blog
Big Data Integration & ETL – Moving Live Clickstream Data from MongoDB to Hadoop for Analytics

MongoDB is great at storing clickstream data, but using it to analyze millions of documents can be challenging. Hadoop provides a way of processing and analyzing data at large scale. Since it is a parallel system, workloads can be split on multiple nodes and computations on large datasets can be done in relatively short timeframes. MongoDB data can be moved into Hadoop using ETL tools like Talend or Pentaho Data Integration (Kettle).
In this blog, we’ll show you how to integrate your MongoDB and Hadoop datastores using Talend. We have a MongoDB database collecting clickstream data from several websites. We’ll create a job in Talend to extract the documents from MongoDB, transform and then load them into HDFS. We will also show you how to schedule this job to be executed every 5 minutes.
Test Case
We have an application collecting clickstream data from several websites. Incoming data is mostly inserts generated from user actions against HTML Document Object Model (DOM) and stored in a MongoDB collection called domstream. We are going to bulk load our data in batch from the MongoDB collection into Hadoop (as an HDFS output file). Hadoop can then be used as a data warehouse archive on which we can perform our analytics.
For step by step instructions on how to set up your Hadoop cluster, please read this blog post. Our architecture can be illustrated as below:
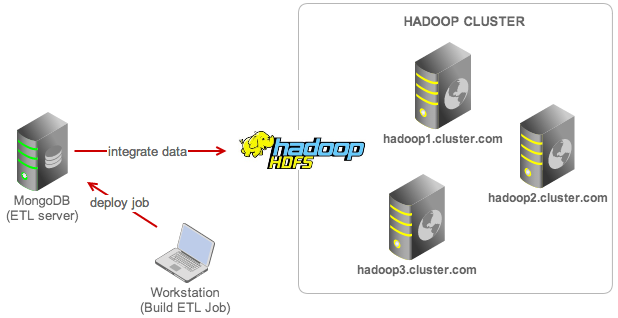
Our goal is to bulk load the MongoDB data to an HDFS output file every 5 minutes. The steps are:
- Install Talend
- Design the job and workflow
- Test
- Build the job
- Transfer the job to MongoDB server (ETL server)
- Schedule it to run in production via cron
Install Talend Open Studio
We’ll be using Talend Open Studio for Big Data as our ETL tool. Download and install the application on your local workstation. We’ll use it to design and deploy the process workflow for our data integration project.
Extract the downloaded package and open the application. Accept the license and create a new project called Mongo2Hadoop. Choose the corresponding project and click Open. You can skip the TalendForge sign-in page and directly access the Talend Open Studio dashboard. Click on Job under Create a new section and give the job a name. We are going to use the same name with project name.
This is what you should see once the job is created:
MongoDB to Hadoop
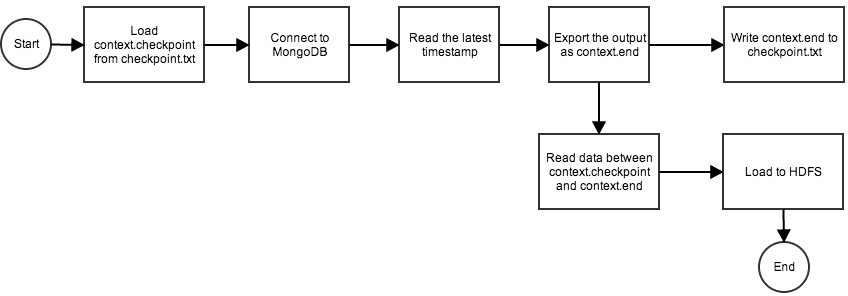
Talend Open Studio has several components that can help us achieve the same goal. In this post, we will focus on a basic way and use only a few components to accomplish our goal. Our process workflow will look like this:
- Load checkpoint value (timestamp) from checkpoint.txt. This is the timestamp of the latest document that was transferred from MongoDB.
- Connect to MongoDB.
- Read the timestamp of the latest document, export it as context.end and output it to checkpoint.txt.
- Read all documents between the checkpoint value and context.end.
- Export the output to HDFS.
