blog
An Overview of the Various Scan Methods in PostgreSQL

In any of the relational databases engines, it is required to generate a best possible plan which corresponds to the execution of the query with least time and resources. Generally, all databases generate plans in a tree structure format, where the leaf node of each plan tree is called table scan node. This particular node of the plan corresponds to the algorithm to be used to fetch data from the base table.
For example, consider a simple query example as SELECT * FROM TBL1, TBL2 where TBL2.ID>1000; and suppose the plan generated is as below:
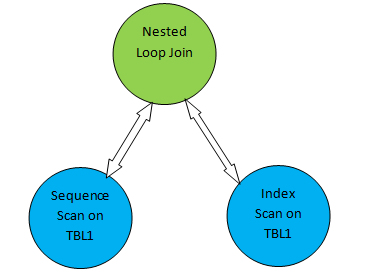
So in the above plan tree, “Sequential Scan on TBL1” and “Index Scan on TBL2” corresponds to table scan method on table TBL1 and TBL2 respectively. So as per this plan, TBL1 will be fetched sequentially from the corresponding pages and TBL2 can be accessed using INDEX Scan.
Choosing the right scan method as part of the plan is very important in terms of overall query performance.
Before getting into all types of scan methods supported by PostgreSQL, let’s revise some of the major key points which will be used frequently as we go through the blog.
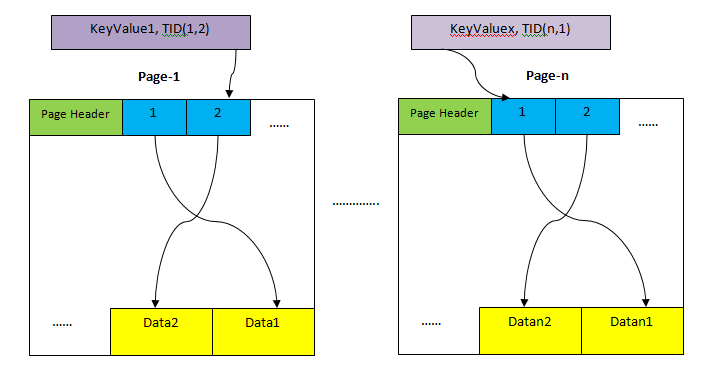
- HEAP: Storage area for storing the whole row of the table. This is divided into multiple pages (as shown in the above picture) and each page size is by default 8KB. Within each page, each item pointer (e.g. 1, 2, ….) points to data within the page.
- Index Storage: This storage stores only key values i.e. columns value contained by index. This is also divided into multiple pages and each page size is by default 8KB.
- Tuple Identifier (TID): TID is 6 bytes number which consists of two parts. The first part is 4-byte page number and remaining 2 bytes tuple index inside the page. The combination of these two numbers uniquely points to the storage location for a particular tuple.
Currently, PostgreSQL supports below scan methods by which all required data can be read from the table:
- Sequential Scan
- Index Scan
- Index Only Scan
- Bitmap Scan
- TID Scan
Each of these scan methods are equally useful depending on the query and other parameters e.g. table cardinality, table selectivity, disk I/O cost, random I/O cost, sequence I/O cost, etc. Let’s create some pre-setup table and populate with some data, which will be used frequently to better explain these scan methods.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZESo in this example, one million records are inserted and then the table is analyzed so that all statistics are up to date.
Sequential Scan
As the name suggests, a Sequential scan of a table is done by sequentially scanning all item pointers of all pages of the corresponding tables. So if there are 100 pages for a particular table and then there are 1000 records in each page, as part of sequential scan it will fetch 100*1000 records and check if it matches as per isolation level and also as per the predicate clause. So even if only 1 record is selected as part of the whole table scan, it will have to scan 100K records to find a qualified record as per the condition.
As per the above table and data, the following query will result in a sequential scan as the majority of data are getting selected.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)NOTE
Though without calculating and comparing plan cost, it is almost impossible to tell which kind of scans will be used. But in order for the sequential scan to be used at-least below criteria should match:
- No Index available on key, which is part of the predicate.
- Majority of rows are getting fetched as part of the SQL query.
TIPS
In case only very few % of rows are getting fetched and the predicate is on one (or more) column, then try to evaluate performance with or without index.
