blog
Archival and Analytics – Importing MySQL Data Into a Hadoop Cluster Using Sqoop

We won’t bore you with buzzwords like volume, velocity and variety. This post is for MySQL users who want to get their hands dirty with Hadoop, so roll up your sleeves and prepare for work. Why would you ever want to move MySQL data into Hadoop? One good reason is archival and analytics. You might not want to delete old data, but rather move it into Hadoop and make it available for further analysis at a later stage.
In this post, we are going to deploy a Hadoop Cluster and export data in bulk from a Galera Cluster using Apache Sqoop. Sqoop is a well-proven approach for bulk data loading from a relational database into Hadoop File System. There is also Hadoop Applier available from MySQL labs, which works by retrieving INSERT queries from MySQL master binlog and writing them into a file in HDFS in real-time (yes, it applies INSERTs only).
We will use Apache Ambari to deploy Hadoop (HDP 2.1) on three servers. We have a clustered WordPress site running on Galera, and for the purpose of this blog, we will export some user data to Hadoop for archiving purposes. The database name is wordpress, we will use Sqoop to import the data to a Hive table running on HDFS. The following diagram illustrates our setup:
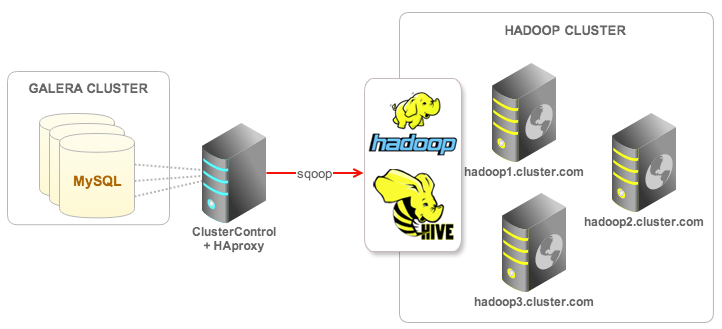
The ClusterControl node has been installed with an HAproxy instance to load balance Galera connections and listen on port 33306.
Prerequisites
All hosts are running CentOS 6.5 with firewall and SElinux turned off. All servers’ time are using NTP server and synced with each other. Hostname must be FQDN or define your hosts across all nodes in /etc/hosts file. Each host has been configured with the following host definitions:
192.168.0.100 clustercontrol haproxy mysql
192.168.0.101 mysql1 galera1
192.168.0.102 mysql2 galera2
192.168.0.103 mysql3 galera3
192.168.0.111 hadoop1 hadoop1.cluster.com
192.168.0.112 hadoop2 hadoop2.cluster.com
192.168.0.113 hadoop3 hadoop3.cluster.comCreate an SSH key and configure passwordless SSH on hadoop1 to other Hadoop nodes to automate the deployment by Ambari Server. In hadoop1, run following commands as root:
$ ssh-keygen -t rsa # press Enter for all prompts
$ ssh-copy-id -i ~/.ssh/id_rsa hadoop1.cluster.com
$ ssh-copy-id -i ~/.ssh/id_rsa hadoop2.cluster.com
$ ssh-copy-id -i ~/.ssh/id_rsa hadoop3.cluster.comOn all Hadoop hosts, install and configure NTP as well as openSSL libraries:
$ yum install ntp openssl openssl-devel -y
$ chkconfig ntpd on
$ service ntpd start
$ ntpdate -u se.pool.ntp.orgDeploying Hadoop
- Install Ambari Server on one of the Hadoop nodes (we chose hadoop1.cluster.com), this will help us deploy the Hadoop cluster. Configure Ambari repository for CentOS 6 and start the installation:
$ cd /etc/yum.repos.d $ wget http://public-repo-1.hortonworks.com/ambari/centos6/1.x/updates/1.5.1/ambari.repo $ yum -y install ambari-server - Setup and start ambari-server:
$ ambari-server setup # accept all default values on prompt $ ambari-server startGive Ambari a few minutes to bootstrap before accessing the web interface at port 8080.
