blog
Schema Upgrades in Galera Cluster for MySQL and MariaDB – How to Avoid RSU Locks

Working as MySQL DBA, you will often have to deal with schema changes. Changes to production databases are not popular among DBAs, but they are necessary when applications add new requirements on the databases. If you manage a Galera Cluster, this is even more challenging than usual – the default method of doing schema changes (Total Order Isolation) locks the whole cluster for the duration of the alter. There are two more ways to go, though – online schema change and Rolling Schema Upgrade.
A popular method of performing schema changes, using pt-online-schema-change, has its own limitations. It can be tricky if your workload consists of long running transactions, or the workload is highly concurrent and the tool may not be able to acquire metadata locks needed to create triggers. Triggers themselves can become a hard stop if you already have triggers in the table you need to alter (unless you use Galera Cluster based on MySQL 5.7). Foreign keys may also become a serious issue to deal with. You can find more data on those limitations in this Become a MySQL DBA blog post . New alternatives to pt-online-schema-change arrived recently – gh-ost created by GitHub, but it’s still a new tool and unless you evaluated it already, you may have to stick to pt-online-schema-change for time being.
This leaves Rolling Schema Upgrade as the only feasible method to execute schema changes where pt-online-schema-change failed or is not feasible to use. Theoretically speaking, it is a non-blocking operation – you run:
SET SESSION wsrep_OSU_method=RSU;And the rest should happen automatically once you start the DDL – the node should be desynced and alter should not impact the rest of the cluster.
Let’s check how it behaves in real life, in two scenarios. First, we have a single connection to the Galera cluster. We don’t scale out reads, we just use Galera as a way to improve availability of our application. We will simulate it by running a sysbench workload on one of the Galera cluster nodes. We are also going to execute RSU on this node. A screenshot with result of this operation can be found below.
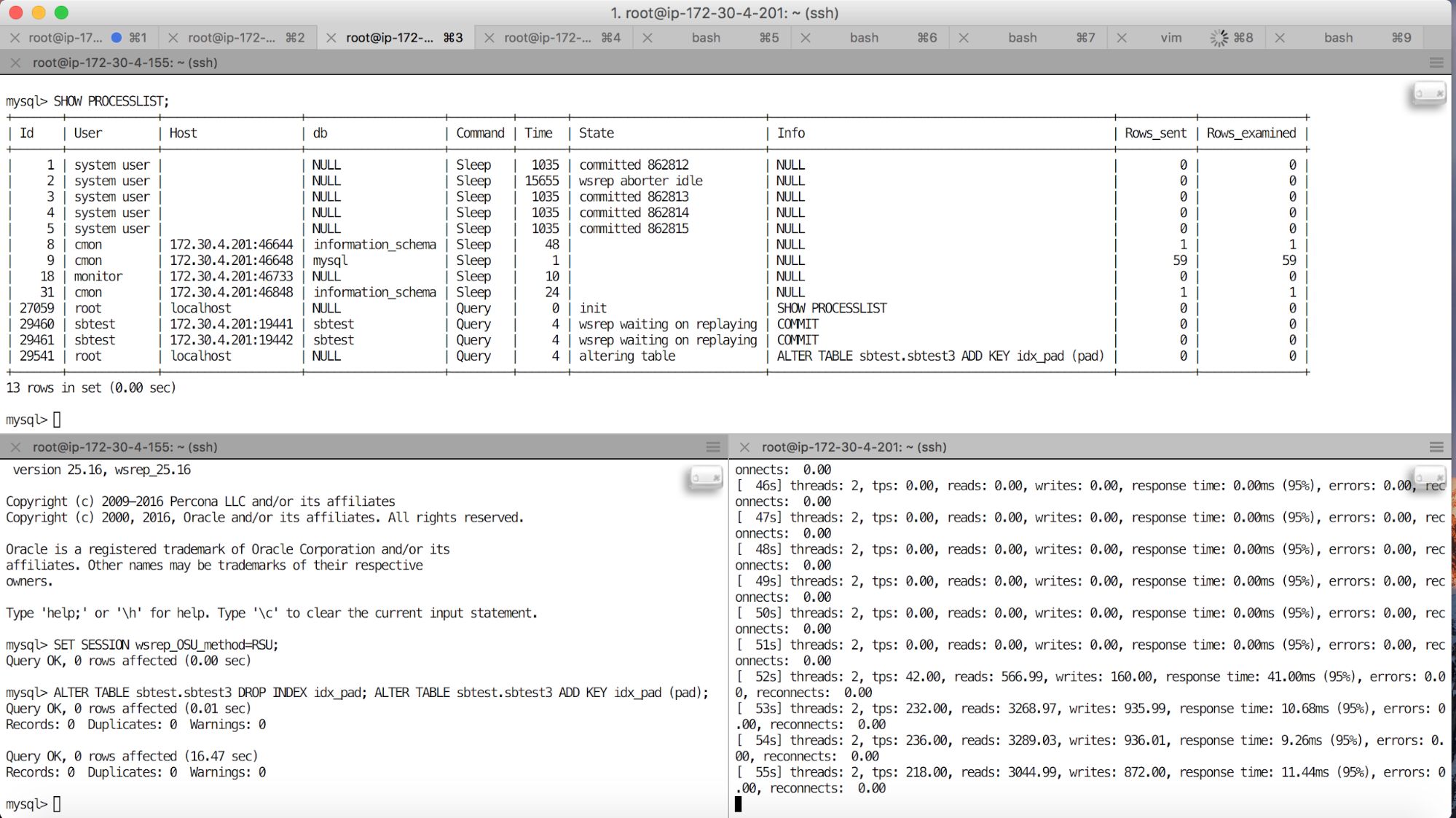
On the bottom right window you can see the output of sysbench – our application. On the top window there’s a SHOW PROCESSLIST output at the time the alter was running. As you can see, our application stalled for couple of seconds – for the duration of the alter command (visible in bottom left window). Graphs in the ClusterControl show the stalled queries in detail:
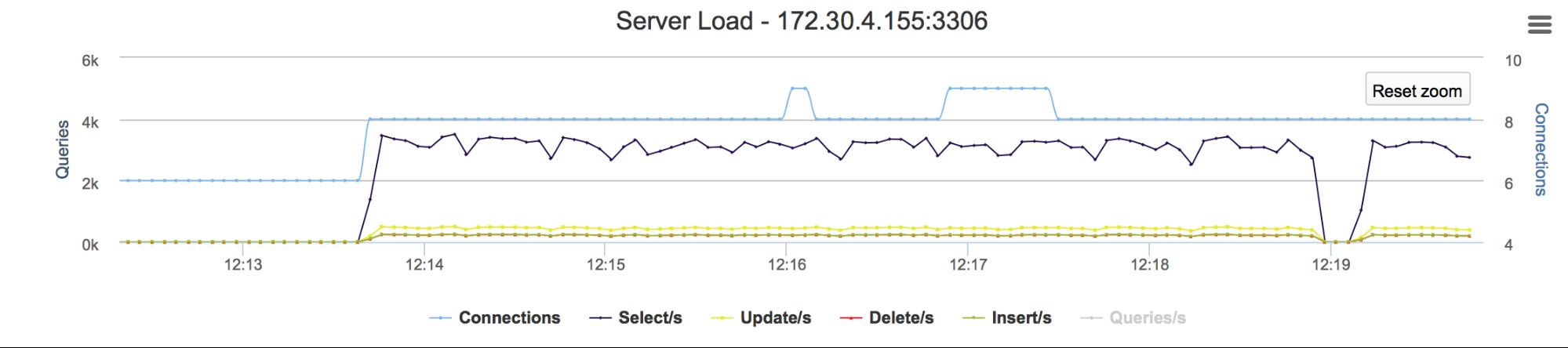
You may say, and rightly so, that this is expected – if you write to a node where schema change is performed, those writes have to wait.
What about if we use some sort of round-robin routing of connections? This can be done in the application (just define a pool of hosts to connect to), it can be done at the connector level. It also can be done using a proxy. Results are in the screenshot below.
