blog
Performing Replication Topology Changes for PostgreSQL

Replication plays a crucial role in maintaining high availability. Servers can fail, the operating system or the database software might need to be upgraded. This means reshuffling server roles and moving replication links, while maintaining data consistency across all databases. Topology changes will be required, and there are different ways to perform them.
Promoting a Standby Server
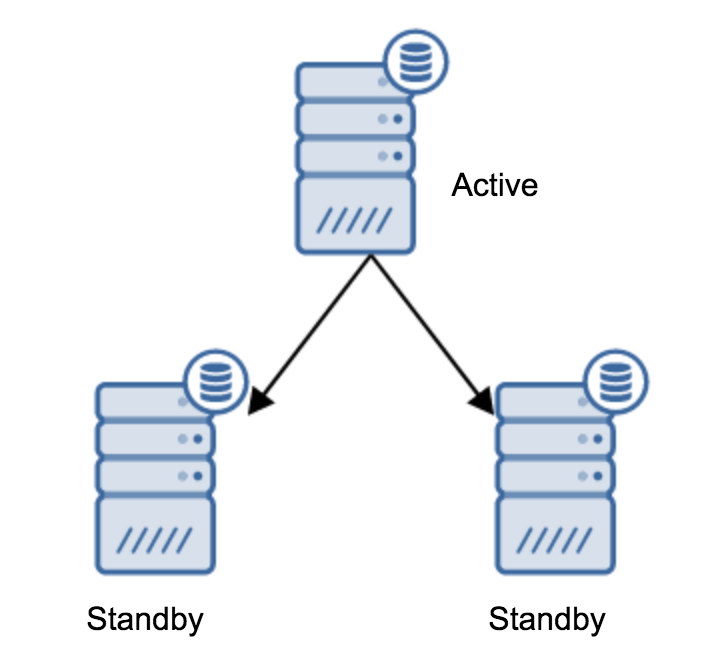
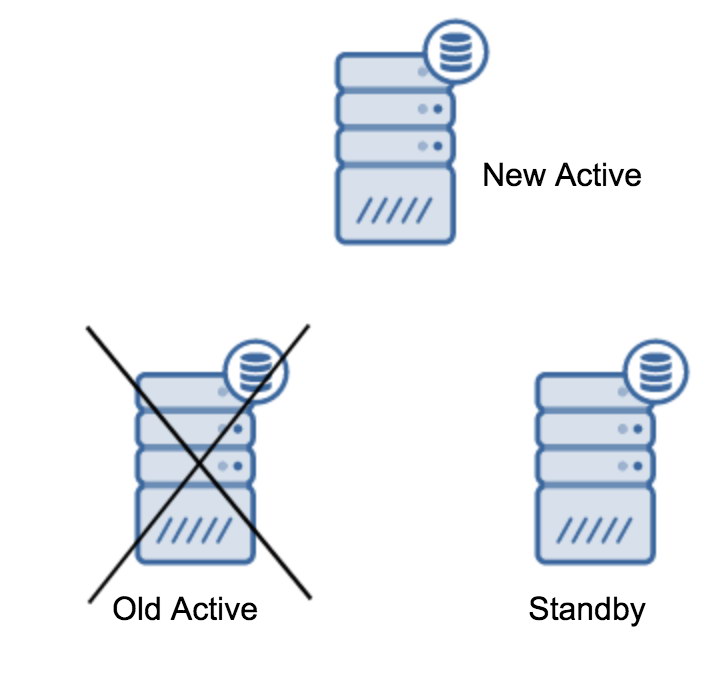
Arguably, this is the most common operation that you will need to perform. There are multiple reasons – for instance, database maintenance on the primary server that would impact the workload in an unacceptable manner. There could be planned downtime due to some hardware operations. The crash of the primary server which renders it unaccessible to the application. These are all reasons to perform a failover, whether planned or not. In all cases you will have to promote one of the standby servers to become a new primary server.
To promote a standby server, you need to run:
postgres@vagrant-ubuntu-trusty-64:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
server promotedIt is easy to run this command, but first, make sure to avoid any loss of data. If we are talking about a “primary server down” scenario, you may not have too many options. If it is a planned maintenance, then it is possible to prepare for it. You need to stop the traffic on the primary server, and then verify that the standby server received and applied all of the data. This can be done on the standby server, using query as below:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Once all is good, you can stop the old primary server and promote the standby server.