- Open a web browser and navigate to http://hadoop1.cluster.com:8080. Login with username and password ‘admin’. This is the Ambari dashboard, it will guide us through the deployment. Assign a cluster name and click Next.
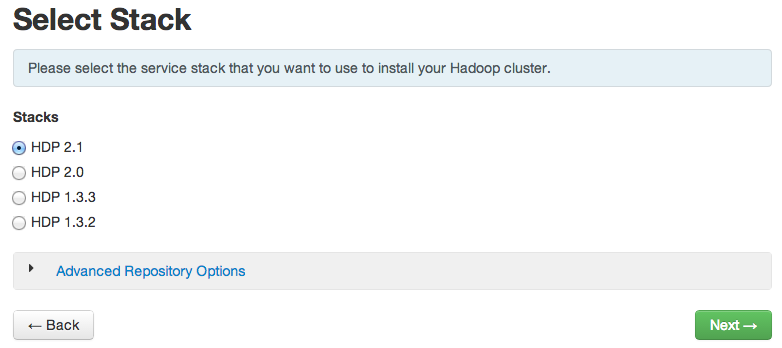
- At the Select Stack step, choose HDP2.1:
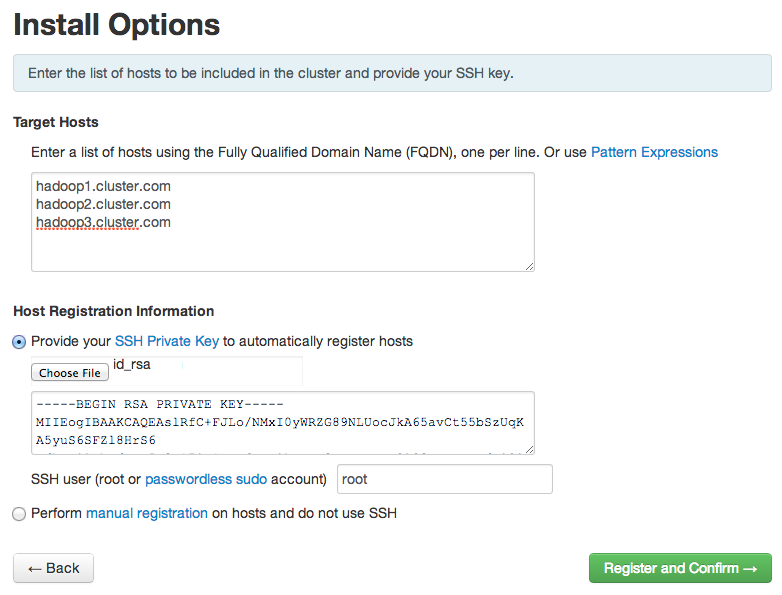
- Specify all Hadoop hosts in the Target Hosts fields. Upload the SSH key that we have generated in the Prerequisites section during passwordless SSH setup and click Register and Confirm:
- This page will confirm that Ambari has located the correct hosts for your Hadoop cluster. Ambri will check those hosts to make sure they have the correct directories, packages, and processes to continue the install. Click Next to proceed.
