blog
An Overview of MySQL Database Indexing

An index is a data structure that sorts a number of records on one or more fields, and speeds up data retrieval. This is to avoid scanning through the disk blocks that a table spans, when searching through the database. So, what kind of indexes are available in MySQL and how do we use them to get the most performance? This will be the topic for this blog.
![]()
This is the twelfth installment in the ‘Become a MySQL DBA’ blog series. Our previous posts in the DBA series include Deep Dive pt-query-digest, Analyzing SQL Workload with pt-query-digest, Query Tuning Process, Configuration Tuning, Live Migration using MySQL Replication, Database Upgrades, Replication Topology Changes, Schema Changes, High Availability, Backup & Restore, Monitoring & Trending.
A little bit of theory
MySQL allows for different types of indexes to be used. Most common is a B-Tree index, although this name is also used for other types of indexes: T-Tree in MySQL Cluster and B+Tree in InnoDB. This is the index type you’ll be working the most with, therefore we’ll cover it in some detail. Other types are full text index designed to handle text search in MyISAM and InnoDB. We have also spatial index based on R-Tree design, which is meant to help in spatial data (geometric data) lookups. It is available in MyISAM only, for now – starting from MySQL 5.7.5, spatial indexes can also be created for InnoDB tables – this will eliminate yet another reason for keeping MyISAM in your database. Last but not least, we have hash indexes used in MEMORY engine. They are designed to handle equality comparisons and cannot be used for range searches. They are (usually) much faster than B-Tree indexes, though. MEMORY engine supports B-Tree indexes too.
B-Tree index
Let’s look at how a B-Tree index is designed.
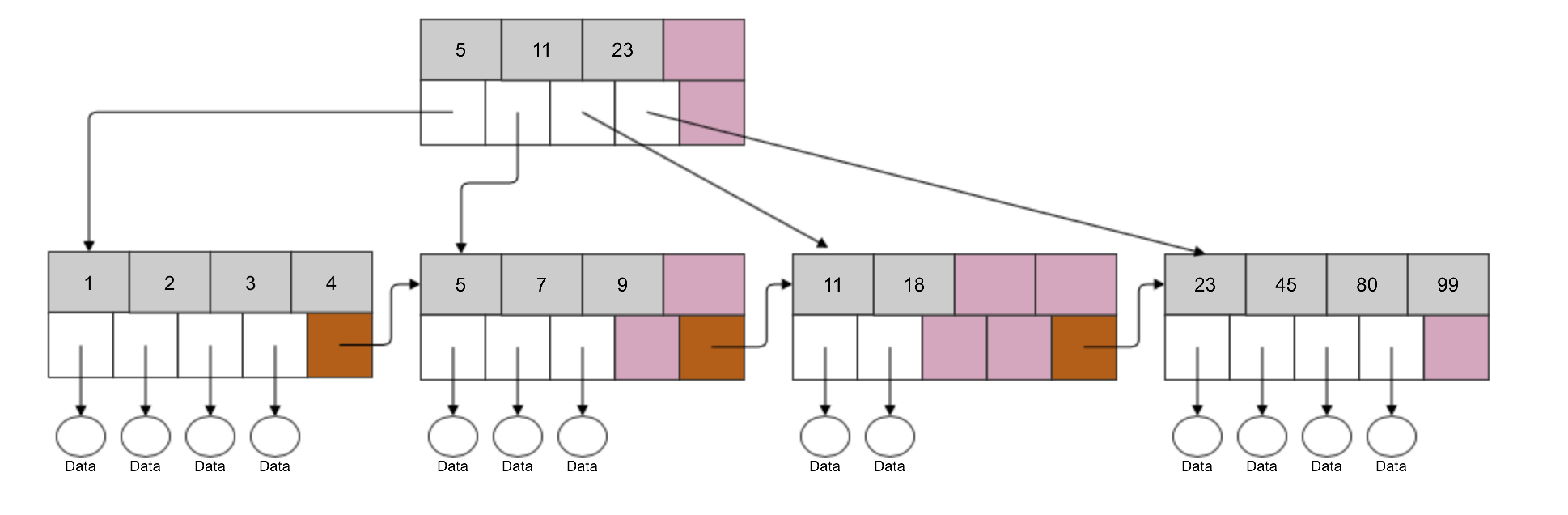
In the diagram above, we have a root node and four leaf nodes. Each entry in a leaf node has a pointer to a row related to this index entry. Leaf nodes are also connected together – each leaf node has a pointer to the beginning of another leaf node (brown square) – this allows for a quick range scan of the index. Index lookup is also pretty efficient. Let’s say we want to find data for entry ‘9’. Instead of scanning the whole table, we can use an index. A quick check in the root node and it’s clear we need to go to a leaf node which covers entries 5<= x < 11. So, we go to the second leaf node and we have the entry for ‘9’.
