blog
How ClusterControl Performs Automatic Database Recovery and Failover

ClusterControl is programmed with a number of recovery algorithms to automatically respond to different types of common failures affecting your database systems. It understands different types of database topologies and database-related process management to help you determine the best way to recover the cluster. In a way, ClusterControl improves your database availability.
Some topology managers only cover cluster recovery like MHA, Orchestrator, and mysqlfailover but you have to handle the node recovery by yourself. ClusterControl supports recovery at both cluster and node levels.
Configuration Options
There are two recovery components supported by ClusterControl, namely:
- Cluster – Attempt to recover a cluster to an operational state
- Node – Attempt to recover a node to an operational state
These two components are the most important things in order to make sure the service availability is as high as possible. If you already have a topology manager on top of ClusterControl, you can disable automatic recovery feature and let other topology manager handle it for you. You have all the possibilities with ClusterControl.
The automatic recovery feature can be enabled and disabled with a simple toggle ON/OFF, and it works for cluster or node recovery. The green icons mean enabled and red icons means disabled. The following screenshot shows where you can find it in the database cluster list:
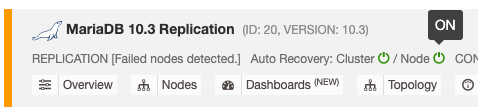
There are 3 ClusterControl parameters that can be used to control the recovery behaviour. All parameters are default to true (set with boolean integer 0 or 1):
- enable_autorecovery – Enable cluster and node recovery. This parameter is the superset of enable_cluster_recovery and enable_node_recovery. If it’s set to 0, the subset parameters will be turned off.
- enable_cluster_recovery – ClusterControl will perform cluster recovery if enabled.
- enable_node_recovery – ClusterControl will perform node recovery if enabled.
Cluster recovery covers recovery attempt to bring up entire cluster topology. For example, a master-slave replication must have at least one master alive at any given time, regardless of the number of available slave(s). ClusterControl attempts to correct the topology at least once for replication clusters, but infinitely for multi-master replication like NDB Cluster and Galera Cluster.
Node recovery covers node recovery issue like if a node was being stopped without ClusterControl knowledge, e.g, via system stop command from SSH console or being killed by OOM process.
Node Recovery
ClusterControl is able to recover a database node in case of intermittent failure by monitoring the process and connectivity to the database nodes. For the process, it works similarly to systemd, where it will make sure the MySQL service is started and running unless you intentionally stopped it via ClusterControl UI.
If the node comes back online, ClusterControl will establish a connection back to the database node and will perform the necessary actions. The following is what ClusterControl would do to recover a node:
- It will wait for systemd/chkconfig/init to start up the monitored services/processes for 30 seconds
- If the monitored services/processes are still down, ClusterControl will try to start the database service automatically.
- If ClusterControl is unable to recover the monitored services/processes, an alarm will be raised.
Note that if a database shutdown is initiated by the user, ClusterControl will not attempt to recover the particular node. It expects the user to start it back via ClusterControl UI by going to Node -> Node Actions -> Start Node or use the OS command explicitly.
The recovery includes all database-related services like ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus exporters, and garbd. Special attention to Prometheus exporters where ClusterControl uses a program called “daemon” to daemonize the exporter process. ClusterControl will try to connect to the exporter’s listening port for health check and verification. Thus, it’s recommended to open the exporter ports from ClusterControl and Prometheus server to make sure no false alarms during recovery.
Cluster Recovery
ClusterControl understands the database topology and follows best practices in performing the recovery. For a database cluster that comes with built-in fault tolerance like Galera Cluster, NDB Cluster and MongoDB Replicaset, the failover process will be performed automatically by the database server via quorum calculation, heartbeat, and role switching (if any). ClusterControl monitors the process and makes necessary adjustments to the visualization like reflecting the changes under the Topology view and adjusting the monitoring and management component for the new role e.g, a new primary node in a replica set.
For database technologies that do not have built-in fault tolerance with automatic recovery like MySQL/MariaDB Replication and PostgreSQL/TimescaleDB Streaming Replication, ClusterControl will perform the recovery procedures by following the best practices provided by the database vendor. If the recovery fails, user intervention is required, and of course, you will get an alarm notification regarding this.
In a mixed/hybrid topology, for example, an asynchronous slave which is attached to a Galera Cluster or NDB Cluster, the node will be recovered by ClusterControl if cluster recovery is enabled.
Cluster recovery does not apply to standalone MySQL server. However, it’s recommended to turn on both node and cluster recoveries for this cluster type in the ClusterControl UI.