Reslaving a Standby Server off a new Primary Server
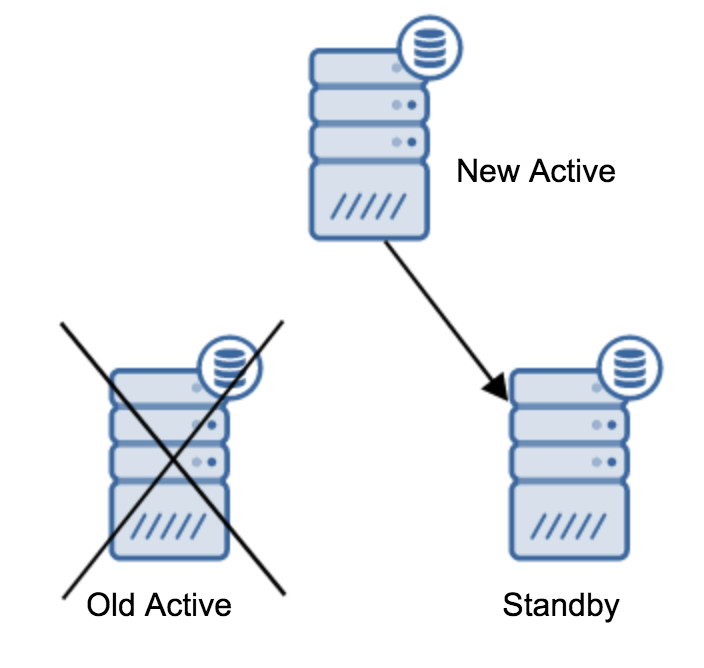
You may have more than one standby server slaving off your primary server. After all, standby servers are useful to offload read-only traffic. After promoting a standby server to a new primary server, you need to do something about the remaining standby servers which are still connected (or which are trying to connect) to the old primary server. Unfortunately, you cannot just change the recovery.conf and connect them to the new primary server. To connect them, you first need to rebuild them. There are two methods you can try here: standard base backup or pg_rewind.
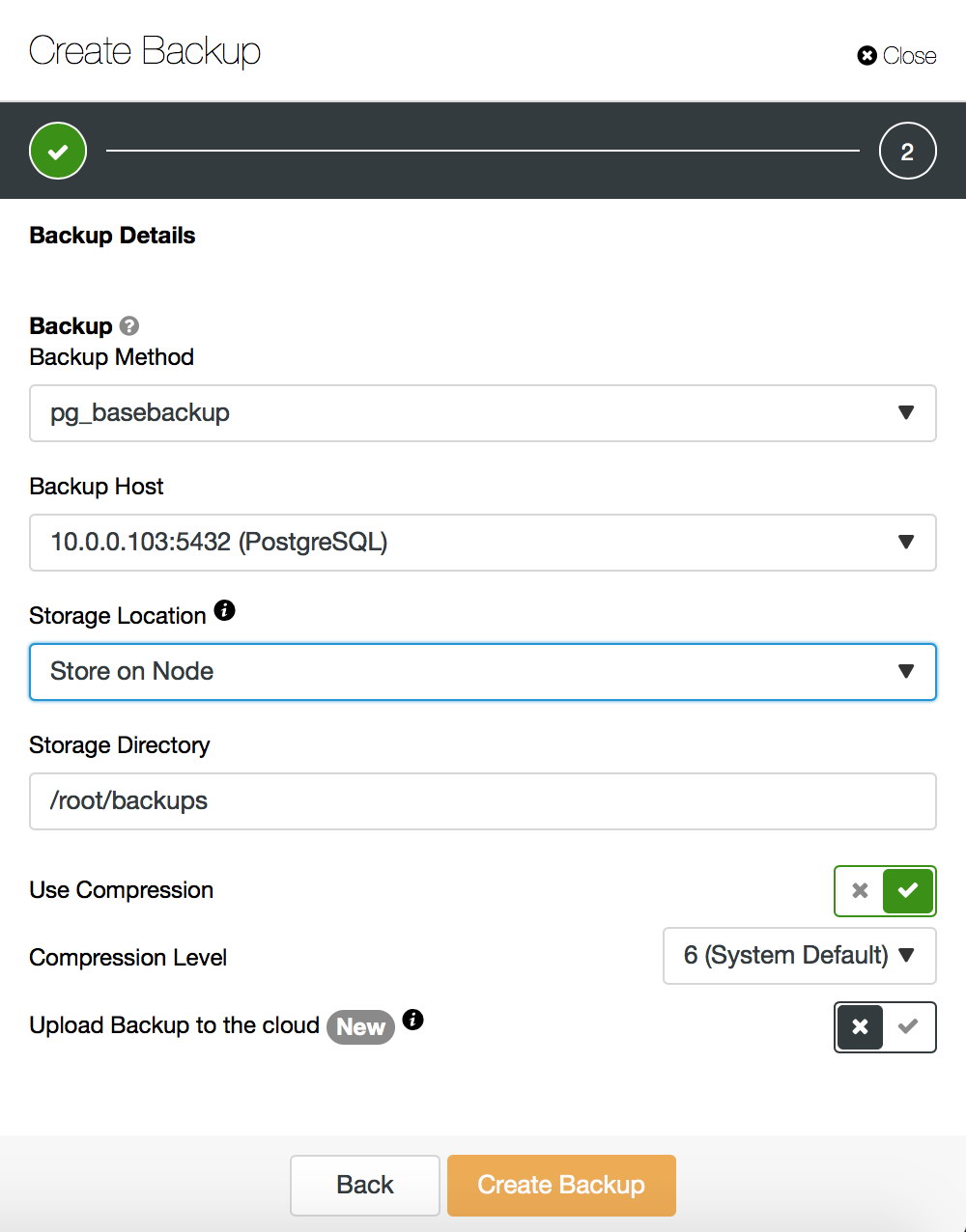
We won’t get into details how to take a base backup – we covered it in our previous blog post, which focussed on taking backups and restoring them on PostgreSQL. If you happen to use ClusterControl, you can also use it to create a base backup:
On the other hand, let’s say couple of words about pg_rewind. The main difference between both methods is that base backup creates a full copy of the data set. If we are talking about small datasets, it can be ok but for datasets with hundreds of