In the presented example, some of the nodes are not full yet. If we’d insert a row with indexed value of, let’s say 20, it can be inserted into the empty space in the third leaf node.
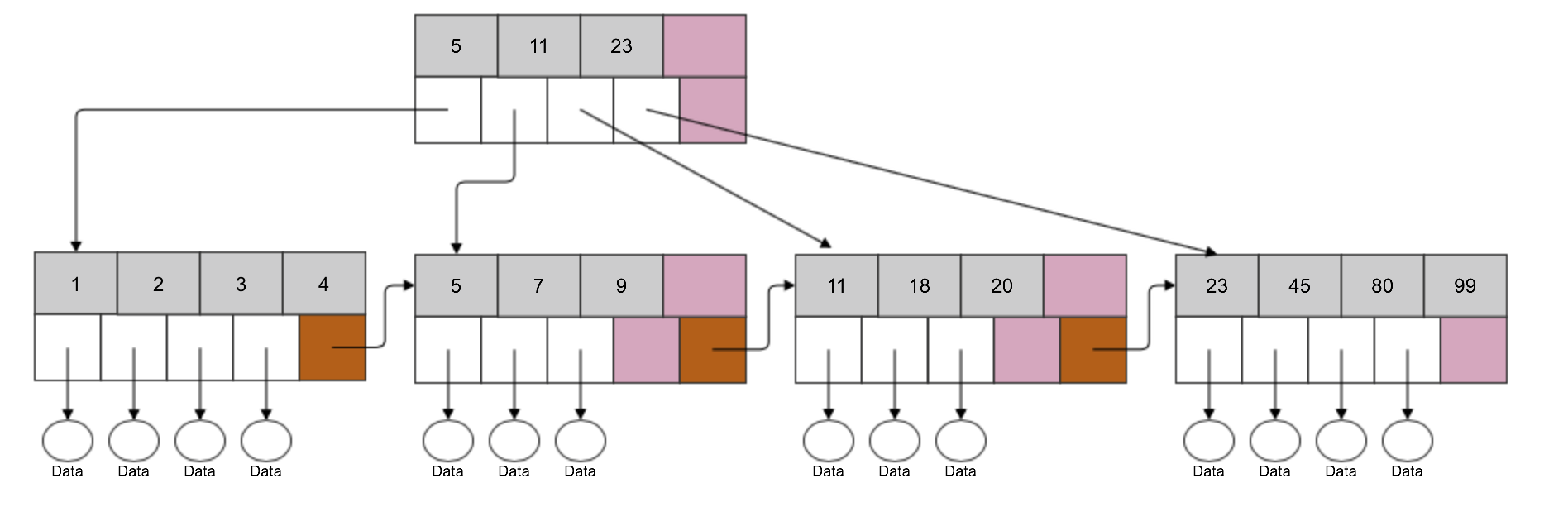
But what about a row with indexed value of ‘50’? Things are going to be a bit more complex as we do not have enough space in the fourth leaf node. It has to be split.