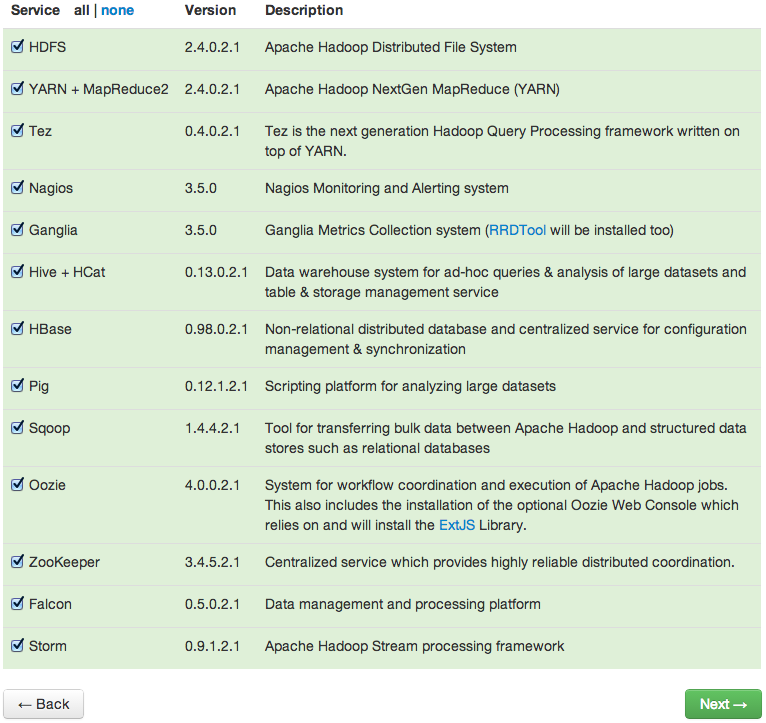
- If you have enough resources, just go ahead and install all services:
- In Assign Master page, we let Ambari choose the configuration for us before clicking Next:
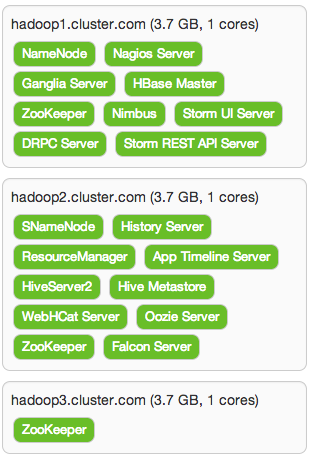
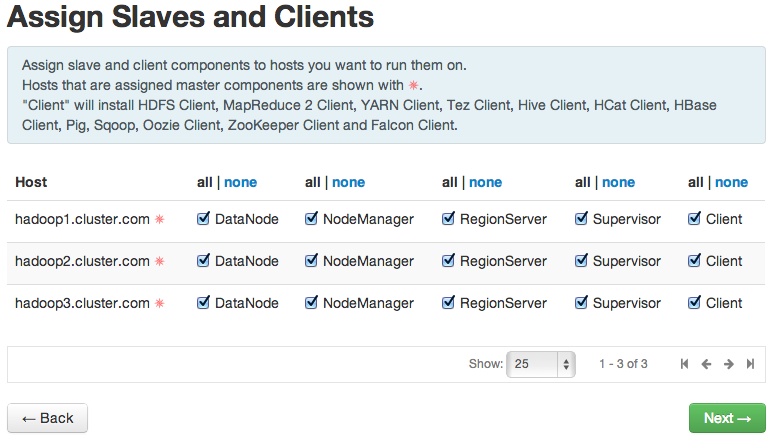
- In Assign Slaves and Clients page, we’ll enable all clients and slaves on each of our Hadoop hosts:
- Hive, Oozie and Nagios might requires further input like database password and administrator email. Specify the needed information accordingly and click Next.