MySQL/MariaDB Replication
ClusterControl supports recovery of the following MySQL/MariaDB replication setup:
- Master-slave with MySQL GTID
- Master-slave with MariaDB GTID
- Master-slave with without GTID (both MySQL and MariaDB)
- Master-master with MySQL GTID
- Master-master with MariaDB GTID
- Asynchronous slave attached to a Galera Cluster
ClusterControl will respect the following parameters when performing cluster recovery:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
For more details on each of the parameters, refer to the documentation page.
ClusterControl will obey the following rules when monitoring and managing a master-slave replication:
- All nodes will be started with read_only=ON and super_read_only=ON (regardless of its role).
- Only one master (read_only=OFF) is allowed to operate at any given time.
- Rely on MySQL variable report_host to map the topology.
- If there are two or more nodes that have read_only=OFF at a time, ClusterControl will automatically set read_only=ON on both masters, to protect them against accidental writes. User intervention is required to pick the actual master by disabling the read-only. Go to Nodes -> Node Actions -> Disable Readonly.
In case the active master goes down, ClusterControl will attempt to perform the master failover in the following order:
- After 3 seconds of master unreachability, ClusterControl will raise an alarm.
- Check the slave availability, at least one of the slaves must be reachable by ClusterControl.
- Pick the slave as a candidate to be a master.
- ClusterControl will calculate the probability of errant transactions if GTID is enabled.
- If no errant transaction is detected, the chosen will be promoted as the new master.
- Create and grant replication user to be used by slaves.
- Change master for all slaves that were pointing to the old master to the newly promoted master.
- Start slave and enable read-only.
- Flush logs on all nodes.
- If the slave promotion fails, ClusterControl will abort the recovery job. User intervention or a cmon service restart is required to trigger the recovery job again.
- When the old master is available again, it will be started as read-only and will not be part of the replication. User intervention is required.
At the same time, the following alarms will be raised:
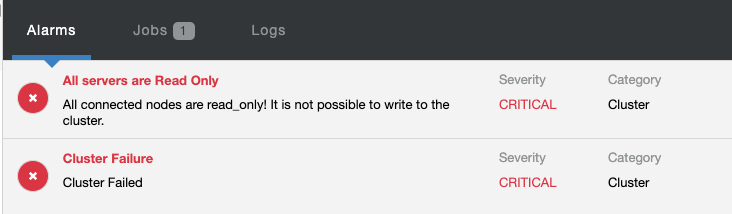
Check out Introduction to Failover for MySQL Replication – the 101 Blog and Automatic Failover of MySQL Replication – New in ClusterControl 1.4 to get further information on how to configure and manage MySQL replication failover with ClusterControl.
PostgreSQL/TimescaleDB Streaming Replication
ClusterControl supports recovery of the following PostgreSQL replication setup:
ClusterControl will respect the following parameters when performing cluster recovery:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
For more details on each of the parameters, refer to the documentation page.
ClusterControl will obey the following rules for managing and monitoring a PostgreSQL streaming replication setup:
- wal_level is set to “replica” (or “hot_standby” depending on the PostgreSQL version).
- Variable archive_mode is set to ON on the master.
- Set recovery.conf file on the slave nodes, which turns the node into a hot standby with read-only enabled.
In case the active master goes down, ClusterControl will attempt to perform the cluster recovery in the following order:
- After 10 seconds of master unreachability, ClusterControl will raise an alarm.
- After 10 seconds of graceful waiting timeout, ClusterControl will initiate the master failover job.
- Sample the replayLocation and receiveLocation on all available nodes to determine the most advanced node.
- Promote the most advanced node as the new master.
- Stop slaves.
- Verify the synchronization state with pg_rewind.
- Restarting slaves with the new master.
- If the slave promotion fails, ClusterControl will abort the recovery job. User intervention or a cmon service restart is required to trigger the recovery job again.
- When the old master is available again, it will be forced to shut down and will not be part of the replication. User intervention is required. See further down.
When the old master comes back online, if PostgreSQL service is running, ClusterControl will force the shutdown of the PostgreSQL service. This is to protect the server from accidental writes, since it would be started without a recovery file (recovery.conf), which means it would be writable. You should expect the following lines will appear in postgresql-{day}.log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downThe PostgreSQL was started after the server was back online around 05:06:10 but ClusterControl performs a fast shutdown 17 seconds after that around 05:06:27. If this is something that you would not want it to be, you can disable node recovery for this cluster momentarily.
Conclusion
ClusterControl automatic recovery understands database cluster topology and can recover a down or degraded cluster to a fully operational cluster, improving the database service uptime tremendously. Check out Automatic Failover of Postgres Replication and Failover for PostgreSQL Replication 101 to get further information on configuring and managing PostgreSQL replication failover with ClusterControl. Try ClusterControl now and achieve your nines in SLA and database availability. Don’t know your nines? Check out this cool nines calculator.
To keep up to date with all ClusterControl news, follow us on Twitter and LinkedIn and subscribe to our newsletter.