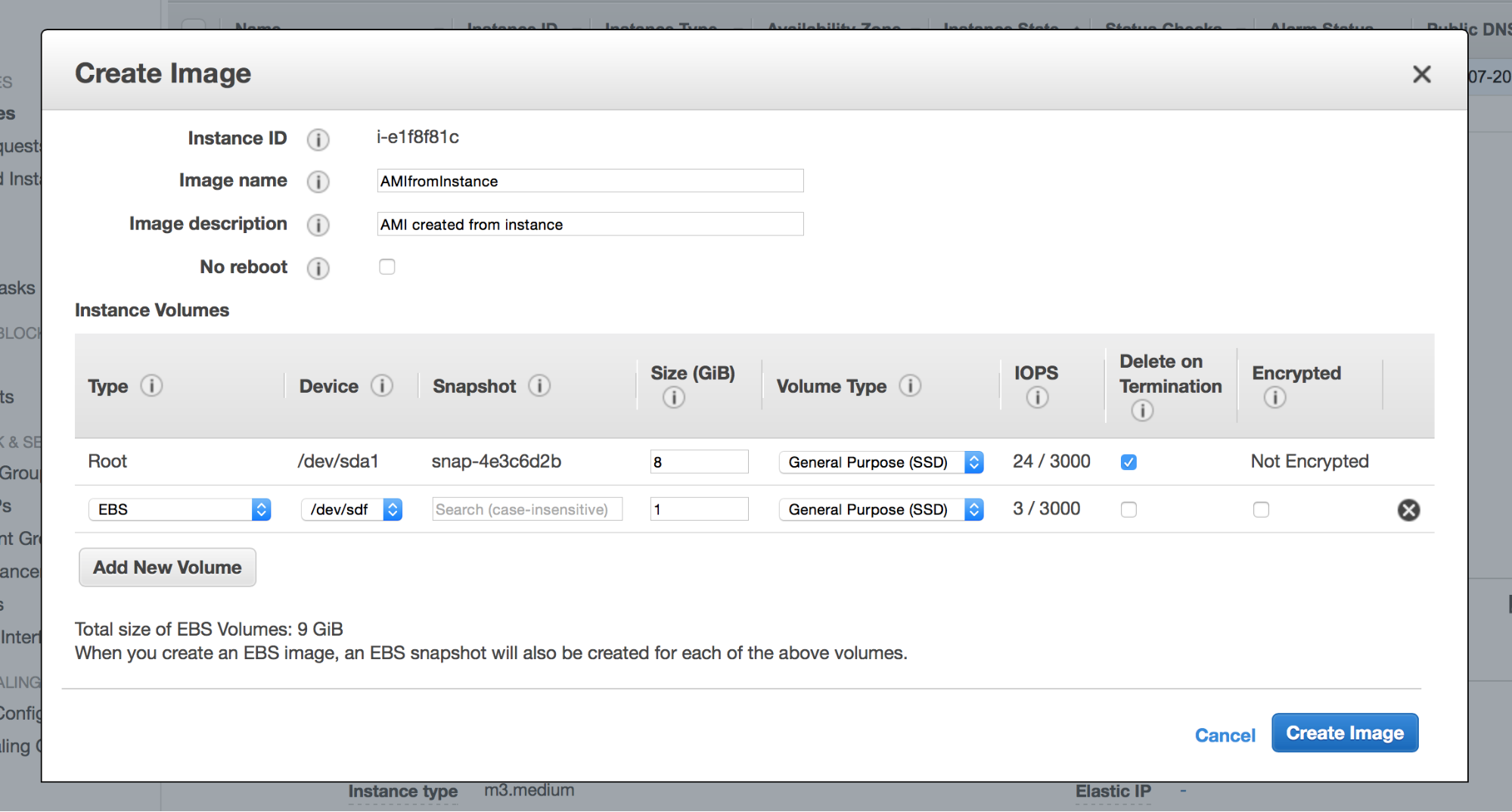
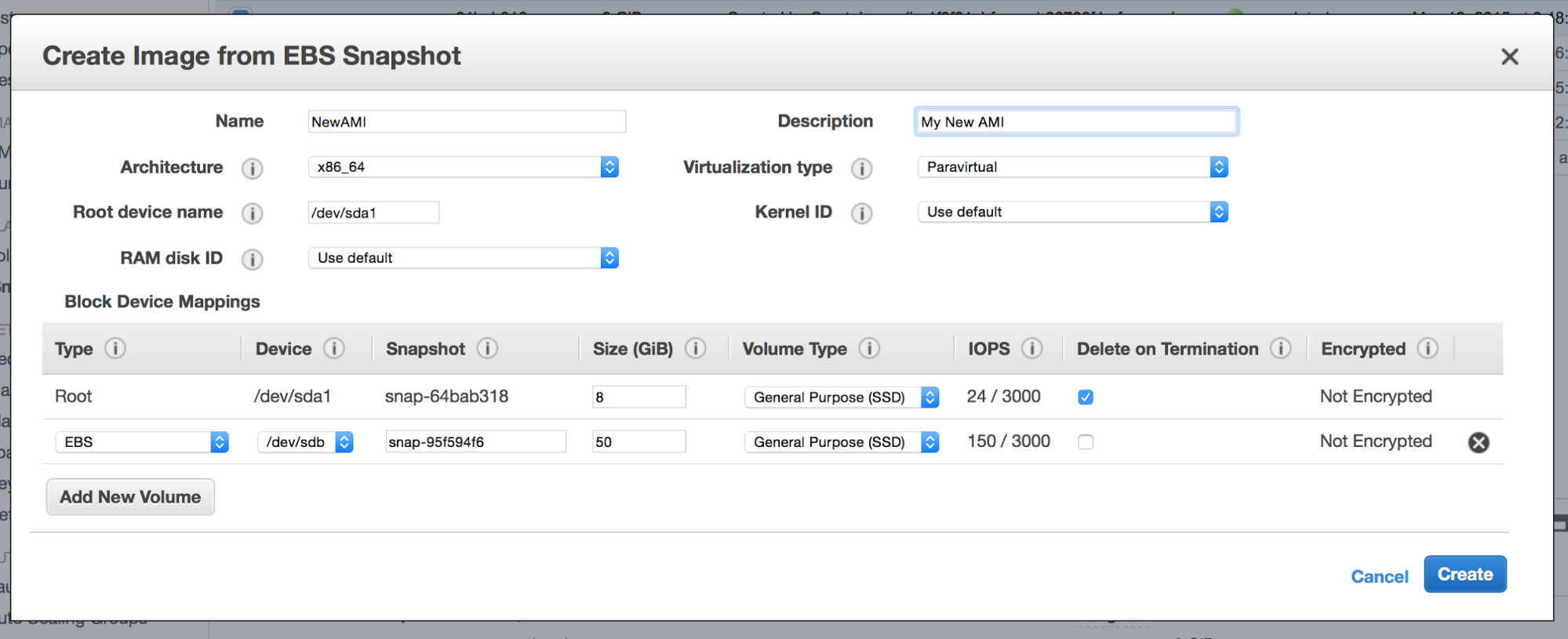
AMI’s can also be created from existing snapshots. This is actually great because, with a little bit of scripting, one can easily bundle the latest snapshots with the AMI and create an image that includes an almost up to date data directory.
Auto Scaling Groups
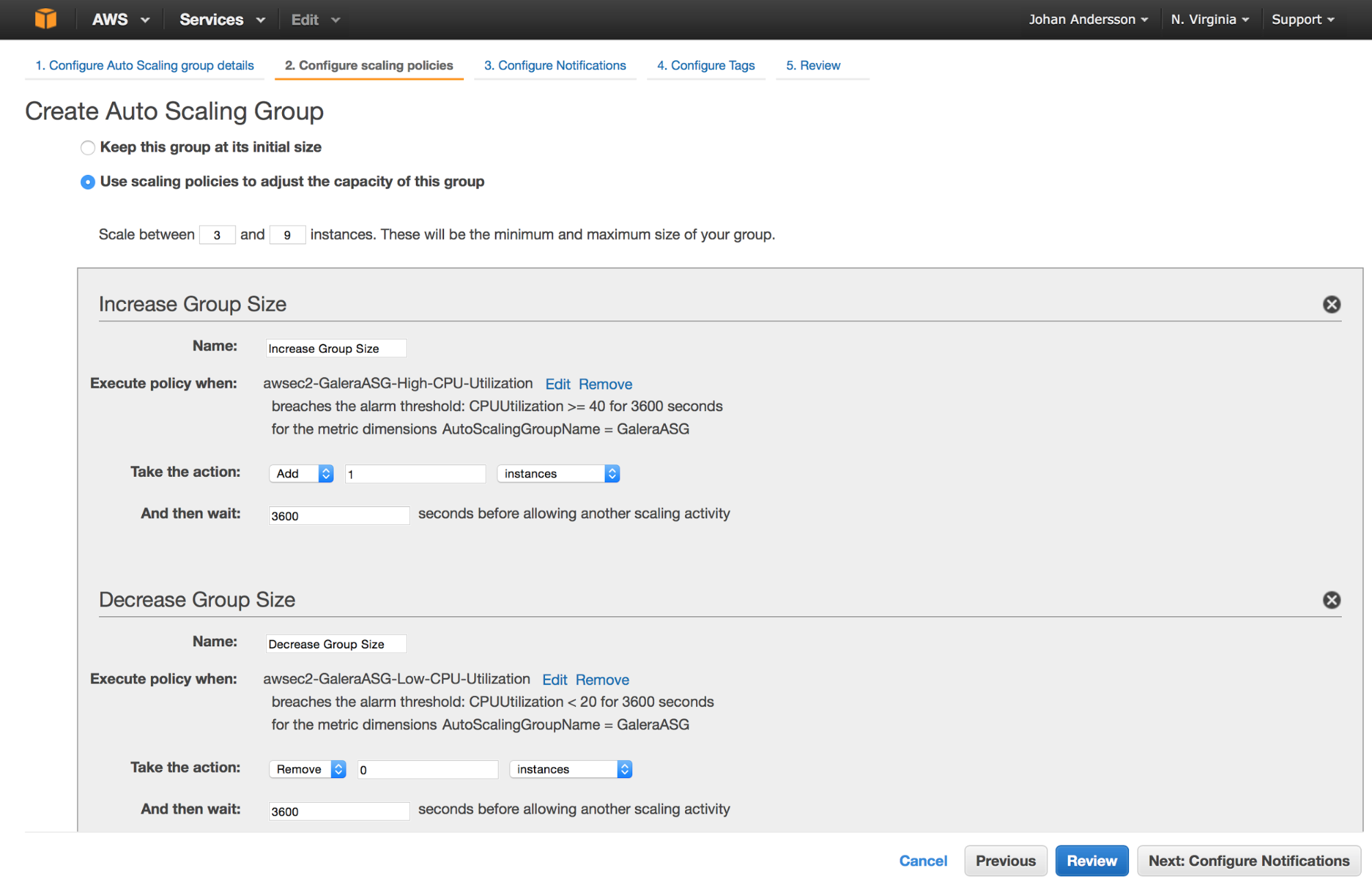
Auto scaling groups (ASG) is a set of mechanisms in EC2 that allows you to setup a dynamically scalable environment in several clicks. So AWS takes care of creating and destroying instances to maintain the required capacity. This can be useful if you get a surge in traffic, or for availability reasons in case you lose a few instances and want them replaced.
You would need to define the instance size to create, the AMI to create those new instances from and a set of conditions determining when new instances should be created. A simple example would be: ASG should have minimum 3, max 9 instances, split in three availability zones. A new instance should be