blog
Common Database Management Operations – Schema Changes

Database schema changes are not popular among DBAs, not when you are operating production databases and cannot afford to switch off the service during a maintenance window. These are unfortunately frequent and necessary, especially when introducing new features to existing applications.
Schema changes can be performed in different ways, with tradeoffs such as complexity versus performance or availability. For instance, some methods would trigger a full table rewrite which could lead to high server load. This in turn would lead to degraded performance and increased replication lag in master-slave replication setups.
This is the fourth installment in the ‘Become a MySQL DBA’ series, and discusses the different approaches to schema changes in MySQL. Our previous posts in the DBA series include High Availability, Backup & Restore and Monitoring & Trending.
Schema Changes in MySQL
A common obstacle when introducing new features to your application is making a MySQL schema change in production, in the form of additional columns or indexes. Traditionally, a schema change in MySQL was a blocking operation – a table had to be locked for the duration of the ALTER. This is unacceptable for many applications – you can’t just stop receiving writes as this causes your application to become unresponsive. In general, “maintenance breaks” are not popular – databases have to be up and running most of the time. The good news is that there are ways to make this an online process.
Rolling Schema Update in MySQL Replication Setups
MySQL replication is an easy way of setting up high availability, but managing schema updates are tricky. Some ALTERs may lock writes on the master and create replication lag – this is obvious for any ALTER statement. The reason is simple – MySQL replication is single-threaded and if the SQL thread is executing an ALTER statement, it won’t execute anything else. It is also important to understand that the slave is able to start replicating the schema change only after it has completed on the master. This results in a significant amount of time needed to complete changes on the slave: time needed for a change on the master + time needed for a change on the slave.
All of this sounds bad but replication can be used to help a DBA manage some of the schema changes. The plan is simple – take one of the slaves out of rotation, execute ALTERs, bring it back, rinse and repeat until all slaves have been updated. Once that’s done, promote one of the slaves to master, run ALTER on the old master, bring it back as a slave.
This is a simple yet efficient way of implementing schema changes. Failover requires some downtime but it is much less impacting than running all of the changes through the replication chain, starting from the master. The main limitation of this method is that the new schema has to be compatible with the current schema – remember, master (where all writes happen) has it unchanged until almost the end. This is a significant limitation, especially if you use row-based binary log format. While statement-based replication (SBR) is pretty flexible, row-based replication (RBR) is much more demanding when it comes to the schema consistency. For example, adding a new column in any place other than the end of the table won’t work in RBR. With SBR, it is not an issue. Be sure you checked the documentation and verified that your schema change is compatible. Last but not least, if you use mixed binlog format, keep in mind that while it uses mostly statement-based binlog format, it will use row-based binlog format for those queries which are not deterministic. Thus, it may cause similar problems as RBR.
MySQL-based Functionality for Online Schema Change
As we mentioned earlier, some of the operations may not be blocking in MySQL and thus can be executed on a live system. It is true especially with MySQL 5.6, which brought a number of improvements in this area. Unfortunately, it doesn’t solve problems with replication lag – ALTERs will still cause this type of problem. Still, this is a great choice for smaller tables where lag created is acceptable. Of course, it is application-dependent but usually it’s not a big deal if the slave lag is a couple of seconds and this may mean that tables even up to a couple of gigabytes (hardware-dependent) may be within range. If your application cannot accept even such small lag, then we’d strongly suggest to rethink about the design. Slaves will lag, it is just a matter of when it will happen.
Other Tools for Online Schema Change
There are a couple of tools that perform online schema change in MySQL. The best known is probably pt-online-schema-change, which is part of Percona Toolkit. Another one is “Online Schema Change” developed by Facebook.
- Those tools work in a similar way
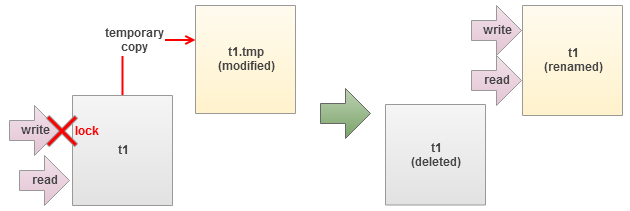
- create a new table with the desired schema;
- create triggers on the old table that will mirror all changes and store them in the new table;
- copy data from old table into a new one in batches;
- once it’s done, rename tables and drop the old one.