- You will be able to review your configuration selection before clicking Deploy to start the deployment:
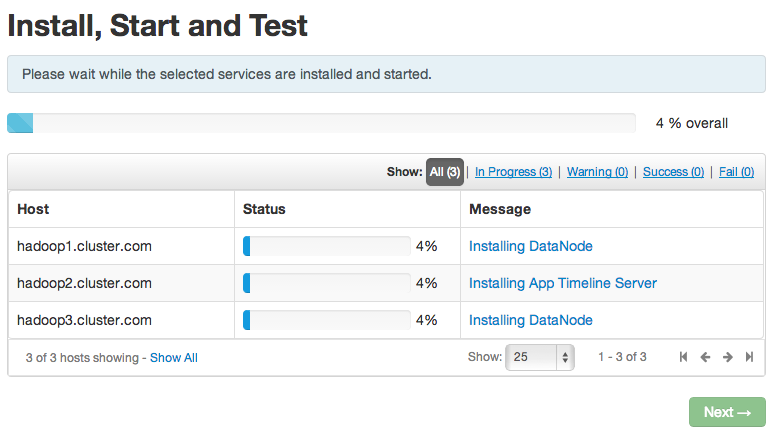
When Successfully installed and started the services appears, choose Next. On the summary page, choose Complete. Hadoop installation and deployment is now complete. Verify that all services are running correctly:
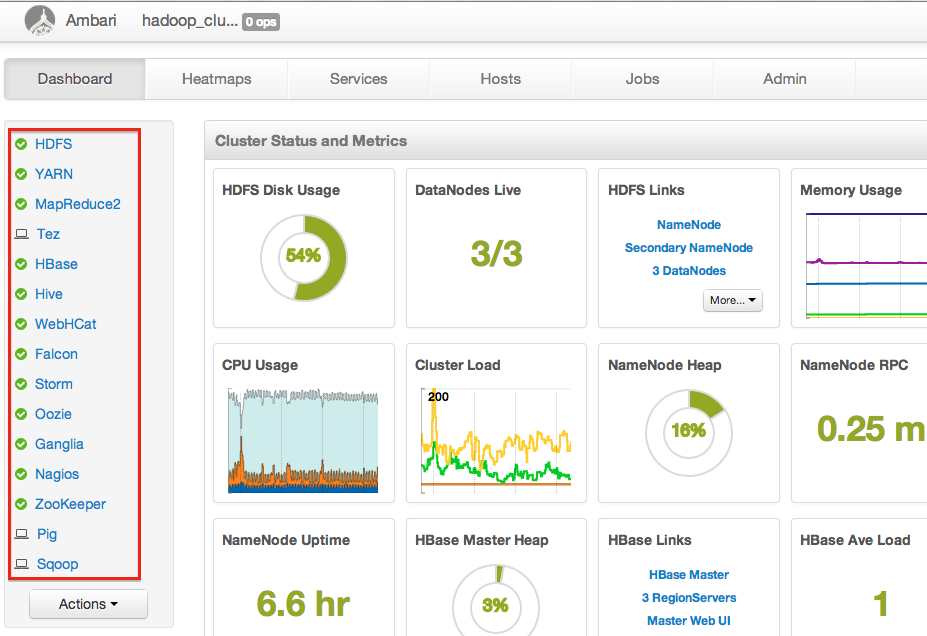
We can now proceed to import some data from our Galera cluster as described in the next section.
Importing MySQL Data using Sqoop to Hive
Before importing any MySQL data, we need to create a target table in Hive. This table will have a similar definition as the source table in MySQL as we are importing all columns at the same time. Here is MySQL’s CREATE TABLE statement:
CREATE TABLE `wp_users` (
`ID` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`user_login` varchar(60) NOT NULL DEFAULT '',
`user_pass` varchar(64) NOT NULL DEFAULT '',
`user_nicename` varchar(50) NOT NULL DEFAULT '',
`user_email` varchar(100) NOT NULL DEFAULT '',
`user_url` varchar(100) NOT NULL DEFAULT '',
`user_registered` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
`user_activation_key` varchar(60) NOT NULL DEFAULT '',
`user_status` int(11) NOT NULL DEFAULT '0',
`display_name` varchar(250) NOT NULL DEFAULT '',
PRIMARY KEY (`ID`),
KEY `user_login_key` (`user_login`),
KEY `user_nicename` (`user_nicename`)
) ENGINE=InnoDB AUTO_INCREMENT=5864 DEFAULT CHARSET=utf8SSH into any Hadoop node (since we installed Hadoop clients on all nodes) and switch to hdfs user:
$ su - hdfsEnter into Hive console:
$ hiveCreate a Hive database and table, similar to our MySQL table (Hive does not support DATETIME data type, so we are going to replace it with TIMESTAMP):
hive> CREATE SCHEMA wordpress;
hive> SHOW DATABASES;
OK
default
wordpress
hive> USE wordpress;
hive> CREATE EXTERNAL TABLE IF NOT EXISTS users (
ID BIGINT,
user_login VARCHAR(60),
user_pass VARCHAR(64),
user_nicename VARCHAR(50),
user_email VARCHAR(100),
user_url VARCHAR(100),
user_registered TIMESTAMP,
user_activation_key VARCHAR(60),
user_status INT,
display_name VARCHAR(250)
);
hive> exit;Now we can start to import the wp_users MySQL table into Hive’s users table, connecting to MySQL nodes through HAproxy (port 33306):
$ sqoop import
--connect jdbc:mysql://192.168.0.100:33306/wordpress
--username=wordpress
--password=password
--table=wp_users
--hive-import
--hive-table=wordpress.users
--target-dir=wp_users_import
--directWe can track the import progress from the Sqoop output:
..