Index Scan
Unlike Sequential Scan, Index scan does not fetch all records sequentially. Rather it uses different data structure (depending on the type of index) corresponding to the index involved in the query and locate required data (as per predicate) clause with very minimal scans. Then the entry found using the index scan points directly to data in heap area (as shown in the above figure), which is then fetched to check visibility as per the isolation level. So there are two steps for index scan:
- Fetch data from index related data structure. It returns the TID of corresponding data in heap.
- Then the corresponding heap page is directly accessed to get whole data. This additional step is required for the below reasons:
- Query might have requested to fetch columns more than whatever available in the corresponding index.
- Visibility information is not maintained along with index data. So in order to check the visibility of data as per isolation level, it needs to access heap data.
Now we may wonder why not always use Index Scan if it is so efficient. So as we know everything comes with some cost. Here the cost involved is related to the type of I/O we are doing. In the case of Index Scan, Random I/O is involved as for each record found in index storage, it has to fetch corresponding data from HEAP storage whereas in case of Sequential Scan, Sequence I/O is involved which takes roughly just 25% of random I/O timing.
So Index scan should be chosen only if overall gain outperform the overhead incurred because of Random I/O cost.
As per the above table and data, the following query will result in an index scan as only one record is getting selected. So random I/O is less as well as searching of the corresponding record is quick.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Index Only Scan
Index Only Scan is similar to Index Scan except for the second step i.e. as the name implies it only scans index data structure. There are two additional pre-condition in order to choose Index Only Scan compare to Index Scan:
- Query should be fetching only key columns which are part of the index.
- All tuples (records) on the selected heap page should be visible. As discussed in previous section index data structure does not maintain visibility information so in order to select data only from index we should avoid checking for visibility and this could happen if all data of that page are considered visible.
The following query will result in an index only scan. Even though this query is almost similar in terms of selecting number of records but as only key field (i.e. “num”) is getting selected, it will choose Index Only Scan.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Bitmap Scan
Bitmap scan is a mix of Index Scan and Sequential Scan. It tries to solve the disadvantage of Index scan but still keeps its full advantage. As discussed above for each data found in the index data structure, it needs to find corresponding data in heap page. So alternatively it needs to fetch index page once and then followed by heap page, which causes a lot of random I/O. So bitmap scan method leverage the benefit of index scan without random I/O. This works in two levels as below:
- Bitmap Index Scan: First it fetches all index data from the index data structure and creates a bit map of all TID. For simple understanding, you can consider this bitmap contains a hash of all pages (hashed based on page no) and each page entry contains an array of all offset within that page.
- Bitmap Heap Scan: As the name implies, it reads through bitmap of pages and then scans data from heap corresponding to stored page and offset. At the end, it checks for visibility and predicate etc and returns the tuple based on the outcome of all these checks.
Below query will result in Bitmap scan as it is not selecting very few records (i.e. too much for index scan) and at the same time not selecting a huge number of records (i.e. too little for a sequential scan).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Now consider below query, which selects the same number of records but only key fields (i.e. only index columns). Since it selects only key, it does not need to refer heap pages for other parts of data and hence there is no random I/O involved. So this query will choose Index Only Scan instead of Bitmap Scan.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)TID Scan
TID, as mentioned above, is 6 bytes number which consists of 4-byte page number and remaining 2 bytes tuple index inside the page. TID scan is a very specific kind of scan in PostgreSQL and gets selected only if there is TID in the query predicate. Consider below query demonstrating the TID Scan:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)So here in the predicate, instead of giving an exact value of the column as condition, TID is provided. This is something similar to ROWID based search in Oracle.
Bonus
All of the scan methods are widely used and famous. Also, these scan methods are available in almost all relational database. But there is another scan method recently in discussion in the PostgreSQL community and as well recently added in other relational databases. It is called “Loose IndexScan” in MySQL, “Index Skip Scan” in Oracle and “Jump Scan” in DB2.
This scan method is used for a specific scenario where in distinct value of leading key column of B-Tree index is selected. As part of this scan, it avoids traversing all equal key column value rather just traverse the first unique value and then jump to the next big one.
This work is still in progress in PostgreSQL with the tentative name as “Index Skip Scan” and we may expect to see this in a future release.