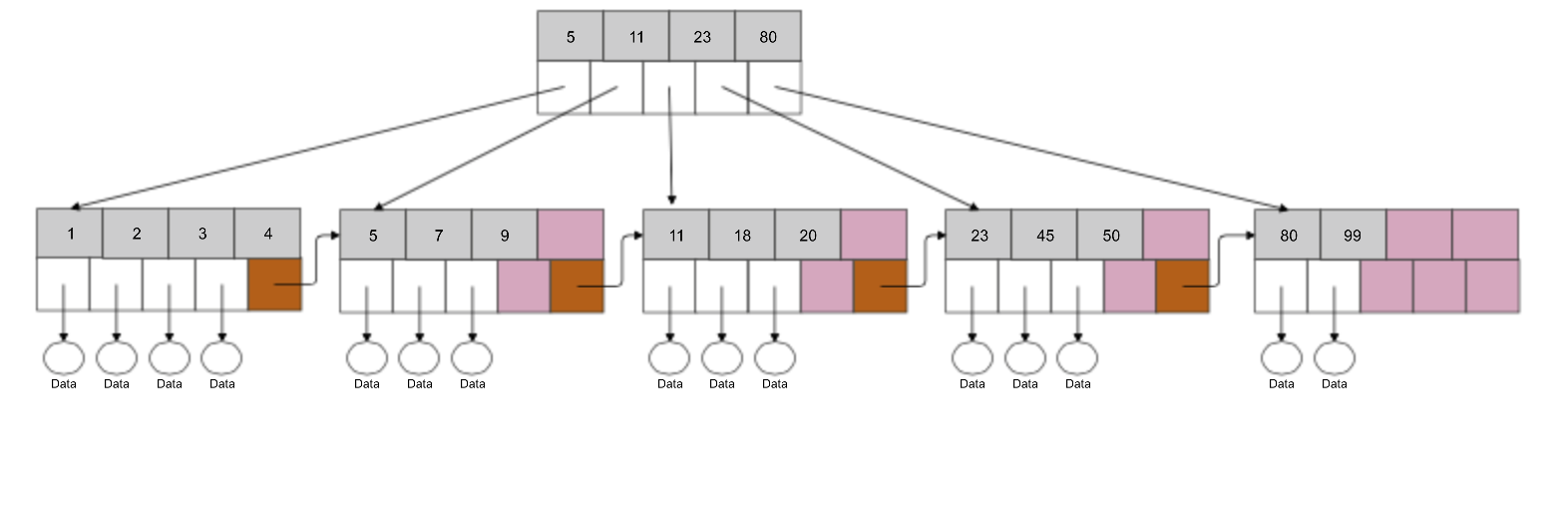
So, it wasn’t just a single write, i.e., adding an entry to a leaf node. Instead, a couple of additional write operations have to be performed. Please bear in mind that we are still on two levels of a B-Tree index, we have a full root node though. Another split will require adding an additional level of nodes which leads to more write operations. As you may have noticed, indexes make write operations much more expensive than they normally are – a lot of additional work goes into managing indexes. This is very important concept to keep in mind – more indexes is not always better as you are trading quicker selects for slower inserts.
InnoDB vs. MyISAM – differences
Before we discuss different query types, we need to cover some additional basics. We have two index types: primary index and secondary index. Primary index is always unique. Secondary index may or may not be unique. Below you can find definitions for those types of index.
PRIMARY KEY (`rental_id`)
UNIQUE KEY `rental_date` (`rental_date`,`inventory_id`,`customer_id`)
KEY `idx_fk_inventory_id` (`inventory_id`)How they work internally differs between MyISAM and InnoDB, therefore it’s important to understand what those differences are. In MyISAM things are simple – all of the indexes in their leaf pages contain pointers to rows. There’s not really much of a difference between PRIMARY KEY and UNIQUE KEY. Also, a regular index is structured in the same way as the primary index, only it’s not unique. Each lookup in the index, primary or secondary, points you to the data.
InnoDB is different – it uses clustered PRIMARY KEY. Each InnoDB table has it’s own PK defined – if you haven’t added an explicit PRIMARY KEY, one of the UNIQUE KEYs will be used. If there are no PK nor unique indexes, a hidden PK will be created.
Such primary index’s leaf pages contain all of the data for a given row. This has significant impact on the performance – if you access data through a primary key, there’s no need for any additional data lookup – all of the data you need can be found in the primary key’s leaf pages. On the other hand, secondary indexes, instead of storing a pointer to the data, store the primary key value. Data covered by leaf pages of a key is defined as:
KEY `idx_fk_inventory_id` (`inventory_id`)is closer to the following definition:
KEY `idx_fk_inventory_id` (`inventory_id`, `rental_id`)where rental_id is a PK column. This means that every secondary index lookup in InnoDB requires an additional PK lookup to get the actual data. It also means that the longer the PRIMARY KEY is (if you use multiple columns in it or maybe a long VARCHAR column), the longer secondary indexes are. This is not ideal for performance.
Indexes – what queries they can speed up
Now, let’s look at the most popular indexes that can be created in MySQL. We’ll give some examples to help you understand how indexing works in practice.