INFO mapreduce.ImportJobBase: Beginning import of wp_users
..
INFO mapreduce.Job: Job job_1400142750135_0020 completed successfully
..
OK
Time taken: 10.035 seconds
Loading data to table wordpress.users
Table wordpress.users stats: [numFiles=5, numRows=0, totalSize=240814, rawDataSize=0]
OK
Time taken: 3.666 secondsYou should see that an HDFS directory wp_users_import has been created (as specified in –target-dir in the Sqoop command) and we can browse its files using the following commands:
$ hdfs dfs -ls
$ hdfs dfs -ls wp_users_import
$ hdfs dfs -cat wp_users_import/part-m-00000 | moreNow let’s check our imported data inside Hive:
$ hive -e 'SELECT * FROM wordpress.users LIMIT 10'
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties
OK
2 admin $P$BzaV8cFzeGpBODLqCmWp3uOtc5dVRb. admin [email protected] 2014-05-15 12:53:12 0 admin
5 SteveJones $P$BciftXXIPbAhaWuO4bFb4LVUN24qay0 SteveJones [email protected] 2014-05-15 12:57:59 0 Steve
8 JanetGarrett $P$BEp8IY1zvvrIdtPzDiU9D/br.FtzFa1 JanetGarrett [email protected] 2014-05-15 12:57:59 0 Janet
11 AnnWalker $P$B1wix5Xn/15o06BWyHa.r/cZ0rwUWQ/ AnnWalker [email protected] 2014-05-15 12:57:59 0 Ann
14 DeborahFields $P$B5PouJkJdfAucdz9p8NaKtS9WoKJu01 DeborahFields [email protected] 2014-05-15 12:57:59 0 Deborah
17 ChristopherMitchell $P$Bi/VWI1W4iP7h9mC0SXd4f.kKWnilH/ ChristopherMitchell [email protected] 2014-05-15 12:57:59 0 Christopher
20 HenryHolmes $P$BrPHv/ZHb7IBYzFpKgauBl/2WPZAC81 HenryHolmes [email protected] 2014-05-15 12:58:00 0 Henry
23 DavidWard $P$BVYg0SFTihdXwDhushveet4n2Eitxp1 DavidWard [email protected] 2014-05-15 12:58:00 0 David
26 WilliamMurray $P$Bc8FmkMadsQZCsW4L5Vo8Xax2ex8we. WilliamMurray [email protected] 2014-05-15 12:58:00 0 William
29 KellyHarris $P$Bc85yvlxvWQ4XxkeAgJRugOqm6S6au. KellyHarris [email protected] 2014-05-15 12:58:00 0 Kelly
Time taken: 16.282 seconds, Fetched: 10 row(s)Nice! Now we can see that our data exists both in Galera and Hadoop. You can also use –query option in Sqoop to filter the data that you want to export to Hadoop using an SQL query. This is a basic example of how we can start to leverage Hadoop for archival and analytics. Welcome to big data!
References
- Sqoop User Guide (v1.4.2) ‒ http://sqoop.apache.org/docs/1.4.2/SqoopUserGuide.html
- Hortonworks Data Platform Documentation ‒ http://docs.hortonworks.com/HDPDocuments/Ambari-1.5.1.0/bk_using_Ambari_book/content/index.html