blog
An Introduction to TimescaleDB

TimescaleDB is an open-source database invented to make SQL scalable for time-series data. It’s a relatively new database system. TimescaleDB has been introduced to the market two years ago and reached version 1.0 in September 2018. Nevertheless, it’s engineered on top of a mature RDBMS system.
TimescaleDB is packaged as a PostgreSQL extension. All code is licensed under the Apache-2 open-source license, with the exception of some source code related to the time-series enterprise features licensed under the Timescale License (TSL).
As a time-series database, it provides automatic partitioning across date and key values. TimescaleDB native SQL support makes it a good option for those who plan to store time-series data and already have solid SQL language knowledge.
If you’re looking for a time-series database that can use rich SQL, HA, a solid backup solution, replication, and other enterprise features, this blog may put you on the right path.
When to use TimescaleDB
Before we start with TimescaleDB features, let’s see where it can fit. TimescaleDB was designed to offer the best of both relational and NoSQL, with the focus of time-series. But what is time series data?
Time series data is at the core of the Internet of Things, monitoring systems and many other solutions focused on frequent changing data. As the name “time-series” suggests, we are talking about data that change with time. The possibilities for such type of DBMS are endless. You can use it in various industrial IoT use cases across manufacturing, mining, oil & gas, retail, healthcare, dev ops monitoring or financial information sector. It can also greatly fit in machine learning pipelines or as a source for business operations and intelligence.
There is no doubt that the demand for IoT and similar solutions will grow. With that said, we may also expect the need to analyze and process data in many different ways. Time-series data typically is only appended – it is quite unlikely that you will be updating old data. You typically do not delete particular rows, on the other hand, you may want some sort of the aggregation of the data over time. We do not only want to store how our data changes with time, but also analyze and learn from it.
The problem with new types of database systems is that they usually use their own query language. It takes time for users to learn a new language. The biggest difference between TimescaleDB and other popular time series databases is the support for SQL. TimescaleDB supports the full range of SQL functionality including time-based aggregates, joins, subqueries, window functions, and secondary indexes. Moreover, if your application is already using PostgreSQL, there are no changes needed to the client code.
Architecture basics
TimescaleDB is implemented as an extension on PostgreSQL, which means that a time-scale database runs within an overall PostgreSQL instance. The extension model allows the database to take advantage of many of the attributes of PostgreSQL such as reliability, security, and connectivity to a wide range of third-party tools. At the same time, TimescaleDB leverages the high degree of customization available to extensions by adding hooks deep into PostgreSQL’s query planner, data model, and execution engine.
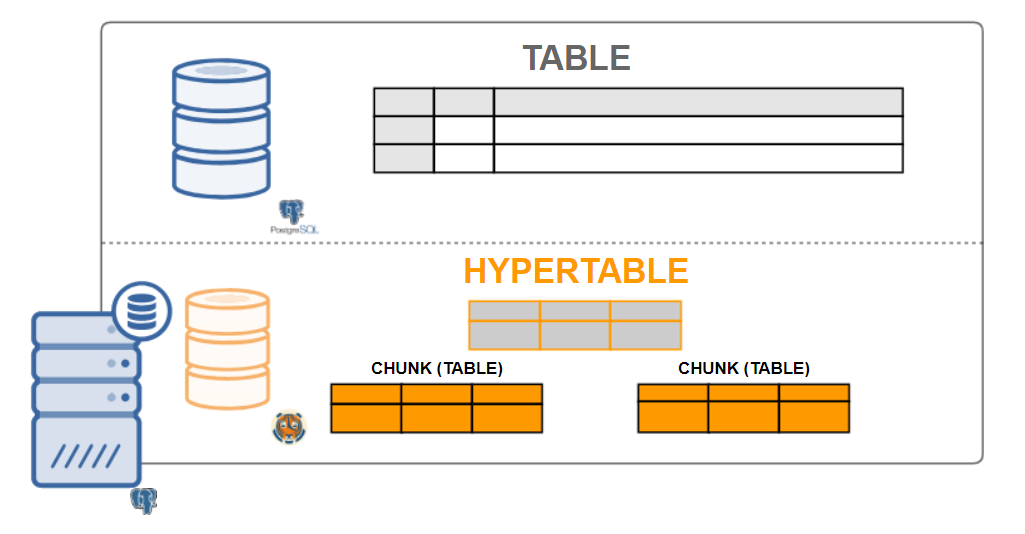
Hypertables
From a user perspective, TimescaleDB data looks like singular tables, called hypertables. Hypertables are a concept or an implicit view of many individual tables holding the data called chunks. The hyper table’s data can be either one or two dimensions. It can be aggregated by a time interval, and by an (optional) “partition key” value.
Practically all user interactions with TimescaleDB are with hypertables. Creating tables, indexes, altering tables, selecting data, inserting data … should be all be executed on the hypertable.
TimescaleDB performs this extensive partitioning both on single-node deployments as well as clustered deployments (in development). While partitioning is traditionally only used for scaling out across multiple machines, it also allows us to scale up to high write rates (and improved parallelized queries) even on single machines.
Relational data support
As a relational database, it has full support for SQL. TimescaleDB supports flexible data models that can be optimized for different use cases. This makes Timescale somewhat different from most other time-series databases. The DBMS is optimized for fast ingest and complex queries, based on PostgreSQL and when needed we have access to robust time-series processing.
Installation
TimescaleDB similarly to PostgreSQL supports many different ways of installation, including installation on Ubuntu, Debian, RHEL/Centos, Windows or cloud platforms.
One of the most convenient ways to play with TimescaleDB is a docker image.
Below command will pull a Docker image from Docker Hub if it has not been already installed and then run it.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbFirst use
Since our instance is up and running, it’s time to create our first timescaledb database. As you can see below, we connect through standard PostgreSQL console so If you have PostgreSQL client tools (e.g., psql) installed locally, you can use those to access the TimescaleDB docker instance.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Day to day operations
From the perspective of both use and management, TimescaleDB just looks and feels like PostgreSQL, and can be managed and queried as such.
The main bullet points for day to day operations are:
- Coexists with other TimescaleDBs and PostgreSQL databases on a PostgreSQL server.
- Uses SQL as its interface language.
- Uses common PostgreSQL connectors to third-party tools for backups, console etc.
TimescaleDB settings
PostgreSQL’s out-of-the-box settings are typically too conservative for modern servers and TimescaleDB. You should make sure your postgresql.conf settings are tuned, either by using timescaledb-tune or doing it manually.
$ timescaledb-tuneThe script will ask you to confirm changes. These changes are then written to your postgresql.conf and will take effect on the restart.
Now, let’s take a look at some basic operations from the TimescaleDB tutorial which can give you an idea of how to work with the new database system.
To create a hypertable, you start with a regular SQL table and then convert it into a hypertable via the function create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Convert it to hypertable is simple as:
SELECT create_hypertable('conditions', 'time');Inserting data into the hypertable is done via normal SQL commands:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);Selecting data, is old good SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;As we can see below we can do a group by, order by, and functions. In addition, TimescaleDB includes functions for time-series analysis that are not present in vanilla PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;