The above process is represented in following flowchart:
Load Checkpoint Value
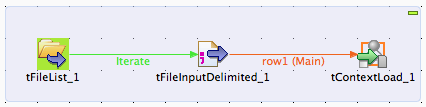
Let’s start designing the process. We will create several subjobs to form a MongoDB to Hadoop data integration job. The first subjob is loading up the checkpoint value from an external file.
Under Palette tab, drag tFileList, tFileInputDelimited and tContextLoad into the Designer workspace. Map them together as a subjob similar to following screenshot:
Specify the component’s option under Component tab as below:
| Component | Settings |
|---|---|
| tFileList_1 |
|
| tFileInputDelimited_1 |
|
| tContextLoad_1 |
|
Create a default file under tFileList workspace directory called checkpoint.txt. Insert following line and save:
checkpoint;0
This indicates the starting value that the subjob will use, when reading from our MongoDB collection. The value 0 will be updated by the next subjob after it has read the timestamp of the latest document in MongoDB. In this subjob, we define tFileList to read a file called checkpoint.txt, and tFileInputDelimited will extract the key value information as below:
- key=checkpoint
- value=0
Then, tContextLoad will use those information to set the value of context.checkpoint to 0, which will be used in other subjobs.
Read the Latest Timestamp
Another subjob is to read the latest timestamp from the domstream collection, export it to an external file and as a variable (context.end) to be used by the next subjob.
Add tMongoDBConnection, tSendMail, tMongoDBInput, tMap, tFileOutputDelimited and tContextLoad into the Designer workspace. Map them together as below:
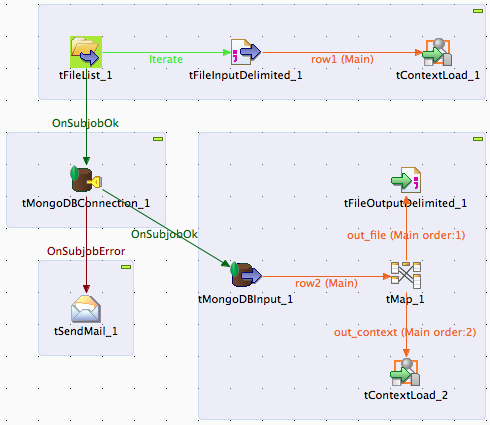
tMongoDBConnection_1
This component initiates the connection to MongoDB server to be used by the next subjob. If it fails, Talend will send a notification email through the tSendMail component. This is optional and you may configure tSendMail with an SMTP account.
Specify the MongoDB connection parameters as below:
- DB Version: MongoDB 2.5.X
- Server: “192.168.197.40”
- Port: “27017”
- Database: “clickstream”
tMongoDBInput_1
Read the latest timestamp from the MongoDB domstream collection. Specify the component options as per below:
-
Check Use existing connection and choose tMongoDBConnection_1 from the dropdown list.
-
Collection: “domstream”
-
Click on the Edit schema button and add a column named timestamp (in this subjob, we just want to read the timestamp value), similar to the screenshot below:
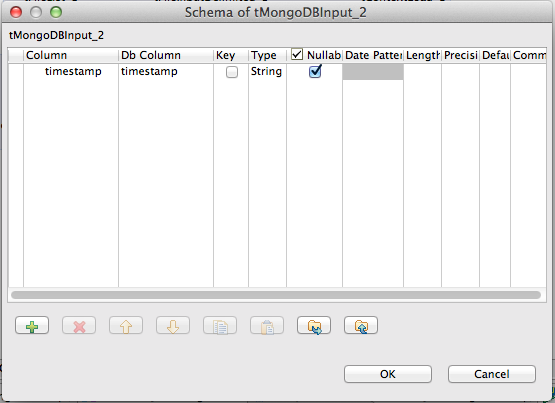
-
Query: “{},{timestamp:1, _id:0}“
-
Sort by: “timestamp” desc
-
Limit: 1
Note that we need to add an index in descending sort order to the timestamp field in our domstream collection. This allows for faster sort when retrieving the latest timestamp. Run the following command in mongo shell:
db.domstream.ensureIndex({timestamp: -1})(You can also replicate the data from the oplog rather than from the actual domstream collection, and make use of opTime. This saves you from indexing the timestamp field in domstream. More on this in a future blogpost.)