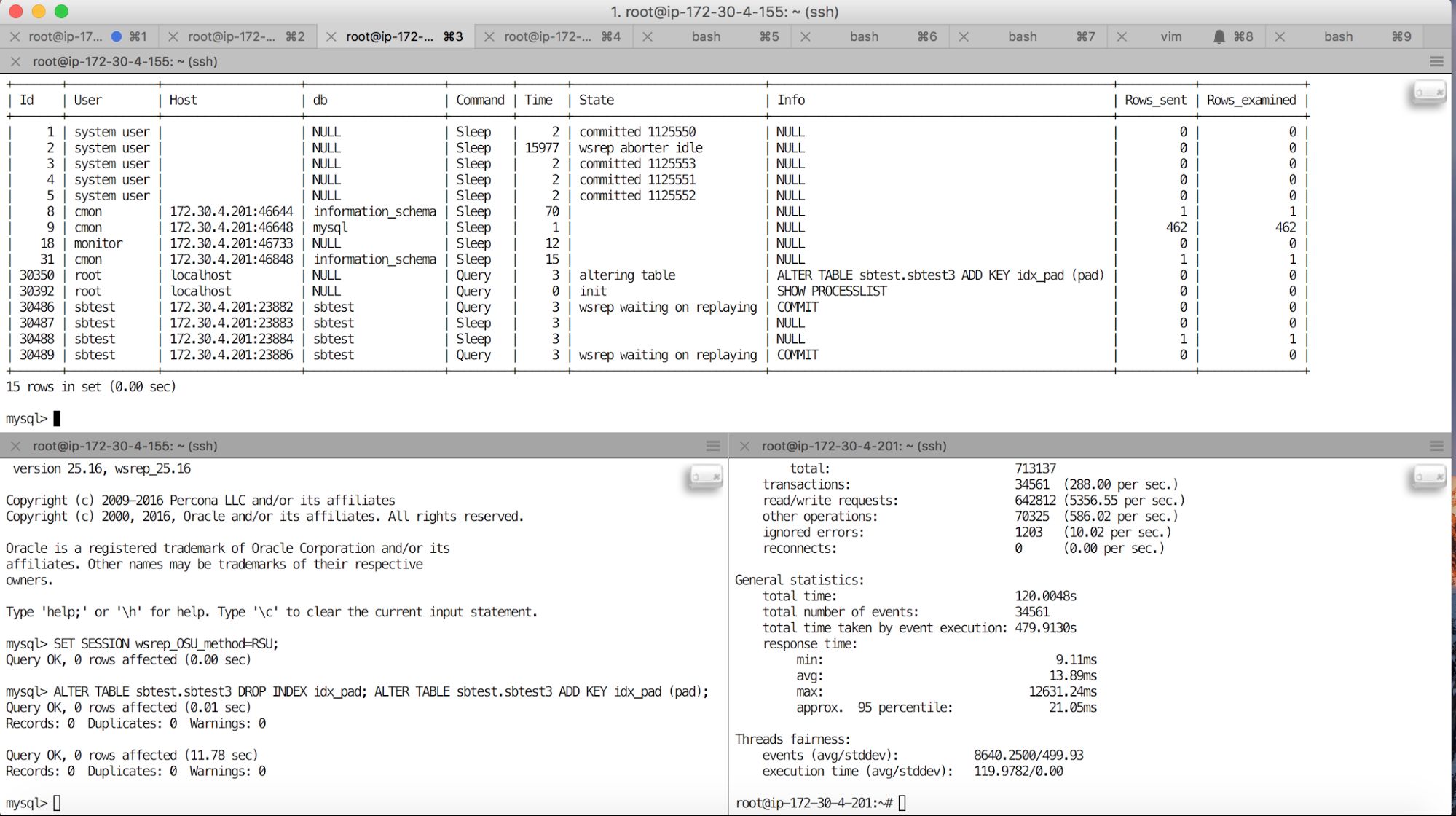
As you can see, here we also have locked threads which were routed to the host where RSU was in progress. The rest of threads worked ok but some of the connections stalled for a duration of the alter. Please take a closer look at the length of an alter (11.78s) and the maximum response time (12.63s). Some of the users experienced significant performance degradation.
One question you may want to ask is – starting ALTER in RSU desyncs the Galera node. Proxies like ProxySQL, MaxScale or HAProxy (when used in connection with clustercheck script) should detect this behavior and redirect the traffic off the desynced host. Why is it locking commits? Unfortunately, there’s a high probability that some transactions will be in progress and those will get locked after the ALTER starts.
How to avoid the problem? You need to use a proxy. It’s not enough on it’s own, as we have proven just before. But as long as your proxy removes desynced hosts out of rotation, you can easily add this step to the RSU process and make sure a node is desynced and not accepting any form of traffic before you actually start your DDL.
mysql> SET GLOBAL wsrep_desync=1; SELECT SLEEP(20); ALTER TABLE sbtest.sbtest3 DROP INDEX idx_pad; ALTER TABLE sbtest.sbtest3 ADD KEY idx_pad (pad); SET GLOBAL wsrep_desync=0;This should work with all proxies deployed through ClusterControl – HAProxy and MaxScale. ProxySQL will also be able to handle RSU executed in that way correctly.