added when CPU utilization is higher than 50% for a period of 2h, one of instances should be terminated when CPU utilization will be less than 20% for a period of 2h.
This tool is mostly designed for hosts which can be created and terminated quickly and easily, especially those that are stateless. Databases in general are more tricky, as they are stateful and a new instance is dependent on IO to sync up its data. Instances that use MySQL replication are not so easy to spin up but Galera is slightly more flexible, especially if we combine it with automated AMI creation to get the latest data included when the instance comes up.
One main problem to solve is that the Galera nodes need a wsrep_cluster_address setup with IP addresses of the nodes in the cluster. It uses this data to find other members of the cluster and to join the group communication. It is not required to have all of the cluster nodes listed in this variable, there has to be at least one correct IP.
We can approach this problem twofold. We can setup a semi-auto scaling environment – spin up a regular Galera cluster, let’s say three nodes. This will be a permanent part of our cluster. As a next step, we can create an AMI with wsrep_cluster_address including those three IP addresses and use it for the ASG. In this way, every new node created by the ASG will join the cluster using an IP of one of those permanent nodes. This approach has one significant advantage – by having permanent nodes, we can ensure to have a node with full gcache. You need to remember that the gcache is an in-memory buffer and is cleared after node restart.
Using Simple Notification Service as a Callback to ASG
Another approach would be to fully automate our auto-scaling environment. For that we have to find a way of checking when ASG decided to create a new node, or terminate an old one, before updating wsrep_cluster_address. We can do this using SNS.
First of all, a new “topic” (access point) needs to be created and a subscription needs to be added to this topic. The trick here is to use http protocol for a subscription.