B-Tree indexes
B-Tree indexes can be used for a large variety of queries. They can speed up queries which match a full value. Let’s take a look at the ‘rental’ table in the ‘Sakila’ sample database:
*************************** 1. row ***************************
Table: rental
Create Table: CREATE TABLE `rental` (
`rental_id` int(11) NOT NULL AUTO_INCREMENT,
`rental_date` datetime NOT NULL,
`inventory_id` mediumint(8) unsigned NOT NULL,
`customer_id` smallint(5) unsigned NOT NULL,
`return_date` datetime DEFAULT NULL,
`staff_id` tinyint(3) unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`rental_id`),
UNIQUE KEY `rental_date` (`rental_date`,`inventory_id`,`customer_id`),
KEY `idx_fk_inventory_id` (`inventory_id`),
KEY `idx_fk_customer_id` (`customer_id`),
KEY `idx_fk_staff_id` (`staff_id`),
CONSTRAINT `fk_rental_customer` FOREIGN KEY (`customer_id`) REFERENCES `customer` (`customer_id`) ON UPDATE CASCADE,
CONSTRAINT `fk_rental_inventory` FOREIGN KEY (`inventory_id`) REFERENCES `inventory` (`inventory_id`) ON UPDATE CASCADE,
CONSTRAINT `fk_rental_staff` FOREIGN KEY (`staff_id`) REFERENCES `staff` (`staff_id`) ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=16050 DEFAULT CHARSET=utf8Key ‘idx_fk_customer_id’ can be used for queries like:
SELECT * FROM rental WHERE customer_id = 1;As you may have noticed, we can have keys covering single column or multiple columns – such index is called ‘composite index’. ‘rental_date’ is an example of a composite index. It can be used by queries with matching leftmost prefix. Queries like:
SELECT * FROM rental WHERE rental_date = '2015-01-01 22:53:30' AND inventory_id=4;Please note we didn’t use all the columns that this index covers – just a leftmost prefix of two columns.
Indexes can also work with leftmost prefix of a column. Let’s say we want to look for titles which start with letter ‘L’. Here’s a table we’ll be querying – please note we’re going to use the index ‘idx_title’.
*************************** 1. row ***************************
Table: film
Create Table: CREATE TABLE `film` (
`film_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`description` text,
`release_year` year(4) DEFAULT NULL,
`language_id` tinyint(3) unsigned NOT NULL,
`original_language_id` tinyint(3) unsigned DEFAULT NULL,
`rental_duration` tinyint(3) unsigned NOT NULL DEFAULT '3',
`rental_rate` decimal(4,2) NOT NULL DEFAULT '4.99',
`length` smallint(5) unsigned DEFAULT NULL,
`replacement_cost` decimal(5,2) NOT NULL DEFAULT '19.99',
`rating` enum('G','PG','PG-13','R','NC-17') DEFAULT 'G',
`special_features` set('Trailers','Commentaries','Deleted Scenes','Behind the Scenes') DEFAULT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`film_id`),
KEY `idx_title` (`title`),
KEY `idx_fk_language_id` (`language_id`),
KEY `idx_fk_original_language_id` (`original_language_id`),
CONSTRAINT `fk_film_language` FOREIGN KEY (`language_id`) REFERENCES `language` (`language_id`) ON UPDATE CASCADE,
CONSTRAINT `fk_film_language_original` FOREIGN KEY (`original_language_id`) REFERENCES `language` (`language_id`) ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)Here’s the query:
SELECT * FROM film WHERE title like 'L%';Another type of query which can benefit from a B-Tree index is range queries. Let’s say we want to look for films with titles in a range of L – M. We can write a query:
SELECT * FROM film WHERE title > 'L%' AND title < 'N%'Gand it will use the index on ‘title’ column.
Leaf nodes in a B-Tree index contain pointers to the rows but they also contain the data for the indexed column itself. This makes it possible to build covering indexes – indexes which will remove the need for additional lookup to the tablespace.
Let’s say we want to run the following query against the ‘rental’ table:
SELECT inventory_id, customer_id FROM rental WHERE rental_date='2005-05-24 22:53:30'GPlease keep in mind the definition of the index we’ll be using:
UNIQUE KEY `rental_date` (`rental_date`,`inventory_id`,`customer_id`),Therefore each leaf page will contain data for ‘rental_date’, ‘inventory_id’ and ‘customer_id’ columns. Our query asks only for data which is available in the index page therefore it’s not needed to perform any further lookup. This is especially important given how InnoDB handles secondary indexes – if a query is covered by a secondary index, no additional PK lookup is needed.
