Managed Elasticsearch in the cloud, on-prem or both
Version 7.17, 8.3, 8.15
ClusterControl is an Elasticsearch management platform that automates the full lifecycle of your search & analytics clusters — on-premises, in the cloud, or hybrid. It delivers full transparency, infrastructure sovereignty, and cost control with no vendor lock-in and no reliance on Elastic Cloud.
Unlock More with ClusterControl + Elasticsearch

Deploy Elasticsearch Clusters
Provision Elasticsearch clusters with master, data, and ingest nodes in just a few guided steps.

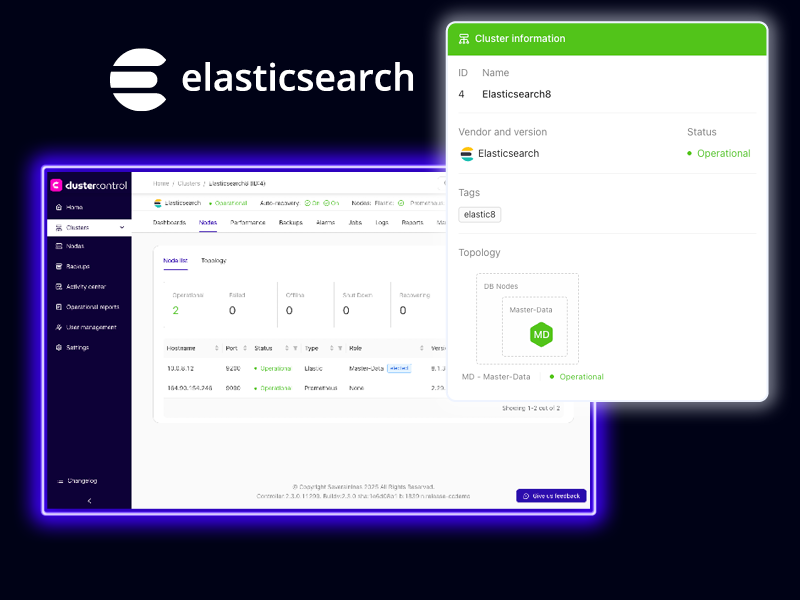
Monitor Cluster and Shard Health
Track node performance, disk usage, and cluster state with real-time dashboards and built-in tuning recommendations.

Snapshot Backup & Recovery
Take and restore on-demand or scheduled snapshots to local or cloud storage.

Scale and Balance Nodes Easily
Add or remove data nodes as needed and rebalance shards automatically, ensuring optimized query distribution across the cluster.

Self-Healing and Recovery Flows
Detect failures, trigger recovery, and rebalance shards automatically — ensuring high availability with minimal disruption.

Secure Your Cluster End to End
Enable TLS, configure user roles, enforce LDAP authentication, and maintain full audit logs for security compliance and access transparency.
ClusterControl vs. the Alternatives
ClusterControl is an Elasticsearch cluster manager built for engineers and trusted by enterprises.
| Feature | ClusterControl | Elastic Cloud |
|---|---|---|
| On‑prem & hybrid support | X | |
| Automated data distribution & scaling | ||
| Full control | X | |
| Lifecycle automation | ||
| Advanced observability | Limited |
Still Managing Elasticsearch by Hand? Time to Upgrade.
ClusterControl is the Elasticsearch management platform DevOps teams actually want. Built for engineers. Trusted by enterprises. Made for your infrastructure.
ClusterControl supports your Elasticsearch lifecycle end-to-end:
Deploy: Create full-fledged clusters with customized role assignments in minutes.
Observe: Real-time dashboards for cluster health, shard balance, node performance, and advisor suggestions for optimization.
Recover: Schedule and archive snapshot backups with encryption and retention to cloud or local storage.
Scale: Add or remove nodes seamlessly and rebalance shards automatically.
Automate: Built-in advisors detect shard imbalance, slow segments, or disk pressure. Auto-healing workflows resolve issues with minimal intervention.
Using several different tools, rather than a one-stop shop, was detrimental to our productivity. Severalnines is that “shop” and we haven’t looked back. It’s an awesome solution like no other.
Supported Elasticsearch Configurations
Supported Distributions
Choose from native Elasticsearch deployments and flexible installation methods:
ClusterControl also supports deployments via official Elasticsearch repositories, operating system package managers (e.g., APT, YUM), or custom binaries — maximizing flexibility.
Elasticsearch (Open Source) – Official upstream distribution maintained by Elastic.
Cluster Topology & Roles
Under the hood, Elasticsearch ensures durability and fault tolerance through:
- In‑Sync Replica Copies – Elasticsearch uses replication of shard copies (primary and replicas) to maintain data availability and protect against node failure.
Severalnines is Enterprise Ready

Reliable
Zero-downtime operations you can count on.

Secure
Data stays protected, at rest and in transit.

Compliant
GDPR, SOC 2, ISO27001 standards.
Managed Elasticsearch features list
| Licenses | |
| Open Source | |
| Cluster management | |
| Deploy cluster | |
| Add / duplicate / remove / decommission node | |
| High availability | |
| Synchronous replication | |
| Automated failover | |
| Backup / restore | |
| Incremental (snapshot) backups | |
| Local / cloud backups | |
| Observability | |
| Infrastructure / database / query monitoring | |
| Dashboarding / alerting | |
| Security / compliance | |
| Role-based access control | |
| Key management | |
| LDAP integration | |
| TLS encryption | |
| Reporting | |
| Audit log |
Choose the CC plan that fits your use case and preferred payment terms
Advanced
self-serve
Includes all features from Advanced
- Deploy 2 to 5 node clusters
- Monthly subscription
- Pay with Credit Card
- Community support
starts at€250per node, per month
€0.35per node, per hour
Advanced
Includes everything from Community
- Load balancers
- Scaling and failover
- Backup and recovery
- Monitoring and alerting
- Database user management
- Business hours support
Custom pricing
Enterprise
Includes everything from Advanced
- CC Ops Centre
- Backup verification
- Ops reports and audit logs
- RBAC & LDAP / Active Directory
- Key management, TLS encryption
- Web / email / phone 24×7 support
Custom pricing
Want some CC for Elasticsearch info for later?
Security & compliance you can trust
ClusterControl is built with enterprise-grade security to safeguard your data and maintain compliance:
• Role-Based Access Control & Key Management
• LDAP Integration & TLS Encryption
• Comprehensive Audit Logs & Reporting

Top rated Docs
I use Kibana with my Elasticsearch deployment for data manipulation. Does ClusterControl include that functionality too?
With ClusterControl, we focus on what we know best which is automating database provisioning and maintenance. The rest we let you decide so you can keep using Kibana as always.
Should I switch from using my PostgreSQL as a primary database deployment with ClusterControl to using Elasticsearch, as I have terabytes of data I need to go through?
In general, just keep using PostgreSQL as you do now and have a look at the available integrations for connecting with Elasticsearch, as once you’ve automated deployment with ClusterControl, the rest is just connectivity to your desire.
Given the amount of data, I don’t normally take backups for Elasticsearch. What do you recommend?
For DR and as part of a good B’n’R strategy, we highly recommend not only the use of a cluster for HA but using the Elasticsearch snapshot capability that allows you to store the backups locally or on AWS S3.