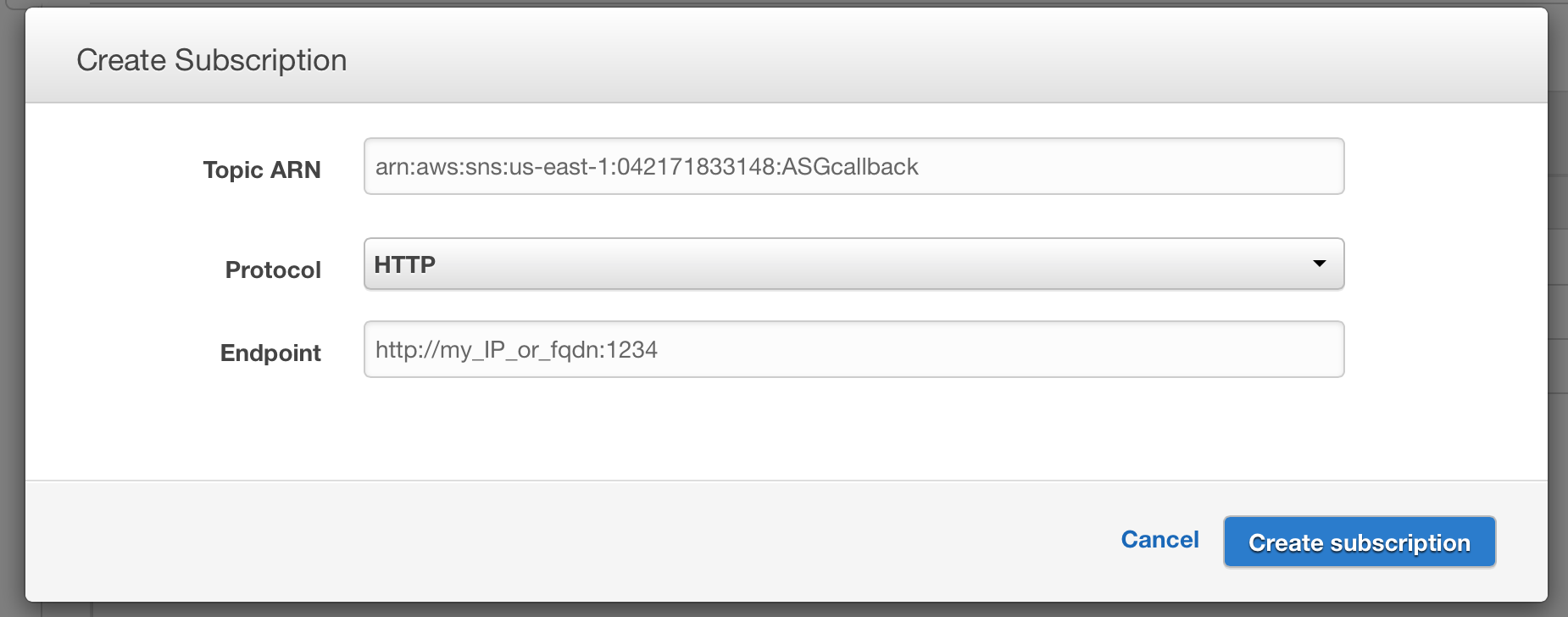
This way, notifications related to a given topic will be sent as a POST request to the given http server. It’s great for our needs because we can create a handler (it can be either a daemon or xinetd service that calls some script) that will handle the POST messages, parse them and perform some actions as defined in our implemented logic.
Once we have a topic and subscription ready, when creating ASG, you can pick one of the SNS topics as a place where notifications will be sent.
The whole workflow looks as below:
- One of the conditions was met and ASG scale up/down event has been triggered
- New instance is added (or an old one is removed)
- Once that is done, notification will be sent to the defined SNS topic
- Handler script listening on the http address defined for the SNS subscription parses the POST request and does it’s magic.
The magic mentioned in the last point can be done in many ways, but the final result should be to get the IP addresses of the current set of Galera nodes and update wsrep_cluster_address accordingly. It may also require node restart for the joining node (to actually connect to the cluster using the new set of IP’s from wsrep_cluster_address). You may also need to setup Galera segments accordingly should you want to use them. Maybe a proxy configuration will have to be updated also?
All this can be done in multiple ways. One of them would be to use Ansible + ec2.py script as a dynamic inventory and use tags to mark new instances that need configuration (you can setup a set of tags for instances created by ASG), but it can be done using any tool as long as it works for you.
The main disadvantage of this fully automated approach is that you don’t really control when a given instance will be terminated, which one will be picked up for a termination etc. It should not be a problem in terms of the availability (your setup should be able to handle instances going down at random times anyway) but it may cause some additional scripting to handle the dynamic nature. It will also be more prone to SST (compared to a hybrid static/dynamic approach described earlier). That is, unless you add logic to check the wsrep_local_cached_downto and pick a donor based on the amount of data in the gache instead of relying on Galera itself to automatically choose the donor.
One important point to remember is that Galera takes time to get up and running – even IST may take some time. This needs to be taken under consideration when creating autoscaling policies. You want to allow some time for a Galera node to get up to speed and take traffic before proceeding with adding another node to the cluster. You also don’t want to be too aggressive in terms of the thresholds that determine when a new node should be launched – as the launch process is taking time, you’d probably want to wait a bit to confirm the scale-up is indeed required.