B-Tree indexes have also some limitations. For starters, a query has to use the leftmost prefix of the index. We can’t use the ‘rental_date’ key to look only for `inventory_id` and `customer_id` columns. You cannot use it to look for ‘rental_date’ and ‘customer_id’ columns either – they do not form a continuous prefix. The index will be used only for ‘rental_date’ condition.
FULLTEXT Indexes
This is a type of index that can be used for text lookups – they do not work by comparing values, it’s more like a keyword searching. We will not go into details here, what’s important is that FULLTEXT indexes are (since MySQL 5.6) available in InnoDB (and in MyISAM, as it used to be) and can’t be used for WHERE conditions – you should be using the MATCH AGAINST operator. You can have both B-Tree and FULLTEXT index on the same column, sometimes there are reasons to do that.
HASH Indexes
Hash indexes (user controlled) are used only in MEMORY engine and can be used for exact lookups. For each column a hash is calculated and then it’s used for lookups. Let’s say that a hash for value ‘mylongstring’ is ‘1234’. MySQL will store a hash value along with a pointer to the row. If you execute query like:
SELECT * FROM table WHERE my_indexed_column = 'mylongstring';The WHERE condition will be hashed and as result will be ‘1234’, the index will point to the correct row. Main advantage of HASH index is the fact that hashes can be much smaller than the indexed value itself. Main problem, though, is that this index type can’t be used to anything else than a simple lookup. You cannot use index on (column1, column2) to cover query with only ‘column1’ in the WHERE clause. Hashes are not unique – collisions can happen and they will slow down the lookup as MySQL will have to check more than a single row per index lookup.
We mentioned that MEMORY engine use ‘user controlled’ hash indexes – this is because InnoDB can use hash indexes too. For the most frequently queried data InnoDB builds an internal hash index on top of the B-Tree indexes. This allows for quicker lookups in some cases. This mechanism is called ‘Adaptive Hash Index’ and is an internal, not user-configurable feature. Historically, under some workloads, it was a point of contention. Right now, in MySQL 5.6, we can either disable it completely or we can manage how many ‘partitions’ this index will have. The user cannot control what kind of data InnoDB is going to index in this way, though.
Indexing gotchas
Functions
Let’s look at some of the most known issues regarding indexing.
SELECT column1 FROM table WHERE LOWER(column2) = 'some value';or the example from the Sakila database:
SELECT * FROM film WHERE LOWER(title)='academy dinosaur';This query cannot use an index on the ‘title’ column. It’s because we have a function that does something with the column. In such case, MySQL cannot perform an index lookup and, as a result, it has to perform a table scan. We can see it in the EXPLAIN output (we’ll cover EXPLAIN in our next blog in the DBA series):
mysql> EXPLAIN select * from film where LOWER(title)='academy dinosaur'G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1000
Extra: Using where
1 row in set (0.00 sec)As you can see, keys: NULL and possible_keys: NULL indicate that the MySQL optimizer did not find a suitable index for this query.
Let’s try another example:
mysql> EXPLAIN SELECT * FROM film WHERE title=UPPER('academy dinosaur')G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
type: ref
possible_keys: idx_title
key: idx_title
key_len: 767
ref: const
rows: 1
Extra: Using index condition
1 row in set (0.00 sec)In this case, an index was used because the function has been used on the right side of the condition. As expected, idx_title was chosen for this query.
Different column types
MySQL may have problems in comparing different types of data and you need to be precise sometimes about what kind of data you are using in the query.
Let’s check another query in the film table:
mysql> EXPLAIN SELECT * FROM film WHERE title=12345G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
type: ALL
possible_keys: idx_title
key: NULL
key_len: NULL
ref: NULL
rows: 1000
Extra: Using where
1 row in set (0.00 sec)As you can see, it’s doing a full table scan. This happened because we’re comparing VARCHAR column to the integer (12345). If we convert integer to string, an index will be used:
mysql> EXPLAIN SELECT * FROM film WHERE title='12345'G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
type: ref
possible_keys: idx_title
key: idx_title
key_len: 767
ref: const
rows: 1
Extra: Using index condition
1 row in set (0.00 sec)Missing quotes may result in a heavy, not optimal query.
This was a brief introduction into how indexes work in MySQL. In the next post we are going to cover EXPLAIN – an important tool in dealing with query performance issues.