Those tools give the DBA great flexibility – you don’t have to do a time-consuming rolling upgrade, it’s enough to run pt-online-schema-change and it will take care of your ALTER. It’s even replication-aware and, as such, it can throttle itself down when a lag is detected on one of the slaves. It’s not without limitations, though.
You need to be aware that the “copy” operation is basically a number of low priority inserts. They will impact the overall performance – it’s inevitable. The process of moving millions of rows takes time – online schema change is much slower than the direct ALTER executed on the same table. By “much” we mean even an order of magnitude. Of course, it all depends on your hardware (disk throughput is the most important factor) and table schema, but it is not uncommon to see changes which literally take days to finish. Another limitation is the fact that this tool cannot be used on a table where triggers already exist. For now MySQL allows only a single trigger of a given type per table. This will probably change in MySQL 5.7 (the relevant worklog is marked as completed) but it doesn’t help much if you run on MySQL 5.6.
Another problem is with foreign keys – they are linked to a given table and if you create a new one and then swap it with the old table, foreign keys will have to be updated to point to the new table. Pt-online-schema-change gives you two options to deal with it but, frankly, none of them is good.
The first option, fast but risky, is to drop the old table instead of renaming it. The main problem here is two-fold – first, for a while there’s no table – renaming a table is an atomic operation, dropping it is not. Second, as the old table has been dropped, there’s no rollback if an error occurs after the drop.
The second option requires executing ALTERs on the tables linked by foreign keys – those tables are basically altered and new FKs are created. This is fine as long as those tables are small because the change is executed as a normal ALTER with all it’s consequences (replication lag, for example).
Metadata locking is another problem that you may experience while using pt-online-schema-change. Pt-osc have to create triggers and this operation requires a metadata lock. On a busy server with plenty of long-running transactions, this could be hard to acquire. It is possible to increase timeouts and, in that way, increase chances of acquiring the lock. But we’ve seen servers where it’s virtually impossible to run pt-online-schema-change due to this problem.
Given this long list of the problems and limitations, you might think that this tool is not worth your time. Well, on the contrary. The list is so long because almost every MySQL DBA will rely on pt-online-schema-change heavily and, in the process, will learn all of it’s dark sides. This tool is one of the most useful tools in the DBA’s toolkit. Even though it has some limitations, it gives you great degree of flexibility regarding how to approach schema changes in MySQL.
Schema Changes in Galera Cluster
Galera cluster brings another layer of complexity when it comes to schema changes. As it is a ‘virtually’ synchronous cluster, having a consistent schema is even more important than regular MySQL connected via replication. Galera brings two methods of running schema changes and we’ll discuss them and the repercussions of using them below.
TOI (Total Order Isolation)
The default one, TOI – Total Order Isolation, works in a way that the change happens at exactly the same time on all of the nodes in the cluster. This is great for consistency and allows you to run any kind of change, even non-compatible ones. But it comes with a huge cost – all other writes have to wait until the ALTER finishes. This, of course, make long-running ALTERs not feasible to execute because every one of them will cause significant downtime for the whole application. This mode can be used successfully for quick, small changes which do not take more than a second (unless you are ok with some ‘stalls’ in your application or you have a maintenance window defined for such changes).
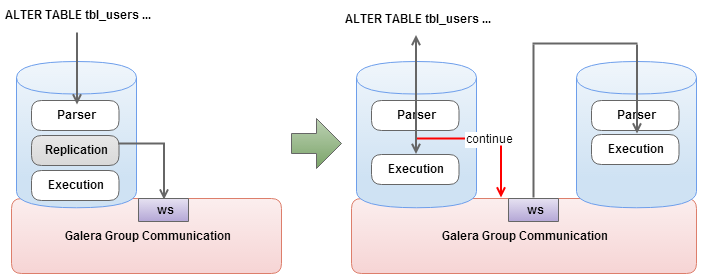
What is also important is that MySQL’s online ALTERs do not help here. Even a change, which you could easily run on the master without blocking it (and only be concerned about slaves lagging) will cause all writes to halt.