Another method, which can be used for HAProxy, would be to disable a backend node by setting it to maintenance state. You can do this from ClusterControl:
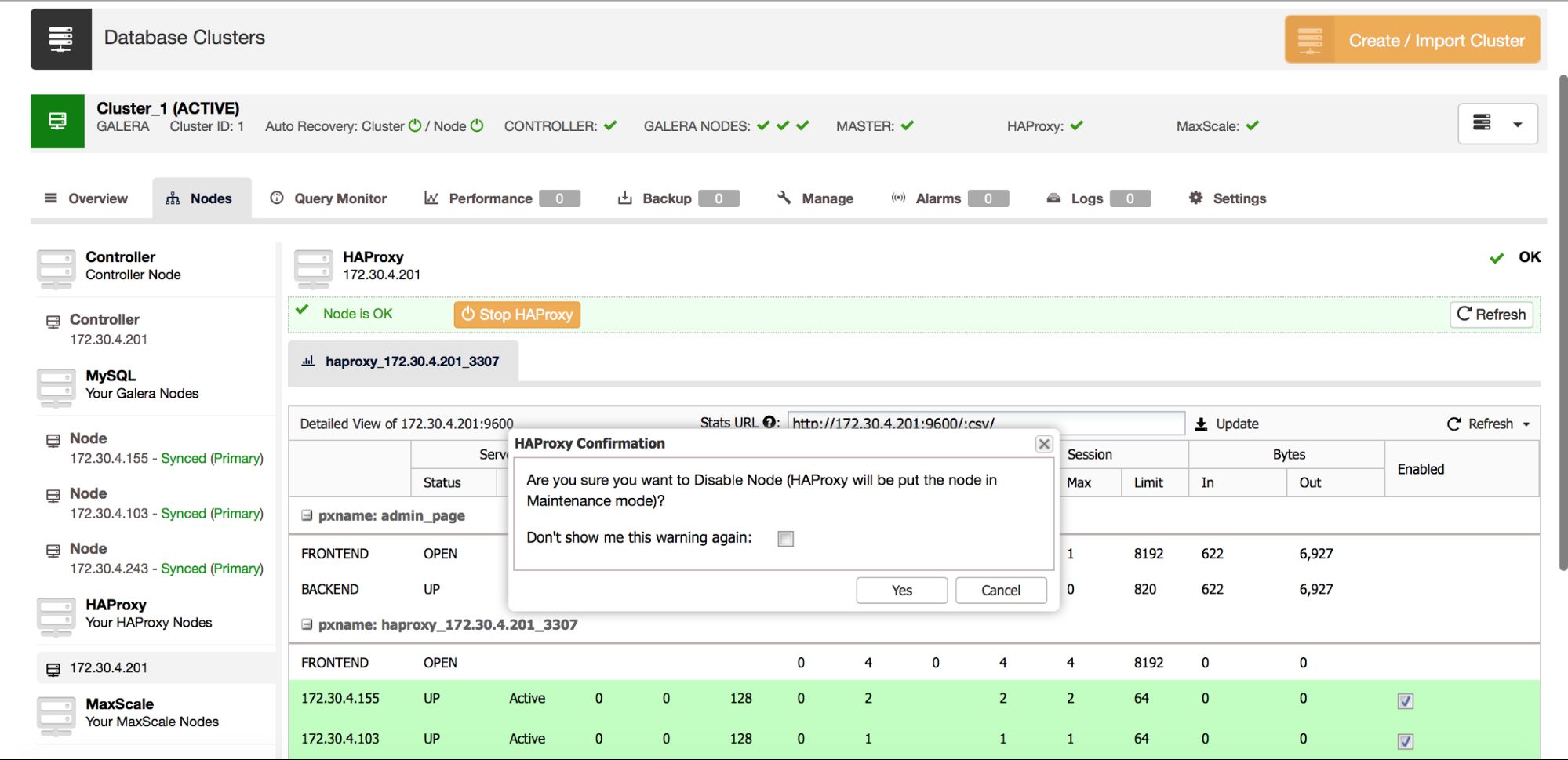
Make sure you ticked the correct node, confirm that’s what you want to do, and in a couple of minutes you should be good to start RSU on that node. The host will be highlighted in brown:
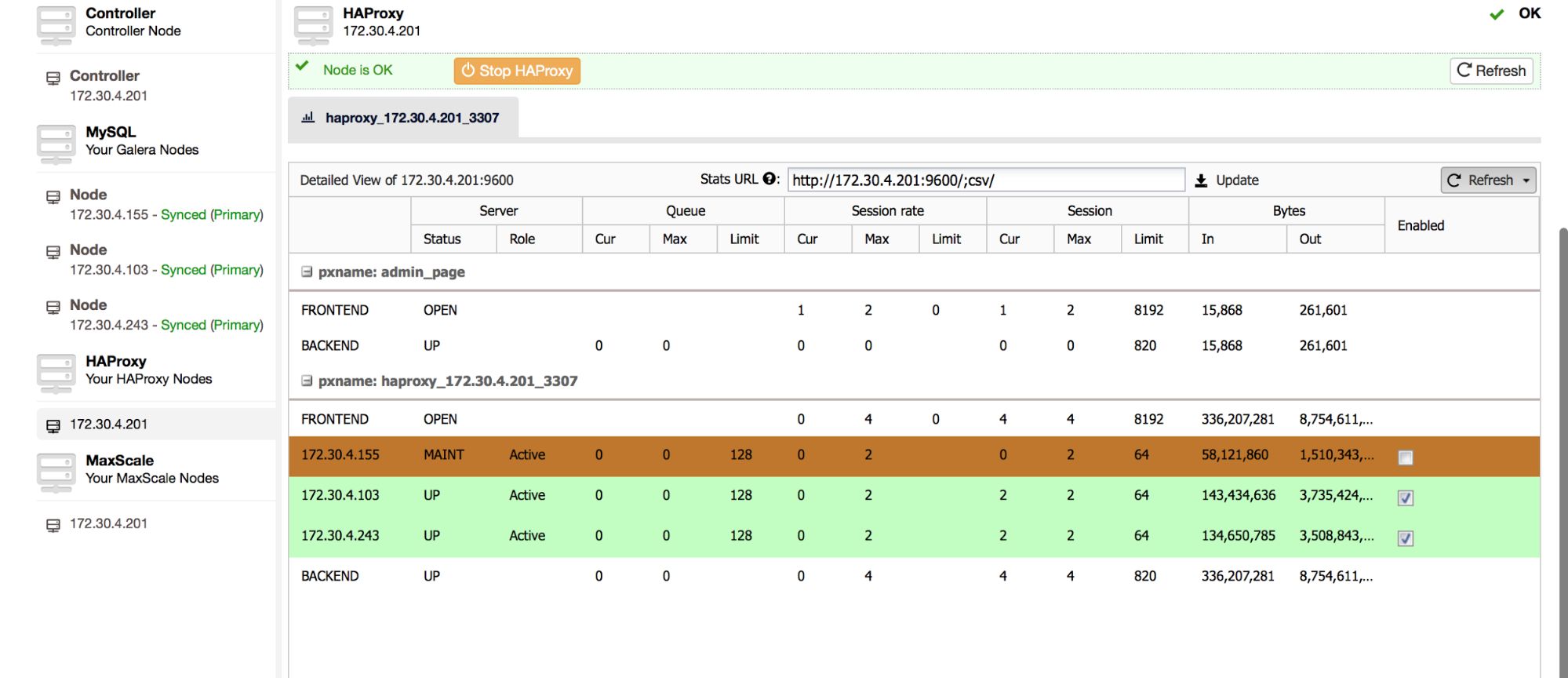
It’s still better to be on the safe side and verify using SHOW PROCESLIST (also available in the ClusterControl -> Query Monitor -> Running Queries) that indeed no traffic is hitting this node. Once you are done running DML’s, you can enable the backend node again in the HAProxy tab in ClusterControl and you’ll be able to route traffic also to this node.
As you can see, even with load balancers used, running RSU may seriously impact performance and availability of your database. Most likely it’ll affect just a small subset of users (a few percent of connections), but it’s still not something we’d like to see. Using properly configured proxies (like those deployed by ClusterControl) and ensuring you first desync the node and then execute RSU, will be enough to avoid this type of problem.