gigabytes in size (or even larger), it can quickly become a problem. In the end, you want to have your standby servers quickly up and running – to offload your active server and to have another standby to failover to, should the need arise. Pg_rewind works differently – it copies only those blocks which have been modified. Instead of copying everything, it copies changes only, speeding up the process quite significantly. Let’s assume your new master has an IP of 10.0.0.103. This is how you can execute pg_rewind. Please note that you have to have the target server stopped – PostgreSQL can’t be running there.
postgres@vagrant-ubuntu-trusty-64:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!This will make a dry run, testing the process but not making any changes. If everything is fine, all you’ll have to do will be to run it again, this time without the ‘–dry-run’ parameter. Once it’s done, the last remaining step will be to create a recovery.conf file, which will point to the new master. It may look like this:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Now you are ready to start your standby server and it will replicate off the new active server.
Chained Replication
There are numerous reasons why you might want to build a chained replication, although it is typically done to reduce the load on the primary server. Serving the WAL to standby servers adds some overhead. It’s not much of a problem if you have a standby or two, but if we are talking about large number of standby servers, this can become an issue. For example, we can minimize the number of standby servers replicating directly from the active by creating a topology as below:
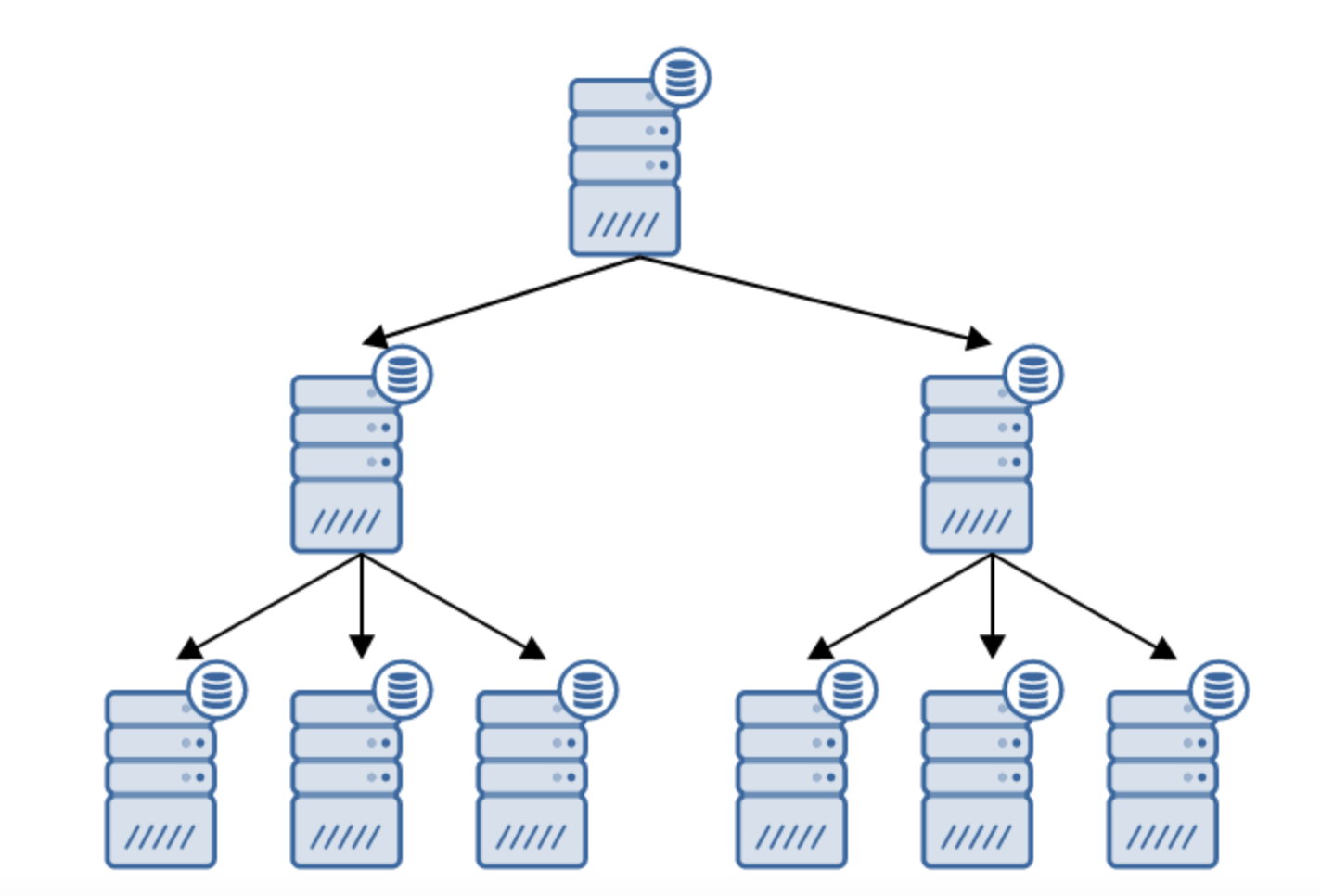
The move from a topology of two standby servers to a chained replication is fairly straightforward.
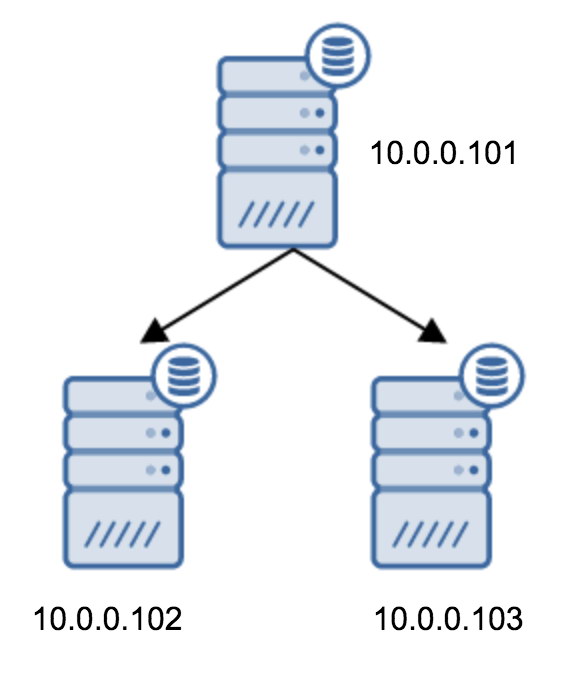
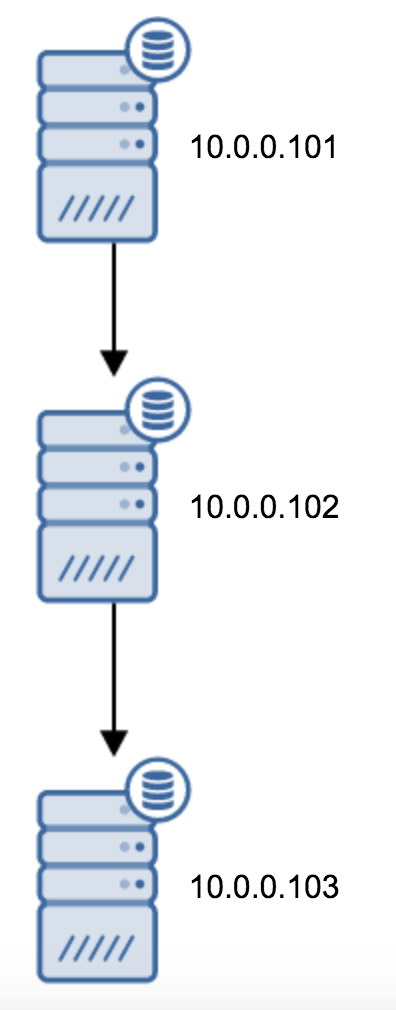
You would need to modify recovery.conf on 10.0.0.103, point it towards the 10.0.0.102 and then restart PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'After restart, 10.0.0.103 should start to apply WAL updates.
These are some common cases of topology changes. One topic that was not discussed, but which is still important, is the impact of these changes on the applications. We’ll cover that in a separate post, as well as how to make these topology changes transparent to the applications.