blog
How to Achieve High Availability with a DBaaS Provider

One of the responsibilities of a Cloud Provider who offers a DBaaS (Database as a Service) solution is to give you a way to achieve High Availability without using a different provider.
The main advantage of using this High Availability solution in the same Cloud Provider is that it is easy to use. Using the management console provided you just need to enable it, and the cloud provider is who makes the job. You don’t need to worry about the connectivity between different sites, install, or configure anything, all these things are part of the Cloud Provider solution (or should be).
There are different High Availability levels depending on the required RPO (Recovery Point Objective) and RTO (Recovery Time Objective), and of course, depending on the budget.
In this blog, we will mention some considerations to take into account to have a good High Availability solution, and we will show you an example using one of the most common Cloud Providers nowadays, AWS (Amazon Web Services).
Database High Availability Considerations
There are many things to take into account to make sure that you are using a good High Availability solution. Let’s see some of them.
Availability
You should make sure that your database will be available all the time (or almost), so you should be able to deploy it in different regions. In case of a critical failure, like a datacenter issue, you will be able to switch to another region to keep your systems working. Keep in mind that if you are using sync replication, the latency of having your databases running in different geographical regions could be a problem.
Failover
This is an important task in a High Availability environment. It could be manual or automatic, but it is a must to be able to keep your database running in a DRP (Disaster Recovery Plan) or even in a maintenance planned task. You can also add a Load Balancer here, to avoid any change in your application after performing a failover task.
Scaling
No matter what Cloud Provider you are using, you will need the option to scale your database topology in a horizontal or vertical way:
- Horizontal Scaling (scale-out): It is performed by adding more database nodes creating or increasing a database cluster.
- Vertical Scaling (scale-up): It is performed by adding more hardware resources (CPU, Memory, Disk) to an existing database node.
You can scale (out/up) manually if you are expecting or having more traffic for any reason, but also some Cloud Providers allow you to configure it in an automatic way. It means, you don’t need to worry about, for example, how much traffic you are receiving to know how many replicas you need to add, the Cloud Provider, depending on the product, will add it for you following rules that you create, and you just need to pay the bill every month.
Backup
This point is a must in any DRP, and of course, it is also a must in any Cloud Provider, to ensure an acceptable RPO and RTO.
In general, backups are enabled by default, and you should be able to configure when you want to run it, the retention period, and the encryption for these backups. In some cases, It could be possible to have the option to use PITR (Point In Time Recovery), to restore your database at any given moment in the past.
Monitoring and Alerting
Even with the best High Availability environment, you need to know when something goes wrong, and for this, is necessary to have a good monitoring and alerting system in place.
In general, all Cloud Providers have implemented this in a basic way, but it could be necessary to improve this by your own, creating a new system if it is not possible to adapt the existing one to your requirements.
AWS as a DBaaS Provider
Now, as an example, let’s see how we can achieve High Availability on AWS checking the important things that we mentioned above.
AWS Architecture
First, let’s talk about AWS Architecture. AWS has a global infrastructure to provide High Availability for cloud workloads. The key components of this architecture include:
- Regions: Many geographical zones each containing at least three availability zones.
- Availability zones: Many global zones, which are self-sufficient data centers with redundant power, networking, and cooling. Deploying across several AZs can protect your applications and provide you with resiliency in case failures occur.
- Compliance and data residency: Amazon provides full control over AWS regions to help you comply with data sovereignty requirements.
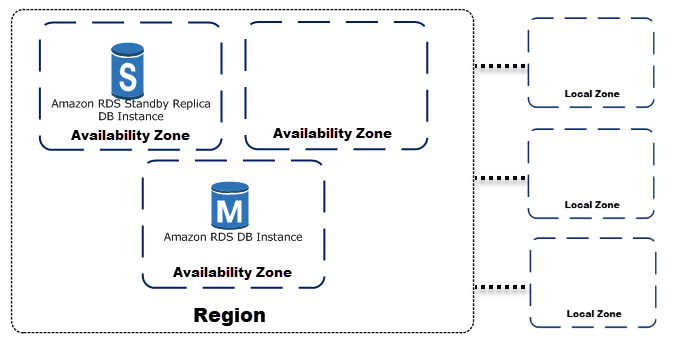
AWS Availability and Database Failover
Multi-AZ Deployment
During the deploy process (or you can even enable it later), AWS will ask you to create your database using Multi Availability Zone (Multi-AZ). This will create a standby node in a different Availability Zone (AZ) to provide data redundancy, eliminate I/O freezes, and minimize latency spikes during system backups. AWS will automatically fail over to the standby in the case of a planned or unplanned outage of the primary.
DB instances using Multi-AZ deployments can have increased write and commit latency compared to a Single-AZ deployment, due to the synchronous data replication that occurs.
This feature is not a scaling solution for read-only scenarios; you cannot use this kind of standby replica to serve read traffic, however, you can add many read replicas for this task.
It can also be enabled on an existing Single-AZ deployment. In this case, Amazon RDS takes a snapshot of your primary DB instance, restores it into another Availability Zone, and sets up synchronous replication between your primary DB instance and the new one. You won’t have downtime during this process, but your database performance could be affected.