RSU (Rolling Schema Upgrade)
The second option that Galera offers is RSU – Rolling Schema Upgrade. This is somewhat similar to the option we discussed above, (see section on Rolling Schema Update in MySQL Replication setups). At that time we were pulling out our slaves, one by one, and finally we executed a master change. Here we’ll be taking the Galera nodes out of rotation.
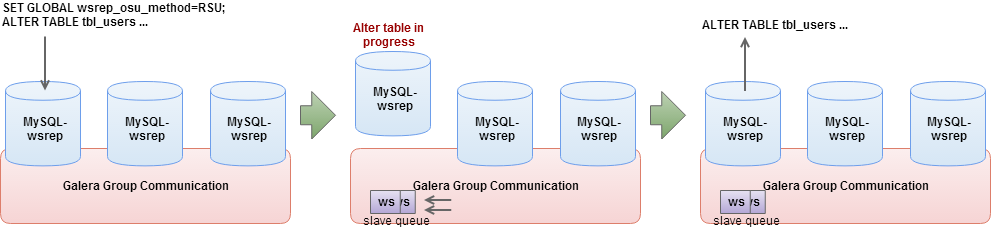
The whole process is partially automated – set the wsrep_OSU_method variable to RSU, and all you need to do is to proceed with the ALTER. The node will switch to the Desync state and flow control will be disabled ensuring that the ALTER will not affect the rest of the cluster. If your proxy layer is setup in a way that Desync state means no traffic will reach this node (and that’s how you should set up your proxy), such operation is transparent to the application. Once the ALTER finishes, the node is brought back to sync with the cluster.
This has several repercussions that you need to keep in mind. First of all, similar to the rolling schema upgrade on MySQL replication, changes have to be compatible with the old schema. As Galera uses row-based format for replication, it is very strict regarding changes that can be done online. You should verify every change you plan to make (see MySQL documentation) to ensure it is indeed compatible. If you performed an incompatible schema change, Galera won’t be able to apply writesets and it will complain about a node not being consistent with the rest of the cluster. This will result in Galera wiping out the offending node and executing SST.
You also need be aware of the fact that, for the duration of the change, the altered node does not process writesets. It will ask for them later, once it finishes the ALTER process. If it won’t find the writesets on any of the other synced nodes in the cluster, it will execute SST, removing the change completely. You have to ensure that gcache is large enough to store the data for the duration of the ALTER. It can be tricky and problematic as gcache size is only one of the factors – another one is the workload. You may have increased gcache but if the amount (and size) of the writesets in a given time increases too, you may still run out of space in the cache.
Generic Scenarios of the Schema Change
Now, let’s look at some real life scenarios and how you could approach them. We hope this will make more clear the strong and weak points of each method. Please note that we are adding estimated time to each of these scenarios. It is critical that the DBA, before executing a change, has knowledge about the time needed to complete it. We cannot stress it enough – you have to know what you’ll be executing and how long will it take.
There are a couple of ways in which you can estimate the performance. First, you can (and you should) have a development environment with a copy of your production data. This data should be as close to the real production copy as possible in terms of the size. Sure, sometimes you have to scrub it for security reasons, but still – closer to production means better estimates. If you have such environment, you can execute a change and assess the performance.
Another way, even more precise, is to run the change on a host that is connected to the production setup via replication. It is more precise because, for example, pt-online-schema-change execute numerous inserts and they can be slowed down because of the regular traffic. Having the regular traffic flown in via replication helps to make a good assessment.
Finally, it’s all about the experience of the DBA – knowledge about the system’s performance and workload patterns. From our experience we’d say that when in doubt, add 50% to the estimated time. In the best case, you’ll be happy. In the worst, you should be about right, maybe a bit over the ETA.
Scenario – Small Table, Alter Takes up to 10s
MySQL Replication
In this case it’s a matter of answering the question – does your application allow some lag? If yes, and if the change is non-blocking, you can run direct ALTER. On the other hand, pt-online-schema-change shouldn’t take more than couple of minutes on such a table and it won’t cause any lag-related issues. It’s up to you to decide which approach is better. Of course, if the change is blocking on the MySQL version you have installed, online schema change is the only option.