tMap_1
Transform the timestamp value to a key/value pair (out_file) and job context (out_context). Double click on the tMap_1 icon and configure the output mapping as below:
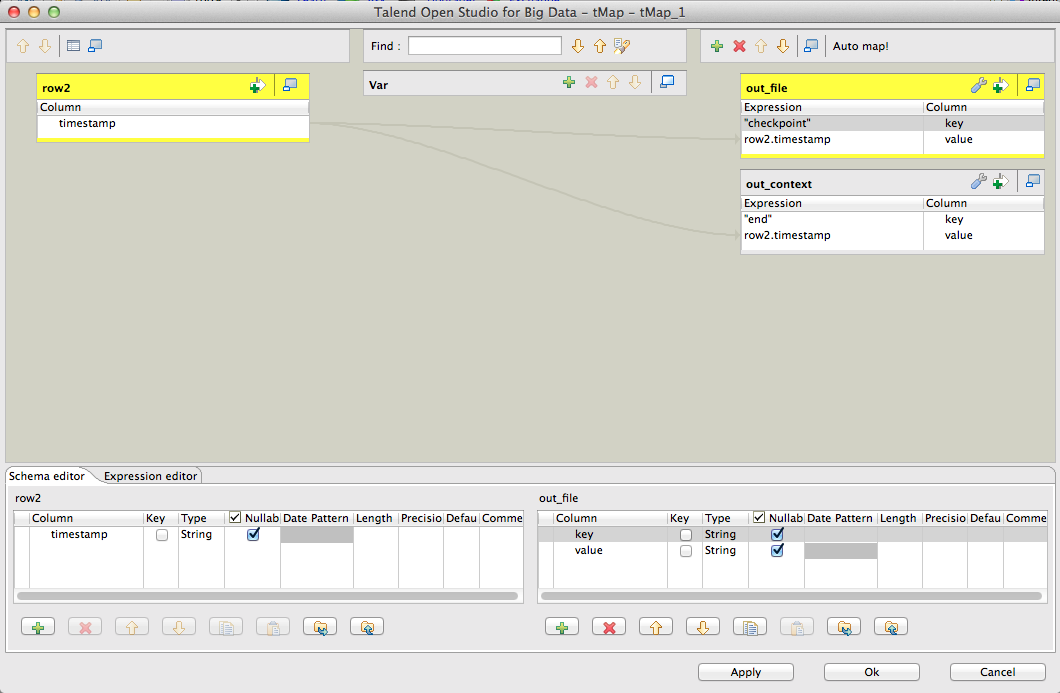
From the single timestamp value retrieved from tMongoDBInput_2 component, we tell Talend to transform the value as below:
out_file:
- key=checkpoint
- value=timestamp
out_context:
- key=end
- value=timestamp
tFileOutputDelimited_1
Export a key/value pair as a delimited output to a file (checkpoint.txt). This will actually import the incoming key/value pair from tMap_1 component and write to checkpoint.txt in the following format:
checkpoint;[timestamp value]Specify the component option as below:
-
File Name: delete the default value and press Ctrl + Spacebar on keyboard. Choose “tFileList_1.CURRENT_FILEPATH”. The generated value would be:
((String)globalMap.get("tFileList_1_CURRENT_FILEPATH")) -
Field Separator: “;”
-
Click Sync Columns
tContextLoad_2
Export a key/value pair as a job context. This component exports the incoming data from tMap and sets the key/value pair of context.end to the timestamp value. We should now have two contexts used by our job:
- context.checkpoint (set by tContextLoad_1)
- context.end (set by tContextLoad_2)
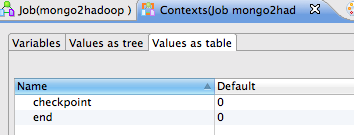
Next, we need to define both contexts and assign a default value. Go to Contexts(Job mongo2hadoop) tab and add ‘end’ and ‘checkpoint’ with default value 0, similar to the following screenshot:
Read Data and Load to HDFS
The last subjob is to read the relevant data from the MongoDB collection (read all documents with a timestamp value between context.checkpoint and context.end) and load it to Hadoop as an HDFS output file.