Failover Process
In the event of a planned or unplanned outage of your DB instance, Amazon RDS automatically switches to a standby replica in another Availability Zone if you have enabled Multi-AZ, or even to a read replica if exists.
The primary DB instance switches over automatically to the standby replica if any of the following conditions occur:
- An Availability Zone outage
- The primary DB instance fails
- The DB instance’s server type is changed
- The operating system of the DB instance is undergoing software patching
- A manual failover of the DB instance was initiated using Reboot with failover
AWS DB Scaling
Using the AWS management console, you can manually add read replicas (scale-out) or even change your hardware configuration (scale-up) to improve your database environment.
In the case of storage, you can configure Auto Scaling, so the storage size will be modified if needed.

If you are using Amazon Aurora, you can also configure Auto Scaling to add read replicas following rules that you can manage from the “Logs and Events” section, in your database instance.
Database Backups
During the database deployment, or later in the instance configuration, you can enable automatic Backups, configure the retention and backup window.
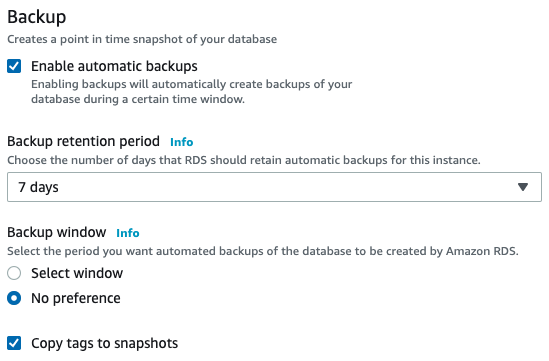
In case you need to take a manual backup, you can also do it from the AWS management console in the “Backup and Maintenance” instance section.
About restoring, you can restore your database to a point in time, or just select a snapshot and restore it in a separate instance.
Database Monitoring and Alerting
Having your database instance up and running, you can go to the “Monitoring” section and check some charts with different metrics, and compare these metrics between the different database nodes.
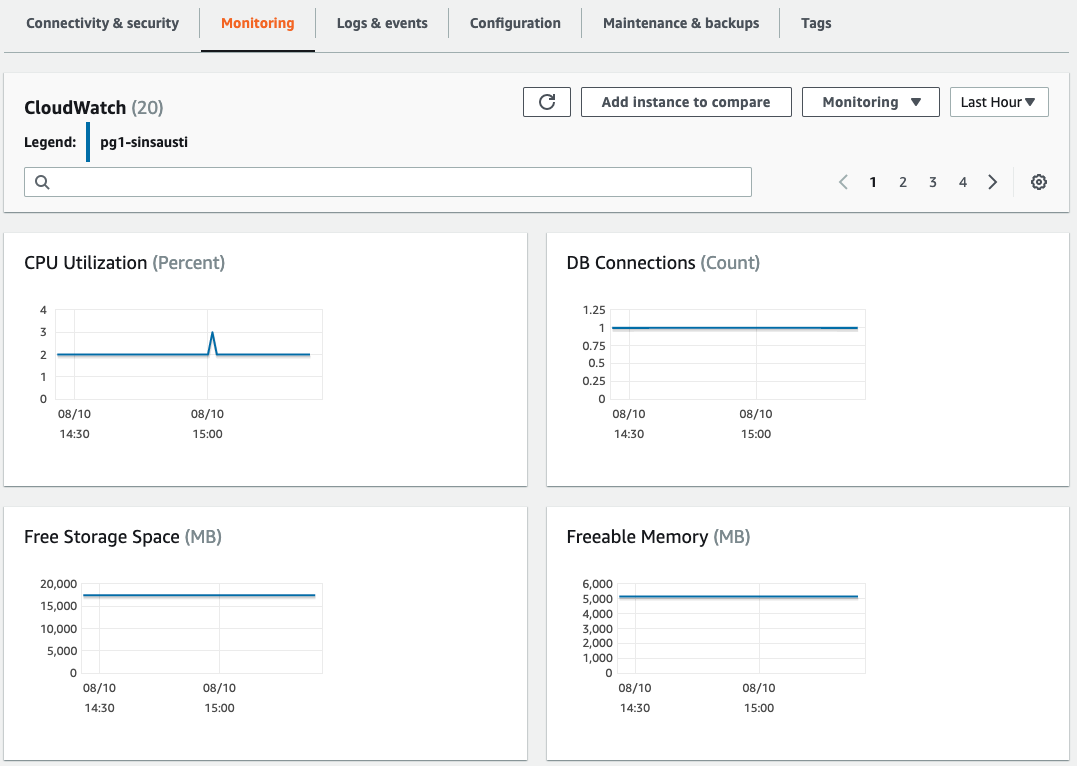
Then, in the “Logs & events” section, you can create alarms based on different metrics, check recent events, and check the database log files.
Conclusion
High Availability is important not only on-prem but also in the cloud, even using a Cloud Provider Solution like DBaaS. We mentioned different things to take into account to make sure you are using a good solution. As an example, we described how AWS handles this and with an SLA of 99.95% uptime monthly, makes it a good choice (with the corresponding cost) if you are looking for High Availability in the cloud.