Galera Cluster
In this case, we’d say the only feasible way of executing the change is to use pt-online-schema-change. Obviously we don’t want to use TOI as we’d be locked for couple of seconds. We could use RSU if the change is compatible, but it creates additional overhead of running the change on a node, one by one, keeping an eye on their status, ensuring the proxy layer is taking nodes out of rotation. It’s doable but if we can use online schema change and just let it run, why not do that?
Scenario – Medium-sized Table, From 20 – 30 Minutes up to 1h
Replication and Galera Cluster
This is where pt-online-schema-change shines. Changes take too long for a direct ALTER to be feasible yet the table is not too big and pt-osc should be able to finish the process within several hours at the most. It may take a while but it will eventually be done. It’s also much less cumbersome than executing a rolling schema upgrade.
Scenario – Large Tables, More Than 1h, up to 6 -12h
MySQL Replication
Such tables can become tricky ones. On the one hand, pt-online-schema-change will work fine, but problems may start to appear. As pt-osc is expected to take even 36 – 48h to finish such change, you need to consider impact on the performance (because pt-osc has its impact, the inserts need to be executed). You also need to assess if you have enough disk space. This is somewhat true for most of the methods we described (except maybe for online ALTERs) but it’s even more true for pt-osc as inserts will significantly increase the size of the binary logs. Therefore you may want to try to use Rolling Schema Upgrade – downtime will be required but the overall impact may be lower than using pt-osc.
Galera Cluster
In Galera, the situation is somewhat similar. You can also use pt-online-schema-change if you are ok with some performance impact. You may also use RSU mode and execute changes node by node. Keep in mind that gcache size for 12hrs worth of writesets, on a busy cluster, may require a significant amount of memory. What you can do is to monitor wsrep_last_committed and wsrep_local_cached_downto counters to estimate how long the gcache is able to store data in your case.
Scenario – Very Large Tables, More Than 12h
First of all, why do you need such a large table? 🙂 Is it really required to have all this data in a single table? Maybe it’s possible to archive some of this data in a set of archive tables (one per year/month/week, depending on their size) and remove it from the “main” table?
If it’s not possible to decrease the size (or it’s too late as this process will take weeks while ALTER has to be executed now), you need to get creative. For MySQL Replication you’ll probably use rolling schema upgrade as a method of choice with a slight change, though. Instead of running the ALTER over and over again you may want to use xtrabackup or even snapshots, if you have LVM or run on EBS volumes in EC2, to propagate changes through the replication chain. It will be probably faster to run ALTER once and then rebuild slaves from scratch using the new data (rather than executing the ALTER on every host).
Galera Cluster may suffer from problems with gcache. If you can fit the 24h or even more data into gache, good for you – you can use RSU. If not, though, you will have to improvise. One way would be to take a backup of the cluster and use it to build a new Galera cluster which will be connected to the production one via replication. Once that is done, run the change on the ‘other’ cluster and, finally, failover to it.
As you can see, schema changes may become a serious problem to deal with. This is a good point to keep in mind that the schema design is very important in relational databases – once you push data into tables, things may become hard to change. Therefore you need to design table schemas as time-proof as possible (including indexing any access pattern that may be used by queries in the future). Also, before you start inserting data in your tables, you need to plan how to archive this data. Partitions maybe? Separate archive tables? As long as you can keep the tables reasonably small, you won’t have problems with adding a new index.
Of course, your mileage may vary – we used time as a main differentiating factor because an ALTER on a 10GB table may take minutes or hours. You also need to remember that pt-online-schema-change has its limitations – if a table has triggers, you may need to use rolling schema upgrade on it. Same with foreign keys. This is another question to answer while designing the schema – do you need triggers? Can it be done from within app? Are foreign keys required or can you have some consistency checks in the application? It is very likely that developers will push on using all those database features, and that’s perfectly understandable – they are there to be used. But you, as a DBA, will have to assess all of the pros and cons and help them decide whether the pros of using all those database features are larger than the cons of maintaining a database that is full of triggers and foreign keys. Schema changes will happen and eventually you’ll have to perform them. Not having an option to run pt-online-schema-change may significantly limit your possibilities.