Add tMongoDBInput and tHDFSOutput into the Designer workspace. Map them together with other components as per below:
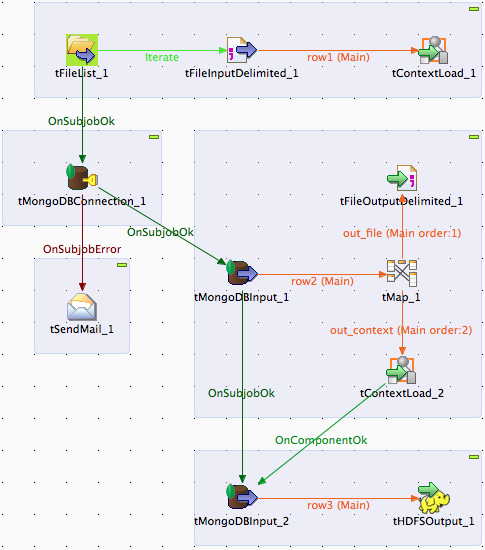
tMongoDBInput_2
Under the Component tab, check Use existing connection and choose tMongoDBConnection_1 from the drop down list, specify the collection name and click Edit schema. This will open a new window where you can define all columns/fields of your collection.
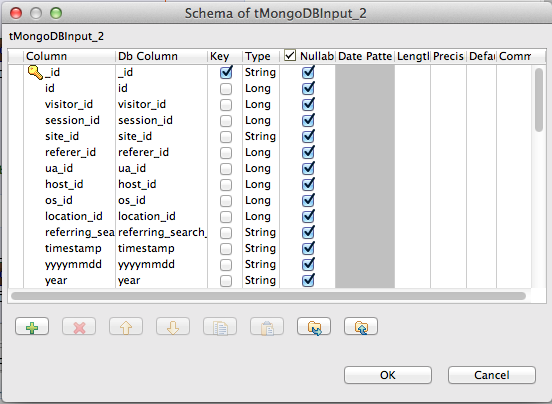
We are going to define all fields (use the ‘+’ button to add field) from our collection. Click OK once done. Specify the find expression in the Query text field. Since we are going to read between context.checkpoint and context.end, the following expression should be sufficient:
"{timestamp: {$gte: "+context.checkpoint+", $lt: "+context.end+"}}"tHDFSOutput_1
Click Sync columns to sync columns between the MongoDB input and the Hadoop output. You can click Edit schema button to double check the input/output data mapping, similar to the screenshot below:
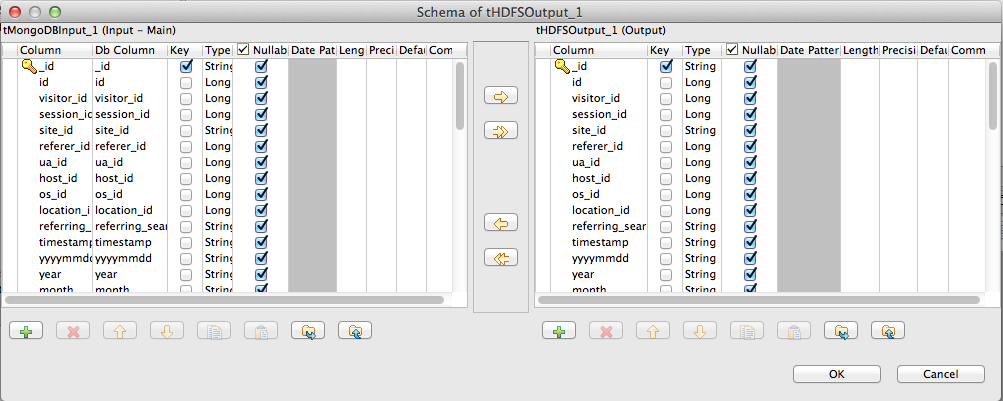
Specify the HDFS credentials and options on the Component tab:
- Distribution: HortonWorks
- Hadoop version: Hortonworks Data Platform V2.1(Baikal)
- NameNode URI: “hdfs://hadoop1.cluster.com:8020”
- User name: “hdfs”
- File Name: “/user/hdfs/from_mongodb.csv”
- Type: Text File
- Action: Append
- Check Include Header
HortonWorks NameNode URI listens on port 8020. Specify the default user “hdfs” and you can test the connection to Hadoop by attempting to browse the file path (click on the ‘…’ button next to File Name).
Test the Job
The job is expecting to append output to an existing file called /user/hdfs/from_mongodb.csv. We need to create this file in HDFS:
$ su - hdfs
$ hdfs dfs -touchz /user/hdfs/from_mongodb.csvThe design part is now complete. Let’s run the Job to test that everything is working as expected. Go to the Run (mongo2hadoop) tab and click on Run button:
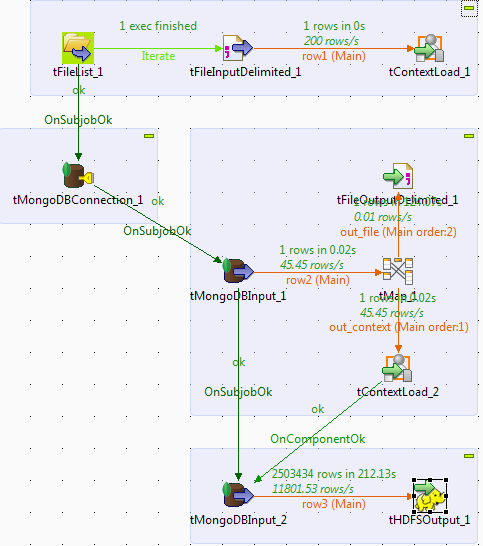
Examine the debug output and verify that the data exists in the HDFS output file:
$ su - hdfs
$ hdfs dfs -cat /user/hdfs/from_mongodb.csv | wc -l
2503435The domstream collection contains 2503434 documents, while the transferred data in HDFS has 2503435 lines (with an extra line for header, so the value is correct). Try it a couple of times and make sure that only new inserted documents are appended to the HDFS output file.
Job Deployment and Scheduling
Once you are happy with the ETL process, we can export the job as a Unix Shell Script or Windows Batch File and let it run in our production environment. In this case, the exported job will be scheduled to run on the MongoDB server every 5 minutes.
Right click on the mongo2hadoop job in Repository tab and click Build Job. Choose the Shell Launcher to Unix and click Finish:
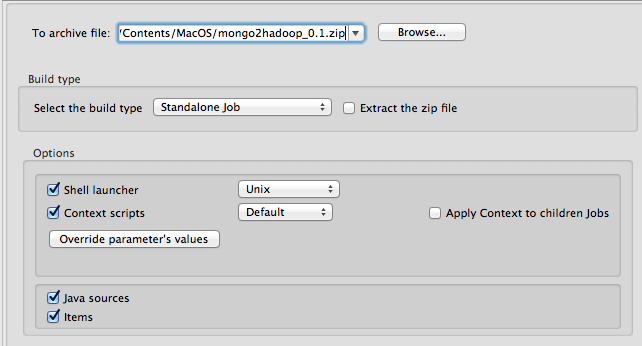
The standalone job package requires Java to be installed on the running system. Install Java and unzip on the MongoDB server using package manager:
$ yum install -y java-1.7.0-openjdk unzip # Redhat/CentOS
$ sudo apt-get install openjdk-7-jre # Debian/Ubuntu*Note: You can use official JDK from Oracle instead of OpenJDK release, please refer to the Oracle documentation.
Copy the package from your local workstation to the MongoDB server and extract it:
$ mkdir -p /root/scripts
$ unzip mongo2hadoop_0.1.zip -d /root/scriptsEdit the cron definition:
$ crontab -eConfigure the cron to execute the command every 5 minutes by adding following line:
0 */5 * * * /bin/sh /root/scripts/mongo2hadoop/mongo2hadoop_run.shReload cron to apply the change:
$ service crond reload # Redhat/CentOS
$ sudo service cron restart # Debian/UbuntuOur data integration process is now complete. We should see data in an HDFS output file which has been exported from MongoDB, new data will be appended every 5 minutes. Analysis can then be performed on this “semi-live” data that is 5 minutes old. It is possible to run the jobs during shorter intervals, e.g. every 1 minute, in case you want to perform analysis of behavioural data and use the resulting insight in the application, while the user is still logged in.



